
NAS or 手工设计网络?RegNet这样说
【GiantPandaCV导语】这篇论文是FAIR的Ilija Radosavovic组(并不是何恺明)做的一个NAS工作。传统的NAS是固定网络设计空间,搜索参数到最好的模型。「而该工作是结合了部分手工设计和网络搜索,得到最优的网络设计空间」,再一步步缩小,「得到一组最优模型。」
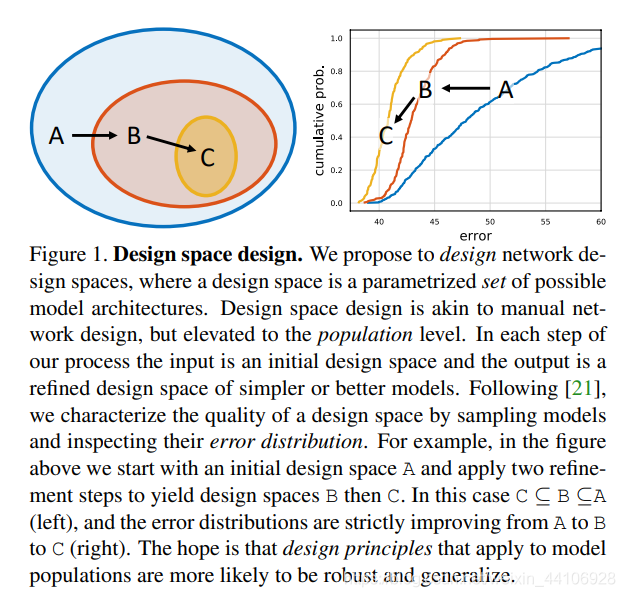
概述
这篇工作我们提出了一个网络设计的新范式,我们并不像传统NAS关注设计一个最优网络实例,而是去「关注网络的设计空间」。「使用我们的方法可以一步步缩小设计空间至包含一组简单,常规,优秀的网络结构」,我们称其为RegNet(Reg是指Regular)。
而RegNet的网络参数化思想也十分简单,即「优秀网络的宽度(width)和深度(depth)可以用一个量化线性函数来解释。」
最终我们得到了一组表现比EfficientNet优秀的网络模型,并且在GPU运行上快五倍。
设计网络设计空间
传统在单个模型上进行超参数搜索,「需要为特定场景而进行相关调整」。
而我们的想法是在初始不受限的空间下进行搜索,直到搜索到一个良好的网络设计空间,它才会「更有可能推广到一个具有普适性的网络设计原则」
「然而在这种庞大的设计空间下,对模型性能评价显然是一个问题」。
我们采取了Radosavovic等人的思想,我们可以在设计空间内,「对模型进行采样,产生一个模型分布」,并采用传统统计学的方法对设计空间进行评价。为了效率,我们在每个设计空间,采样n个模型,只在 ImageNet 数据集下训练 10个 Epoch。
「然后我们使用统计学的工具,经验分布函数(EDF),用于评估模型的误差,以及网络空间的设计质量。」
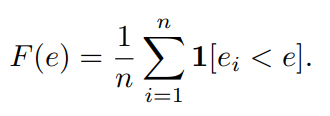
从 AnyNet 开始
我们首先设计了一个 AnyNet,它包含三个部分
Stem 一个简单的网络输入头
body 网络中主要的运算量都在这里
head 用于预测分类的输出头
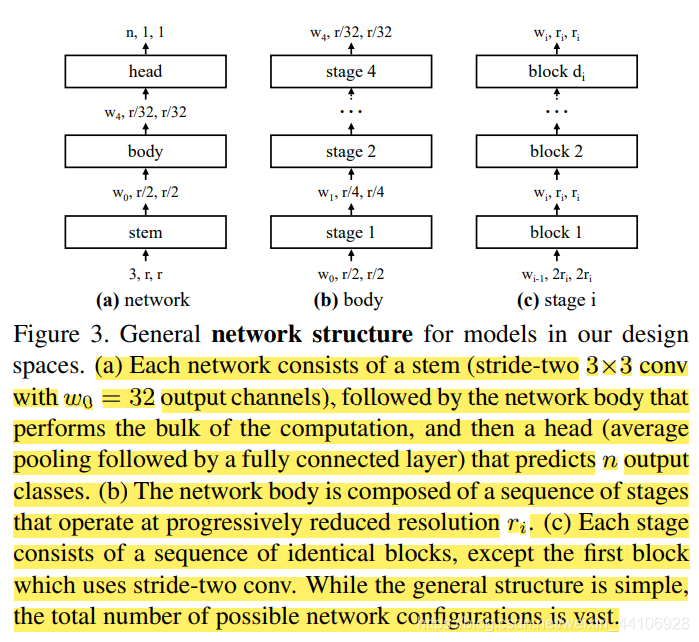
模型网络结构设计 我们「将stem和head固定下来,并专注于网络body设计」。因为body部分的参数量最多,运算量也多,这部分是决定网络准确性的关键
而Body结构,通常包含4个stage,每个stage都会进行「降采样」。而1个「stage是由多个block进行堆叠得到的」。
论文中,我们的Block采取的是「带有组卷积的残差BottleNeck Block」(即ResNext里的结构),我们称在这样Block限制条件下的搜索空间为 AnyNetX
,Block的结构如下: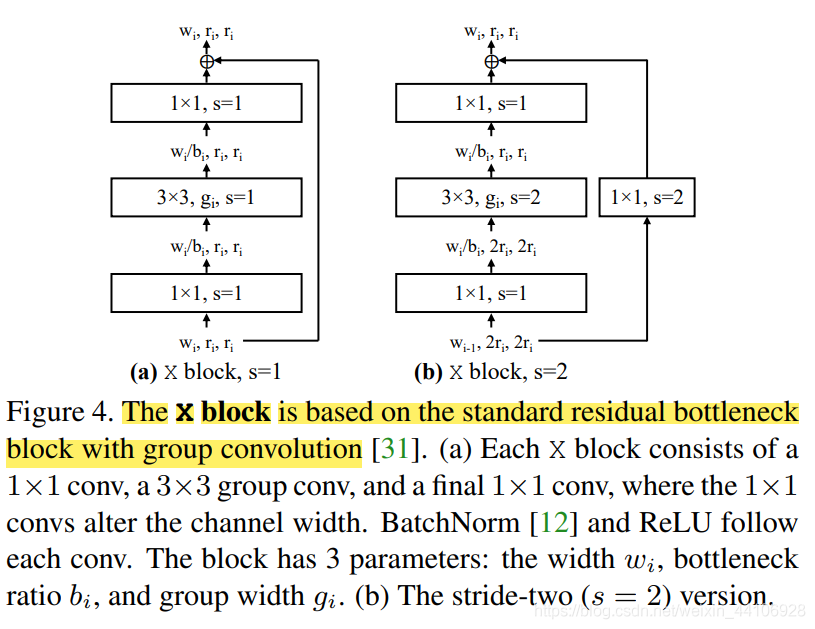 此时 AnyNetX 中有「16个自由度可以设计,包含了4个stage,每个stage有4个Block参数:」
此时 AnyNetX 中有「16个自由度可以设计,包含了4个stage,每个stage有4个Block参数:」
block的数目 di block的宽度 wi Bottleneck的通道缩放比例 bi 分组数目 gi
此时我们在这样的条件下进行采样,缩小网络设计空间:
di ≤ 16 wi ≤ 1024 (其中wi可被8整除) bi ∈ {1, 2, 4} gi ∈ {1, 2, . . . , 32}
因此我们在 AnyNetX 衍生出其他搜索空间
AnyNetXa 就是原始的 AnyNetX
AnyNetXb 在 AnyNetX 基础上,「每个stage使用相同的Bottleneck缩放比例bi」。并且实验得出缩放比例 bi <= 2 时最佳,参考下图最右边子图

对AnyNetXb和AnyNetXc的分析 AnyNetXc 在 AnyNetXb 的基础上「共享相同的分组数目gi」。由上图的左图和中间图可得知,从 A->C 的阶段,EDF并没有受到影响,而我们此时已经减少了
AnyNetXd 在 AnyNetXc 的基础上「逐步增加Block的宽度wi」。此时网络性能有明显提升!
AnyNetXd
AnyNetXe 在 AnyNetXd 的基础上在除了最后一个stage上,「逐步增加Block的数量(深度)di」。网络性能略微有提升 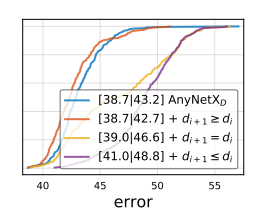
RegNet 设计空间
我们绘制了在 AnyNetXe 空间上最好的20个模型,并尝试进行线性回归
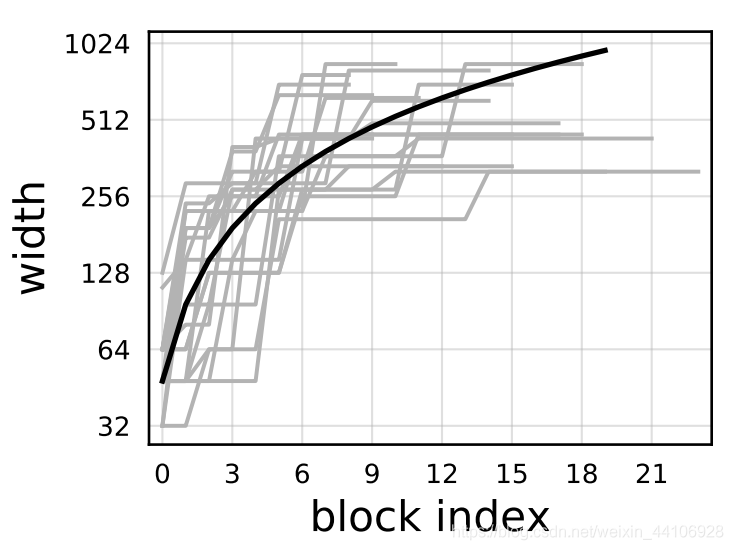
但是我们的「Block宽度都是离散数值,所以我们需要在此基础上进行量化」,下面是具体量化过程:
首先我们设计一个线性函数:
其中是初始宽度,是斜率
为了量化,我们引入一个值大于0的额外参数,注意这个参数是我们自己设计的。
公式有:
令「其与前面的式子1相等,我们就能求解得到」
为了对量化,我们对进行「四舍五入」。
这样我们就得到了每个Block的宽度
量化完后,「我们就得到了 RegNet 搜索空间」

可以看到 RegNet 最后是一组设计空间,而不是像ResNeSt,EfficientNet这种固定的网络结构。论文后面还有很多拓展实验,包括RegNetX增加SE模块的测试,限于篇幅这里就不展开了,有兴趣的读者可以读一读。
准确率比较
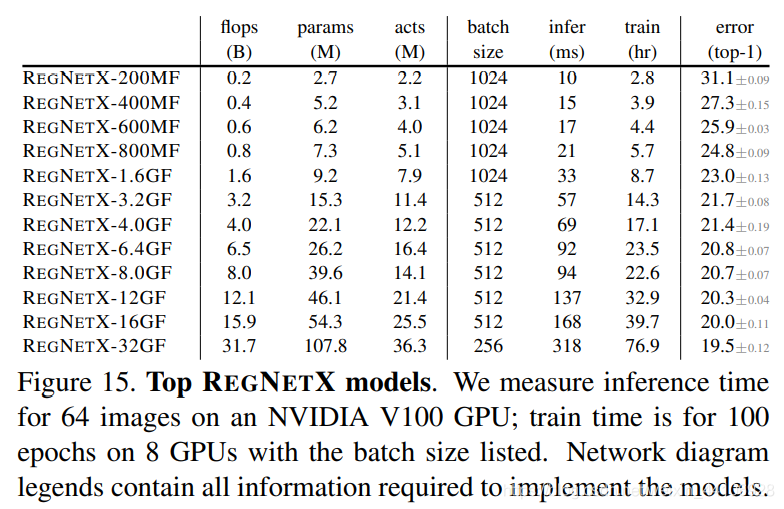
上图是 RegNetX 模型的准确率比较
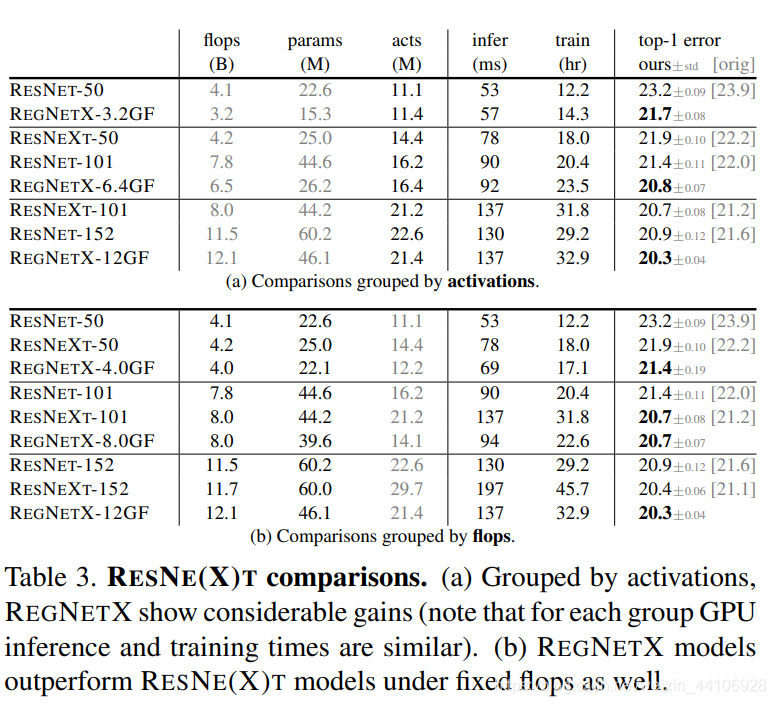
上图是与 Resnet 和 Resnext 对比,还是能明显看到 RegNetX 的参数量较少,同时准确率更高。
注意这里并没有用到「很多奇奇怪怪的swish激活函数,数据扩增,注意力模块等结构」。
总结
亚马逊的张航博士已经开源了一版 RegNet 的代码,如果有能力可以去试着在自己的模型搜索下,代码地址:RegNet
另外知乎也有几个回答,大家可以参考下如何评价FAIR团队最新推出的RegNet?
我个人感觉这篇工作除了训练Epoch只有10轮以外,其他地方还是很有说服力的。「没有用数据增广,注意力模块,激活函数的组合排列」。而是「放眼于一个设计空间」,从最朴素的模型,类似resnet的结构开始出发,一步步进行限制,量化,搜出一个“吊打” EfficientNet 的模型。相较于其他的网络,这篇工作还是比较贴近实际应用的,没有太多炼丹技巧,就以最朴素的模型,做到了SOTA,推荐大家尝试。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。