
我裂开了...人类脑海中的画面,被AI解码了??

大数据文摘授权转载自夕小瑶的卖萌屋
作者:白鹡鸰

Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding
论文链接:
http://arxiv.org/abs/2211.06956
代码链接:
https://github.com/zjc062/mind-vis
背景
方法
基于fMRI收集的脑电数据
作为1991年的Nature封面,fMRI得到了广泛研究,目前采集数据的技术已经相当成熟。但这一块的原理非常复杂,感兴趣的话可以搜索血氧依赖机理,blood-oxygen-level-dependent, BOLD。
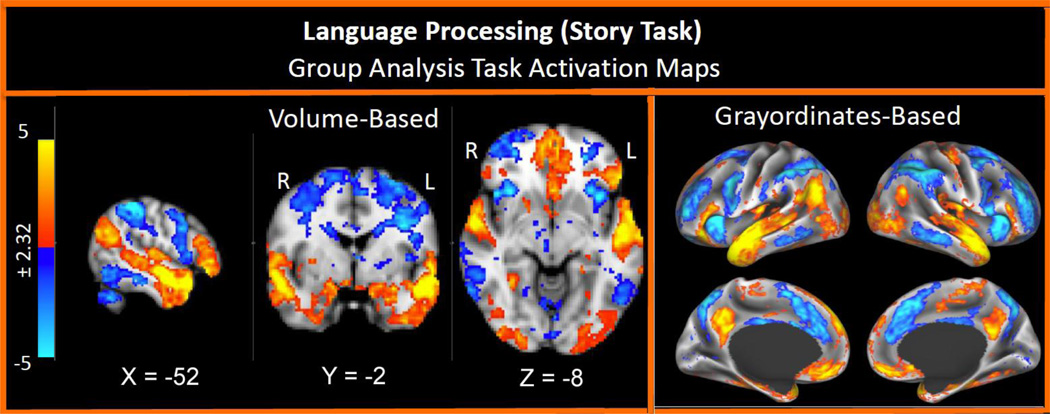
fMRI扫描所得到的数据是以三维形式的体素 (voxel)记录的,每个数据点包括了三维坐标,电信号幅度等信息,维度很高。为了避免对体素直接进行运算,一般采用的方法是划兴趣区域 (Region of Interest, ROI),对电信号求时序上的均值,最终获得一列体素,这样的数据在纬度方面和通常处理的图像数据存在相当的差距; 邻近的体素往往电信号幅度相近,fMRI收集的信息中存在一定冗余; 因为人脑的复杂性,每个个体的数据都会存在一定的域偏移。

模型结构
conditional synthesis是指限定某些特征后进行数据生成。例如,生成微笑的不同人脸。
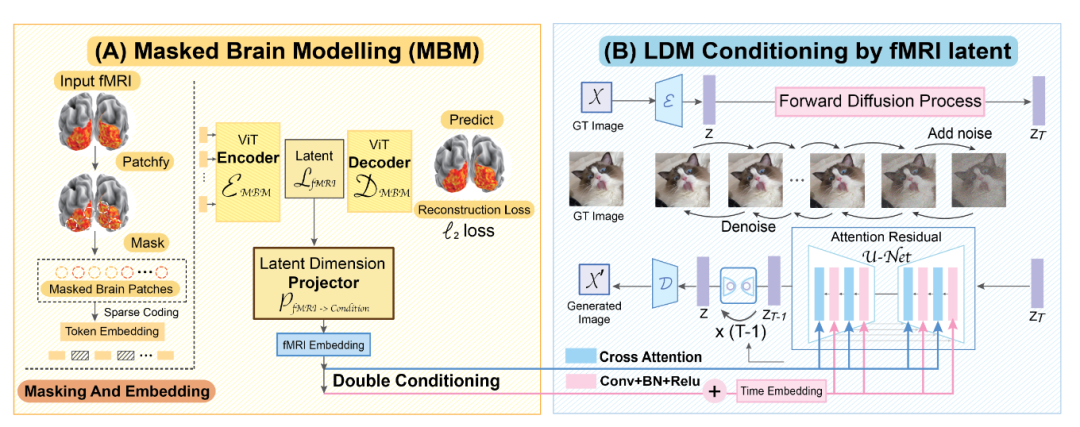
由于模型的结构较为复杂,当前版本的论文中没有进行更为详细的描述,推荐极度好奇的读者直接看开源代码。由于涉及了像Masked Brain Modeling,Diffusion Model这类前沿方法,在没有一定基础的情况下,想彻底吃透方法会需要相当的时间和精力,大家可以量力而行。
效果
由于fMRI的数据主要面向神经科学方向的研究,满足论文任务的数据量不大,模型的训练、验证、测试数据总共来自三个不同的数据集,不同集合的数据域都有所偏移。Human Connectome Project [1] 提供136,000个fMRI数据片段,没有图像,只有fMRI,主要是用来预训练模型的解码部分。Generic Object Decoding Dataset (GOD) [3] 是主要面向fMRI-图像任务的,包含1250张来自200个类别的图像,其中50张被用于测试。Brain, Object, Landscape Dataset (BOLD5000) [4] 则选取了113组fMRI-图像数据对,作为测试。


尾声
[1] David C Van Essen, Stephen M Smith, Deanna M Barch, Timothy EJ Behrens, Essa Yacoub, Kamil Ugurbil, Wu-Minn HCP Consortium, et al. The wu-minn human connectome project: an overview. Neuroimage, 80:62–79, 2013.
[2] He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[3] Tomoyasu Horikawa and Yukiyasu Kamitani. Generic decoding of seen and imagined objects using hierarchical visual features. Nature communications, 8(1):1–15, 2017.
[4] Nadine Chang, John A Pyles, Austin Marcus, Abhinav Gupta, Michael J Tarr, and Elissa M Aminoff. Bold5000, a public fmri dataset while viewing 5000 visual images. Scientific data, 6(1):1–18, 2019.
评论