
最近,又发现了Pandas中三个好用的函数
导读
笔者早先学习Python以及数据分析相关知识时,对Pandas投入了很多精力,自认掌握的还算扎实,期间也总结分享了很多Pandas相关技巧和心得(点击上方“Pandas”标签可以查看系列文章)。近日,在github中查看一些他人提交的代码时,发现了Pandas中这三个函数,在特定场景中着实好用,遂成此文以作分享。

程序的基本结构大体包含三种,即顺序结构、分支结构和循环结构,其中循环结构应该是最能体现重复执行相同动作的代码控制语句,因此也是最必不可少的一种语法(当然,顺序和分支也都是必不可少的- -!)。虽然Pandas中提供了很多向量化操作,可以很大程度上避免暴力循环结构带来的效率低下,但也不得不承认仍有很多情况还是循环来的简洁实在。
因此,为了在Pandas中更好的使用循环语句,本文重点介绍以下三个函数:
iteritems
iterrows
itertuples




iteritems的更多文档部分可自行查看
笔者猜测,可能是在早期items确实以列表形式返回,而后来优化升级为以迭代器形式返回了。不过在pandas文档中简单查阅,并未找到相关描述。
那么,说了这么多,iteritems到底有什么用呢?我个人总结为如下几个方面:
方便的以(columnName, Series)元组对的形式逐一遍历各行进行相应操作
以迭代器的形式返回,在DataFrame数据量较大时内存占用更为高效
另外,items是iteritems的同名函数,二者在功能上目前已无差别
在前面介绍了iteritems的基础上,这里介绍iterrows就更加简单了。如果说iteritems是对各列进行遍历并以迭代器返回键值对,那么iterrows则是对各行进行遍历,并逐行返回(行索引,行)的信息。


这里仍然显式转化为list输出

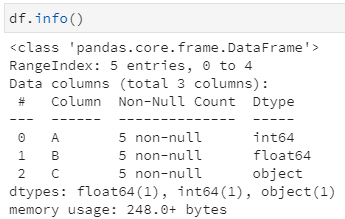
示例DataFrame的各列信息
那么,如果想要保留DataFrame中各列的原始数据类型时,该如何处理呢?这就需要下面的itertuples。
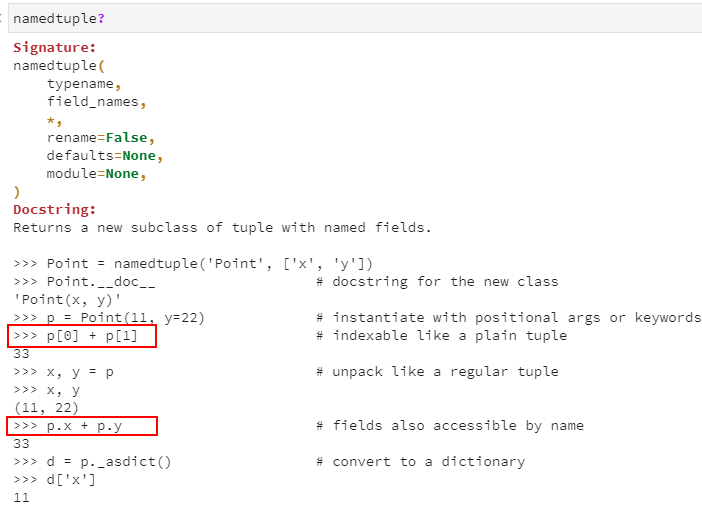
实际上,namedtuple是一个继承自tuple的子类,区别在于namedtuple除了可以使用索引来访问各元素取值外,还支持以各位置的'name'来访问元素(类似于C语言中的结构体类型),或者说namedtuple可以很方便的无缝转换为dict。
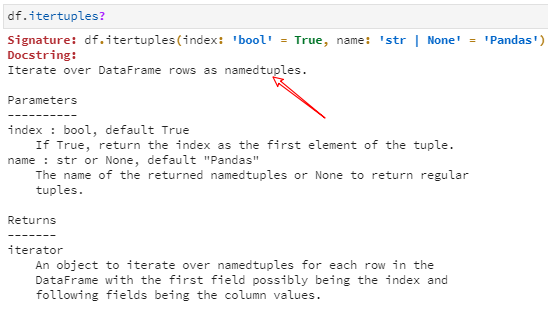
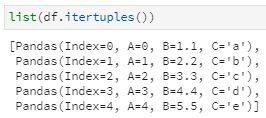
其中,返回值包含5个namedtuple,这里每个namedtuple都被命名为Pandas,这可以通过itertuples中的name参数加以修改;另外,注意到在每个namedtuple都包含了4个元素,除了A、B、C三个列取值外,还以index的形式返回了行索引信息,这可以通过itertuples中的index参数设置保留或舍弃。
由于行索引作为namedtuple中可选的一部分信息,所以与iteritems和iterrows不同,这里的返回值不再以元组队的形式显示行索引信息。
以上就是本文分享的Pandas中三个好用的函数,其使用方法大体相同,并均以迭代器的形式返回遍历结果,这对数据量较大时是尤为友好和内存高效的设计。对于具体功能而言:
iteritems是面向列的迭代设计,items函数的功能目前与其相同;
iterrows和itertuples都是面向行的迭代设计,其中iterrows以元组对的形式返回,但返回的各行Series可能无法保留原始数据结构类型;而itertuples则以namedtuple形式返回各行信息,行索引不再单独显示而是作为namedtuple中的一项,并可通过itertuples参数加以设置是否保留。
相关阅读: