
从EfficientNet与RegNet出发,深入探讨CNN网络设计:Handcraft VS NAS

极市导读
本文介绍了CNN的基本设计框架,并着重讲解EfficientNet与RegNet这两种经典架构,分享了关于CNN网络设计与调整的观点。>>国庆长假,回复“炼丹师”参与炼丹师测评,即可领取CV电子书大礼包~

本篇文章讨论 convolutional neural network的设计方法,从特征图宽度、分辨率与深度意义与 scaling开始,再从介绍 NAS (EfficientNet)与 handcraft的设计过程 (RegNet),最后讨论两者之间的关系。这篇文章主要重点在于网络架构设计的讨论,不单单是 EfficientNet或 RegNet的介绍。
推荐背景知识:convolutional neural network (CNN)、neural architecture search (NAS)、EfficientNet、RegNet。
1 CNN基本设计框架
convolution layer抽取spacial information; pooling layer降低图像或特征图分辨率,减少运算量并获得semantic information; fully-connected (FC) layer回归目标。
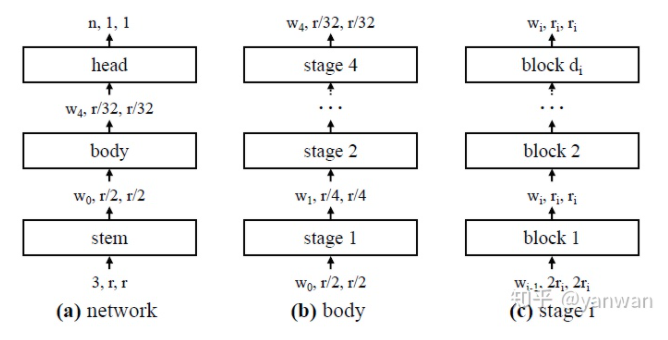
除了上述以外,设计 convolutional neural network当然还有许多可以调整的细节:shortcut的设计 (如 FPN [4])、receptive field的调配等等。不过为了比免冗长繁杂、不在这篇文章讨论。
2 Scale An Existed Structure
3 单独强化其一
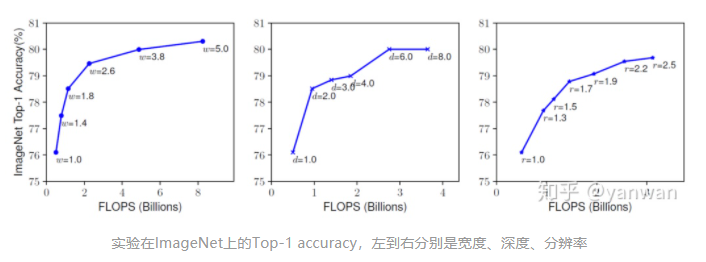

4 Neural Architecture Search (NAS)
这篇文章不谈论 search strategy,关注放在与网络设计有关的 search space与 performance estimation。
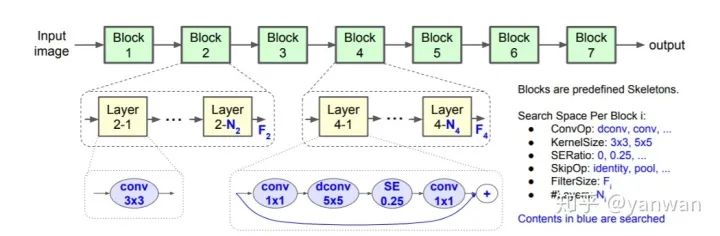
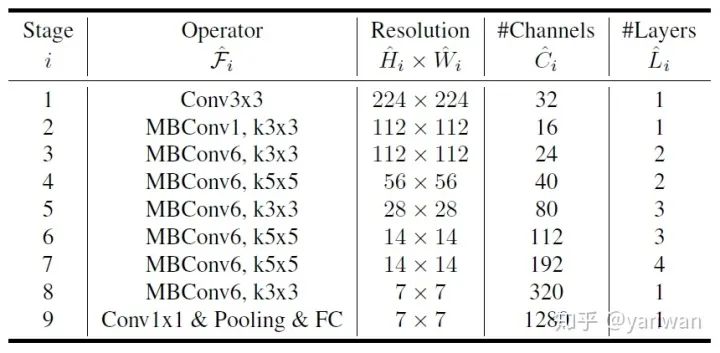
5 Handcraft Design with Insights
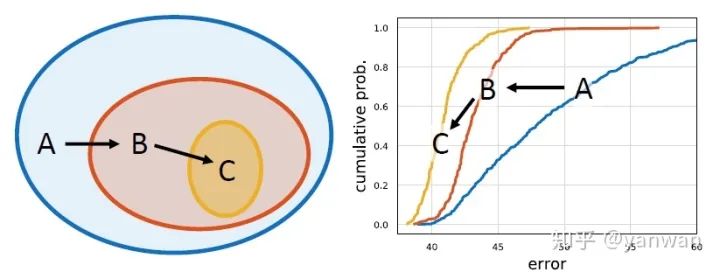
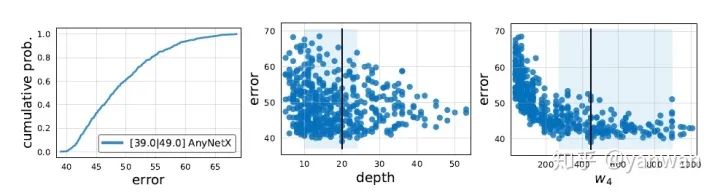
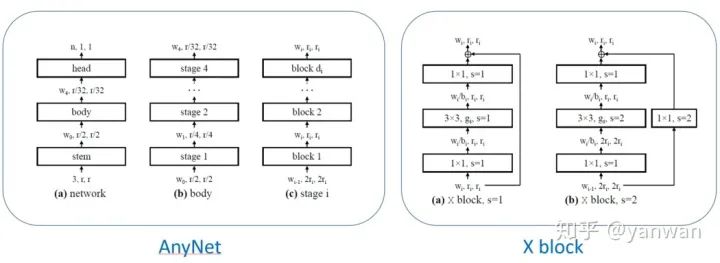
宽度增加的区间倍率 (width multiplier) 与网络宽度增加的目标斜率 (width slope) 听起来有够拗口,其实是我自己以意义来翻译。因为即使看原文也容易摸不着头绪,实际意义大概是这样:目标斜率是一个固定的数值定义每个 block的宽度要如何增长,而区间倍率则是一个方便取整数的倍率,可以操作让每个 block 的宽度不要跳的那麽乱,也可以在每个 stage内将重複的 block 设计为一样的宽度。
6 Handcraft vs NAS
“Any fool can know. The point is to understand.” ― Albert Einstein
[2] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. [arXiv 2017]
[3] MobileNetV2: Inverted Residuals and Linear Bottlenecks [CVPR 2018]
[4] Feature Pyramid Networks for Object Detection [CVPR 2017]
[5] Batch normalization: Accelerating deep network training by reducing internal covariate shift. [ICMC 2015]
[6] Wide residual networks. [BMVC 2016]
[7] EfficientDet: Scalable and Efficient Object Detection [ICML 2019]
[8] MnasNet: Platform-aware neural architecture search for mobile [CVPR 2019]
[9] Designing Network Design Spaces [CVPR 2020]
[10] EfficientDet: Scalable and Efficient Object Detection [ECCV 2020]
[11] Squeeze-and-Excitation Networks [CVPR 2018]
推荐阅读

评论