
【机器学习】微软出品!FLAML:一款可以自动化机器学习过程的神器!
机器学习是我们使用一组算法解决来解决生活中问题的过程。创建机器学习模型很容易,但选择在泛化和性能方面都最适合的模型是一项艰巨的任务。
有多种机器学习算法可用于回归和分类,可根据我们要解决的问题来选择,但选择合适的模型是一个需要高计算成本、时间和精力的过程。
为解决上述问题,今天我给大家分享一款非常棒的工具包:FLAML,它是一个由微软开源的轻量级 Python 库,有助于自动、高效地找出最佳机器学习模型,不仅速度快,节省时间,而且设计轻巧。
让我们详细的介绍一下它吧…
安装所需的库
我们将首先使用 pip 安装来安装 FLAML。下面给出的命令将使用 pip 安装。
pip install flaml
导入所需的库
在这一步中,我们将导入创建机器学习模型和下载数据集所需的所有库。
from flaml import AutoML
解决分类问题
现在我们将从解决分类问题开始。我们将在这里使用的数据是著名的 Iris 数据集,可以从 Seaborn 库轻松加载。让我们开始创建模型。
#Loading the Dataset
from sklearn.datasets import load_iris
为 Automl 创建实例很重要,同时也定义 Automl 设置,因此在这一步中,我们还将创建 Automl 实例并定义设置。
automl = AutoML()
automl_settings = {
"time_budget": 10, # in seconds
"metric": 'accuracy',
"task": 'classification'
}
接下来,我们将拆分数据并将其拟合到模型中。最后,我们还将使用模型进行预测并找到最佳模型。
X_train, y_train = load_iris(return_X_y=True)
# Train with labeled input data
automl.fit(X_train=X_train, y_train=y_train,
**automl_settings)
print(automl.predict_proba(X_train).shape)
# Export the best model
print(automl.model)

在这里,我们可以清楚地看到 ExtraTreeEstimator 是此数据的最佳模型。现在让我们打印模型的最佳超参数和准确性。
print('Best ML leaner:', automl.best_estimator)
print('Best hyperparmeter config:', automl.best_config)
print('Best accuracy on validation data: {0:.4g}'.format(1-automl.best_loss))
print('Training duration of best run: {0:.4g} s'.format(automl.best_config_train_time))
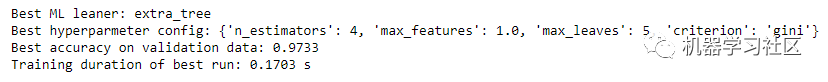 同样,对于回归问题,我们也将遵循相同的过程。
同样,对于回归问题,我们也将遵循相同的过程。
解决回归问题
现在将解决一个回归问题。我们将在这里使用的数据是著名的波士顿数据集,可以从 Seaborn 库轻松加载。我们可以遵循与分类问题完全相同的过程。
from sklearn.datasets import load_boston
automl = AutoML()
automl_settings = {
"time_budget": 10, # in seconds
"metric": 'r2',
"task": 'regression'
}
X_train, y_train = load_boston(return_X_y=True)
# Train with labeled input data
automl.fit(X_train=X_train, y_train=y_train,
**automl_settings)
# Predict
print(automl.predict(X_train).shape)
# Export the best model
print(automl.model)

print('Best ML leaner:', automl.best_estimator)
print('Best hyperparmeter config:', automl.best_config)
print('Best accuracy on validation data: {0:.4g}'.format(1-automl.best_loss))
print('Training duration of best run: {0:.4g} s'.format(automl.best_config_train_time))

在这里,我们也可以清楚地看到回归问题的最佳模型和超参数。同样,你可以对你关注的数据集执行此过程,并找到最佳模型和超参数。
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
量化: 定投基金到底能赚多少钱? | 我用Python对去年800只基金的数据分析
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|

年度爆款文案
点阅读原文,看Python全套!
