
AAAI 2021 | 首字母缩写词消歧挑战赛冠军技术分享

新智元推荐
新智元推荐
编辑:SF
2月2-9日,AAAI 2021于线上隆重召开。AAAI(美国人工智能协会)作为人工智能领域的主要学术组织之一,其主办的年会被列为国际人工智能领域的 A 类顶级会议。来自中国的DeepBlueAI团队首次参加AAAI挑战赛,便在Acronym Disambiguation(首字母缩写词消歧)赛道中与阿里巴巴等知名机构同台竞技,并获得冠军。

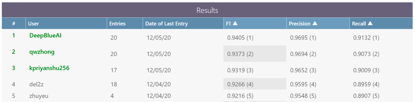
团队成绩
任务介绍
首字母缩写在许多英文文献和文档中,特别是在科学和医疗领域十分常见。通过使用首字母缩写词,人们可以避免重复使用较长的短语。
例如,“CNN”的全称可以是“Convolutional Neural Network”,不过某些情况下它也可以是“Condensed Nearest Neighbor”的缩写。
了解首字母缩写及其全称之间的对应关系在自然语言处理的许多任务中至关重要,如文本分类、问答系统等。
尽管使用首字母缩写词能够便利人们的书写交流,但是一个缩写词往往对应有多个全称,在一些情况下,如科学或医疗领域中,一些专业名词的缩写可能会使得对该领域不熟悉的人在理解文意时产生一些歧义。
因此,如何利用计算机技术协助人们理解不同语境下缩写词的正确含义是值得探讨的问题。首字母缩写词消歧任务由此而生,该任务是当给定一个首字母缩写词以及该词对应的几个可能的全称时,根据上下文的文意,确定在当前语境中最合适的全称。
示例如图1所示,图中给定了一个有语境的句子,句子中包含了一个首字母缩写词“SVM”,同时也提供了全称词典,即该缩写词对应的几种全称,分别为“Support Vector Machine”和“State Vector Machine”。
根据句意,此处输出的SVM全称为“Support Vector Machine”。

图1 首字母缩写词消歧任务示例
数据分析
针对首字母缩写词消歧任务,我们选用的数据集为SciAD[1]。这个数据集的标注语料为6786篇arXiv网站上的英文论文,共包含2031592个句子,句子平均长度为30个词。该数据集的构建过程分为两个部分。
第一部分是首字母缩写词对应全称词典的构建,对于每一个在数据集中出现的首字母缩写词,统计并整理其全称,最终全称词典包含732个首字母缩写词,其中每个首字母缩写词平均包含3个全称。
第二部分是标注样本的构建,每一个样本包含一个带有首字母缩写词的句子,以及该词在句子中的正确全称。标注样本共62441条。
图2展示了每一个句子中包含缩写词个数的分布,分析图2可得每一个句子中可以包含多个缩写词,大多数句子包含1个或者2个缩写词。
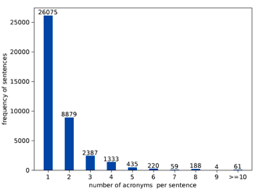
图2 一个句子中包含的首字母缩写词个数
图3展示了每个缩写词对应的全称个数,由图可得,每个缩写词对应包含2个或3个全称。
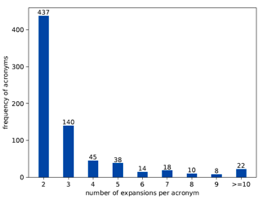
图3 每个首字母缩写词对应的全称个数
模型介绍
模型概述
本工作在利用预训练模型BERT[2]的基础上,融合了多种训练策略,提出一种基于二分类思想的模型来解决首字母缩写词消歧问题。
模型输入输出示例如图4所示:给定包含首字母缩写词“MSE”的句子,将该句子结合“MSE”不同的缩写词全称作为候选输入BERT中,BERT为对一个候选进行预测,预测值最高的即为当前句子中缩写词对应的全称。
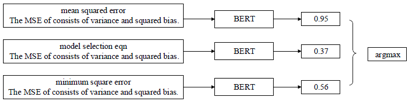
图4 模型输入输出示例
模型输入设定
BERT可以使用句段嵌入处理多个输入语句,本工作将缩写词对应的候选全称作为第一个输入句段,将给定的句子作为第二个输入句段,第一个句段的开头用特殊符[CLS]标记,两个句段的间隔用特殊符[SEP]标记。
此外,另添加了两个特殊标记
模型结构
本工作模型为一个基于BERT的二分类器,具体模型结构如图5所示。
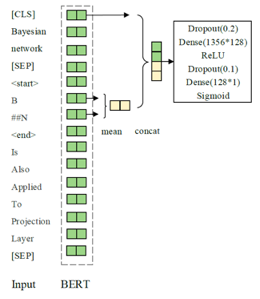
图5 基于BERT的二分类模型
首先,根据3.1节中介绍的输入设定,将处理好的数据输入BERT来获取每个token对应的嵌入表示。其次,计算首字母缩写词开始和结束位置的嵌入表示平均值,并将此平均值与句子开头的[CLS]位置向量拼接。
之后,将拼接得到的向量输入通过一个dropout层,一个前向传播层后,通过激活函数ReLU后再输入一个dropout层,一个前向传播层,最后通过激活函数Sigmoid得到一个在(0,1)区间的预测值。
该值表示了此全称为该缩写词在当前句子中正确全称的可能性。
训练策略
在上述二分类模型的基础上,本工作融合了多种训练策略来提升最终的模型效果。
预训练模型的选取
基于BERT的后续相关预训练模型层出不穷,它们利用了不同的训练方式或不同的训练语料。针对本任务,由于数据集SciAD的语料均为科学领域的论文,而语料的一致性对于模型性能至关重要,所以本工作在做了相应的实验验证后选取了在114万篇科技论文语料上训练的SCIBERT[3]作为基础预训练模型。
动态负采样
在训练过程中,为了确保模型能够在更平衡的样本上进行训练,本工作在训练过程中,对于每一批次(batch)输入模型的数据进行动态负采样,通过动态选择固定数目的负样本,保证了分类中负样本在训练中的作用,有效提高了负样本的贡献率,同时也有效提升了模型性能。
任务自适应预训练
任务自适应训练(task-adaptive pretrainin)[4]是指在第一阶段通用预训练模型的基础上,利用任务相关文本继续训练,该训练方式可以有效地提升模型性能。
针对特定任务的数据集通常是通用预训练数据的子集,因此本工作在给定的SciAD数据集上利用掩码语言模型(Mask Language Model)的方式进行继续训练以此得到新的预训练模型。
对抗训练
对抗训练是一种引入噪声的训练方式,可以对参数进行正则化,从而提升模型的鲁棒性和泛化能力。本工作采用FGM(Fast Gradient Method)[5],通过在嵌入层加入扰动,从而获得更稳定的单词表示形式和更通用的模型,以此提升模型效果。
伪标签
伪标签学习也可以称为简单自训练(Simple Self-training)[6],即用有标签的数据训练一个分类器,然后利用此分类器对无标签测试数据进行分类,获取了无标签测试数据的伪标签,并将获取到的预测值大于0.95的伪标签数据与之前的训练集混合作为新的训练集来训练新的模型,以此提升模型效果。
训练流程
我们提出了基于BERT的二分类模型融合了多种训练策略来提升模型效果,具体训练流程如下图6所示。首先,选用SCIBERT作为基础预训练模型,然后利用任务自适应预训练方式得到新的预训练模型。
在此模型上利用动态负采样技术和对抗训练的方式按照3.3节中的方式训练得到二分类模型,利用该分类模型对未标注的数据集进行伪标签判断得到新的可以加入训练的数据,产生新的训练集,在新的训练集上重复上述训练过程得到最终的二分类模型。
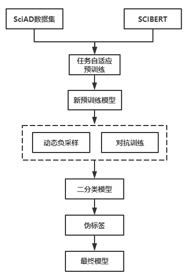
图6 训练流程
实验
实验中部分参数设置如下,batch size为32,模型训练epochs为 15,当连续3个epoch F1下降将会提前停止,BERT的初始学习率为1.0×10-5,其他参数初始学习率设置为5.0×10-4。在所有实验中都使用Adam[7]优化器。
由于不同的预训练模型效果不一样为了选择比较好的模型,我们在几种预训练模型上进行了实验。表1显示了我们在验证集中不同预训练模型上的实验结果。基于scibert的模型在常用的预训练模型中f1最好。
模型 | Precision | Recall | F1 |
bert-base-uncased | 0.9176 | 0.8160 | 0.8638 |
bert-large-uncased | 0.9034 | 0.7693 | 0.8331 |
roberta-base | 0.9008 | 0.7687 | 0.8295 |
cs-roberta-base | 0.9216 | 0.8415 | 0.8797 |
scibert-scivocab-uncased | 0.9263 | 0.8569 | 0.8902 |
表1 不同预训练模型效果表
由于scibert比其他的模型有着较大的提升,我们选取scibert作为我们的基础模型,加上各种训练策略的在验证集上实验结果如表2所示。如表所示,动态负采样,F1分数提高了4%,提升效果比较明显。
TAPT和对抗性训练进一步将验证集的性能提高了0.47%。而伪标签在验证集提升不大,但是在测试集上提交伪标签效果在1-2个千分位左右。
模型 | Precision | Recall | F1 |
scibert-scivocab-uncased | 0.9263 | 0.8569 | 0.8902 |
+dynamic sampling | 0.9575 | 0.9060 | 0.9310 |
+task adaptive pretraining | 0.9610 | 0.9055 | 0.9324 |
+adversarial training | 0.9651 | 0.9082 | 0.9358 |
+pseudo-labeling | 0.9629 | 0.9106 | 0.9360 |
表2 加上各种训练策略的效果表
在验证集集上的结果为单模型的结果,在测试集上我们选择的交叉验证实验方式,并采用概率平均的方式进行模型融合,在最终的测试集上F1达到了0.9405。
总结
经过实验发现预训练模型的选择对最后的效果有着巨大的影响,正如论文Don’t stop pretraining: Adapt language models to domains and tasks得出的结论,采用当前领域内的预训练模型会比通用的预训练模型要有很大的提升,而任务自适应预训练也有着一定的提升,是比赛中提分的关键。
团队负责人介绍
罗志鹏,DeepBlue Technology集团技术副总裁,毕业于北京大学,曾任职于微软亚太研发集团。现主要负责公司AI平台相关研发工作,带领团队已在CVPR、ICCV、ECCV、KDD、NeurIPS、SIGIR等数十个世界顶级会议挑战赛中获得近三十项冠军,以一作在KDD、WWW等国际顶会上发表论文,具有多年跨领域的人工智能研究和实战经验。
参考文献
