
【数据竞赛】Kaggle时序建模案例:预测水资源可用性
Acea Smart Water Analytics
您能否预测水资源未来的的可用性?
每个数据集代表一种不同类型的水体。由于每个水体彼此不同,相关特征也不同。我们会注意到它的特征与湖泊的特征不同。这些差异是根据每个水体的独特行为和特征预期的。
步骤1:数据集读取
首先读取数据,并找到对应的日期列,
from datetime import datetime, date
df['date'] = pd.to_datetime(df['date'], format = '%d/%m/%Y')
其中特征列为Rainfall、Temperature、Volume和Hydrometry,标签列为Depth to Groundwater。
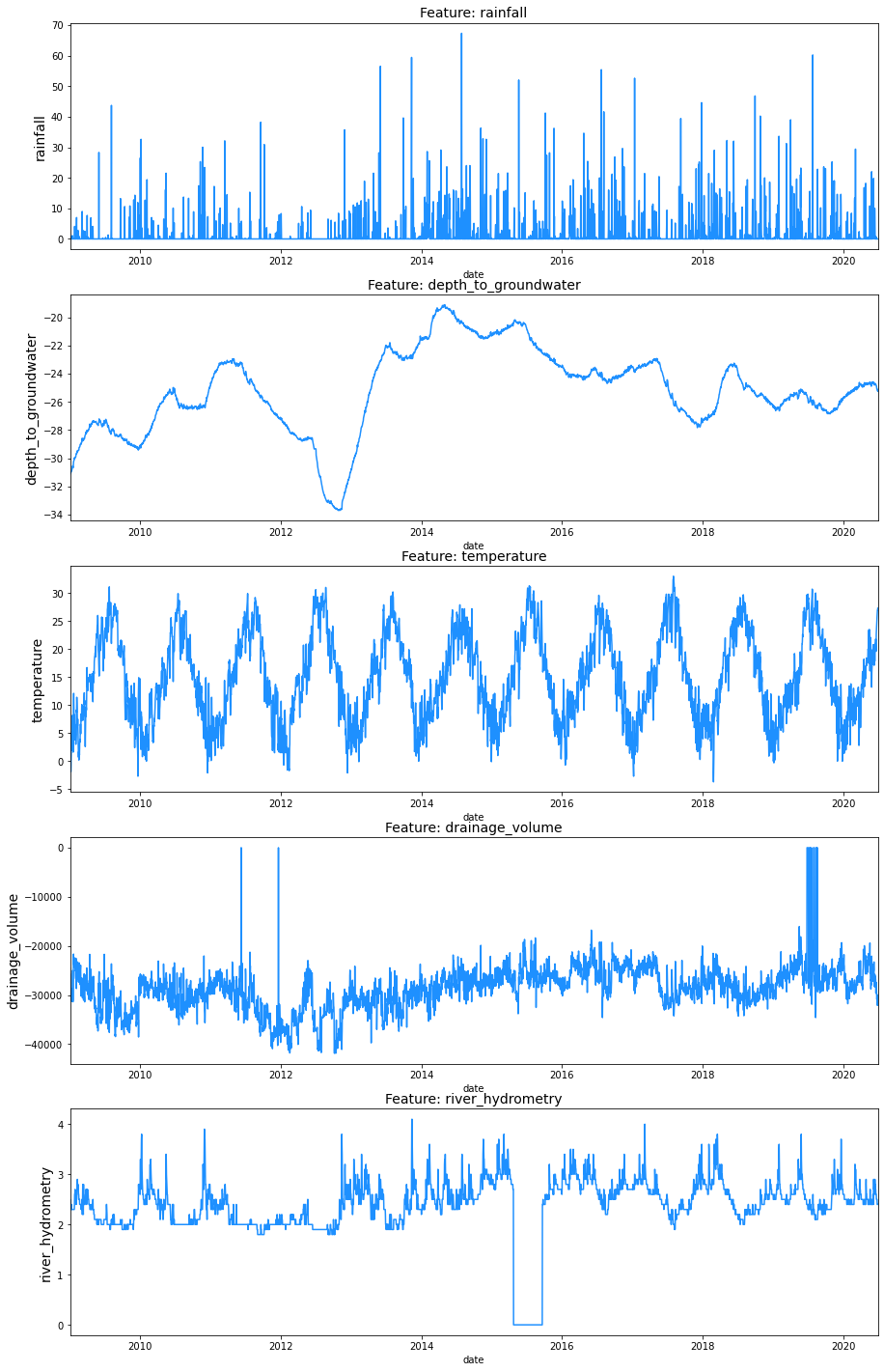
步骤2:数据集分析
时间间隔
分析日期是否包含连续:通过date列进行diff,如果日期列没有缺失值则最大diff为1day。
df = df.sort_values(by='date')
df['delta'] = df['date'] - df['date'].shift(1)
df[['date', 'delta']].head()
缺失值分析
分析数据集是否包含空值,绘制的时间序列显示似乎有一些零值,我们将用nan值替换它们,然后再填充它们。
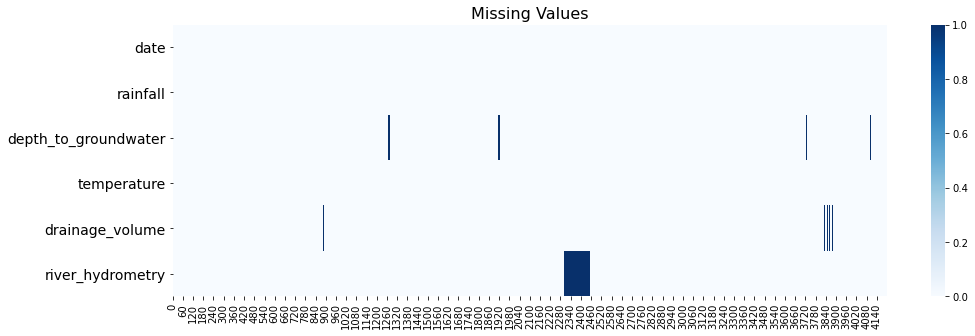
缺失值填充
使用NaN填充 使用均值填充 使用最近的样本填充 使用插值填充

平滑数据/重采样
重采样可以提供更多的数据信息。重采样有两种类型:
上采样:采样频率增加(例如,数天到数小时)。 下采样:采样频率降低(例如,从天到周)。
平稳性
一些时间序列模型,如ARIMA,假设基础数据是平稳的。平稳性描述了时间序列具有:
常数均值和均值不依赖于时间 常数方差和方差与时间无关 常数协方差和协方差与时间无关

平稳性检查可以通过三种不同的方法来完成:
视觉上:绘制时间序列并检查趋势或季节性 基本统计:拆分时间序列,比较每个分区的均值和方差 统计检验:扩充Dickey Fuller检验
特征工程
日期信息
周期编码
新的时间特性是周期性的,特征月周期为每年1至12个月。虽然每个月之间的差值在一年内增加1,但在两年内,月特性从12(12月)跳到1(1月)。
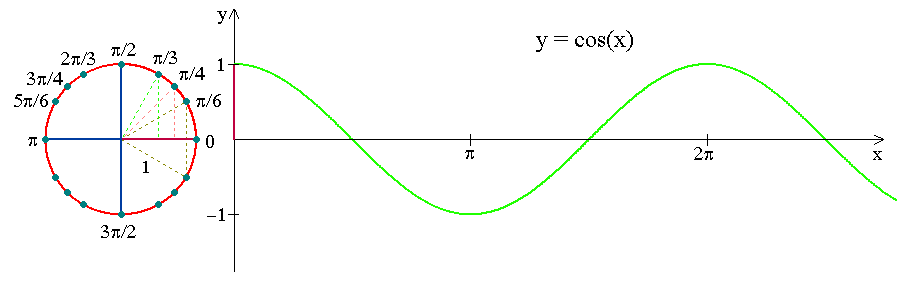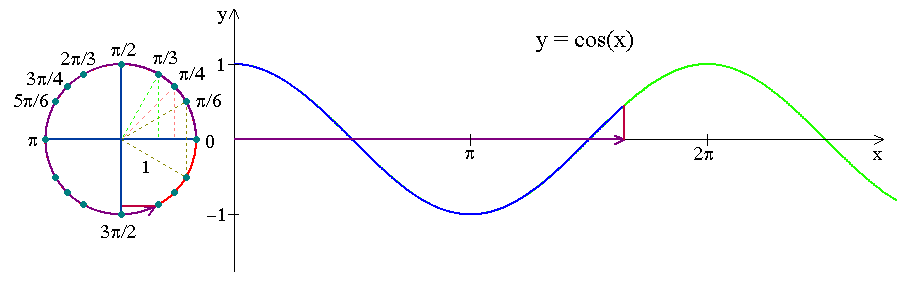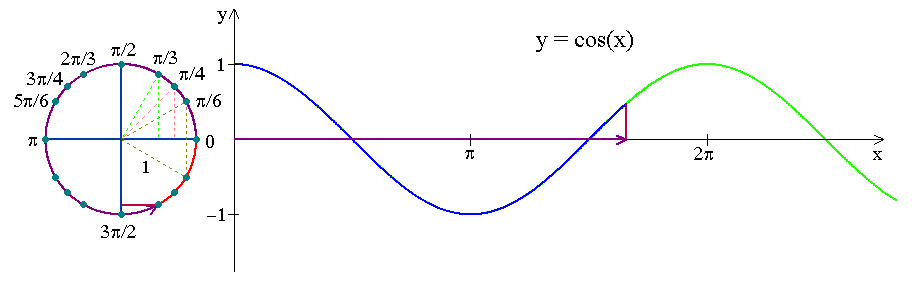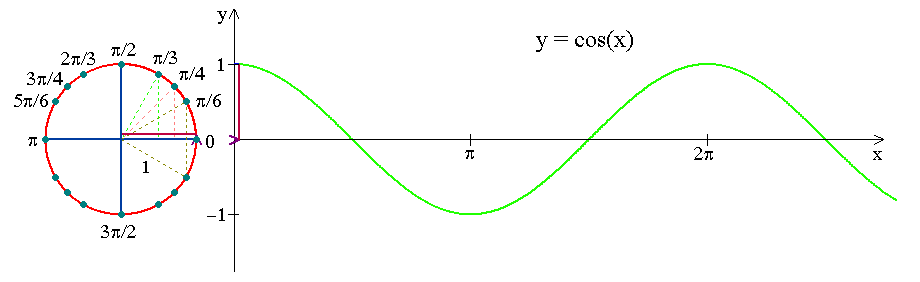
时序分解
时间序列分解涉及到将一个序列看作水平、趋势、季节性和噪声成分的组合。
等级:级数中的平均值。 趋势:数列中增加或减少的值。 季节性:在系列中重复的短期循环。 噪声:数列中的随机变化。 
Lag特征
EDA分析
相关性分析
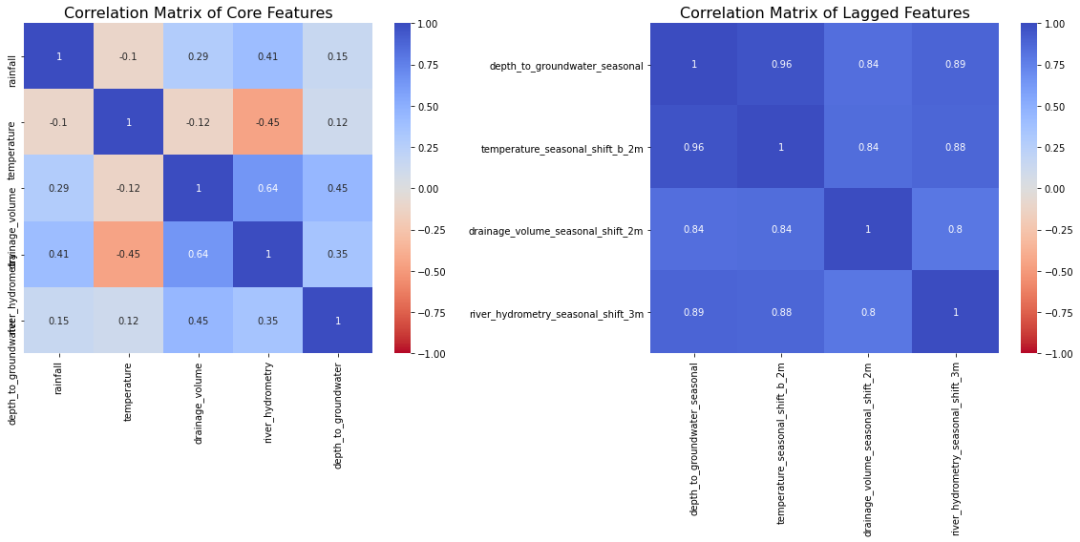
自相关分析
自相关函数(ACF): P=滞后周期,P帮助调整用于预测序列的拟合线,P对应于MA参数

部分自相关函数(PACF): D是时间序列达到平稳所需的差分变换次数。D对应AR参数。

构建模型
时间序列可以是单变量的也可以是多变量的:
单变量时间序列只有一个时间因变量。 多变量时间序列具有多个时间因变量。
数据划分方法
from sklearn.model_selection import TimeSeriesSplit

单变量时序模型
Prophet

ARIMA
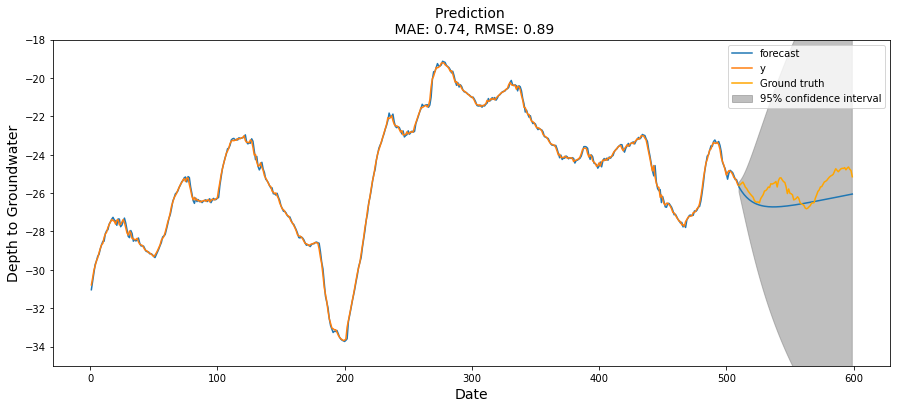
LSTM
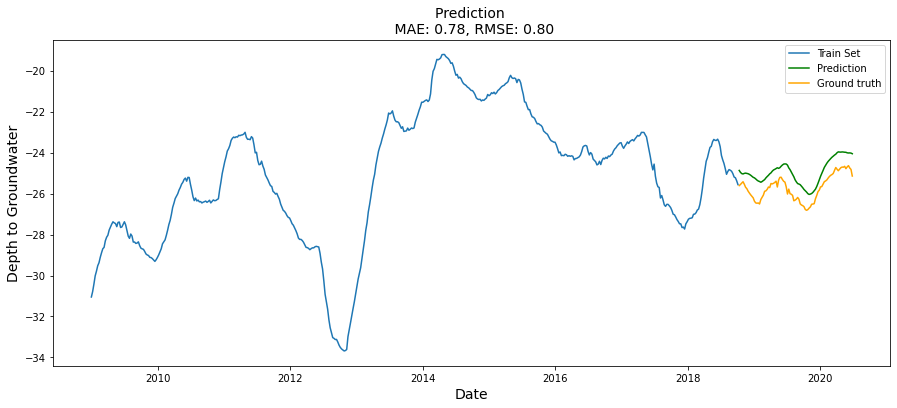
多变量时序模型
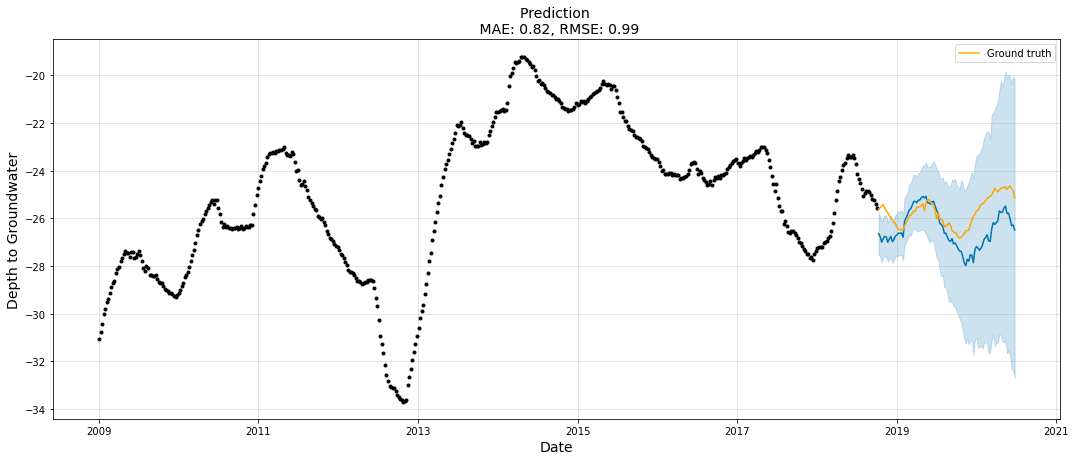
Prophet
完整代码链接:https://www.kaggle.com/andreshg/timeseries-analysis-a-complete-guide/notebook
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码:
评论