
ECCV 引用量最高的10篇论文!SSD登顶!何恺明ResNet改进版位居第二
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
前言
前两天,Amusi 整理了CVPR 和 ICCV 引用量最高的10篇论文,分别详见:
众所周知,CV领域的三大顶会就是:CVPR、ICCV和ECCV。在谷歌发布的2020年的学术指标(Scholar Metrics)榜单,ECCV 位列总榜第58位,是计算机视觉领域排名第三的大会!这个排名是依据过去五年发表研究的数据(覆盖2015-2019年发表的文章),并包括截止2020年6月在谷歌学术中被索引的所有文章的引用量。
本文就来盘点ECCV 2015-2019年引用量最高的10篇论文。根据此数据,一方面能看出这段深度学习黄金时期的研究热点,另一方面查漏补缺,看看这些必看的Top级论文是不是都掌握了。
注1:2015年之前的论文不在统计范围内
注2:引用量是根据谷歌给出的数据,会有波动,但影响不大
第一名:SSD
SSD: Single Shot MultiBox Detector
作者单位:UNC, Zoox, 谷歌, 密歇根大学
作者团队:Wei Liu, Dragomir Anguelov, Dumitru Erhan等
引用量:9097
论文链接(收录于ECCV 2016):
https://arxiv.org/abs/1512.02325
其实没什么好说的,深度学习时代,目标检测必看论文之一!当初和YOLO直接制霸实时性目标检测。
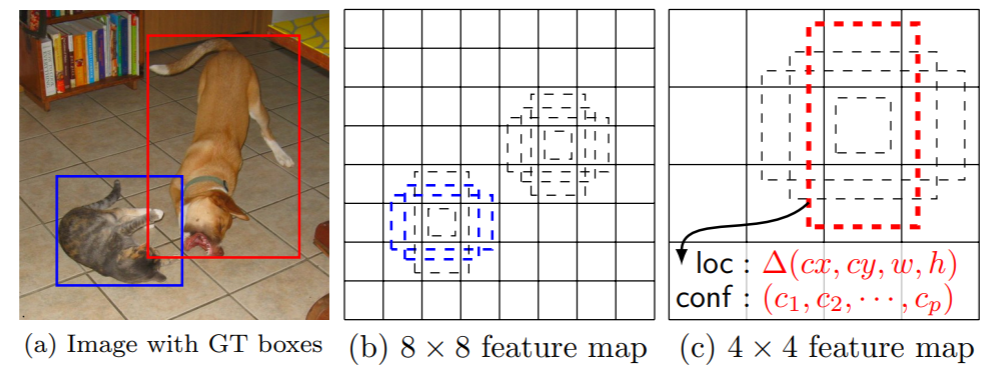
SSD Framework
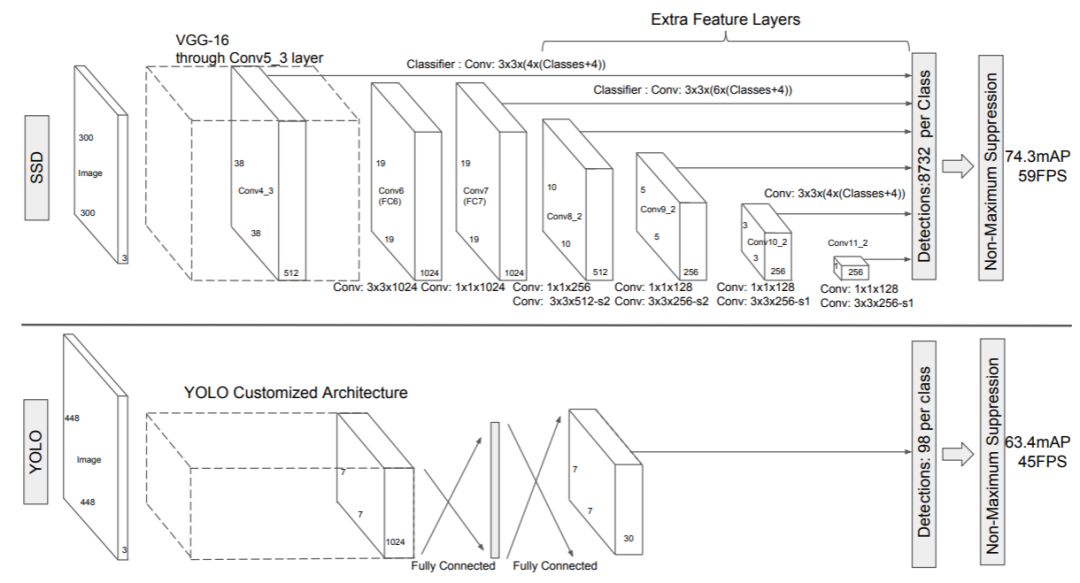
SSD and YOLO
第二名:Identity Mappings in Deep Residual Networks
Identity Mappings in Deep Residual Networks
作者单位:Microsoft Research
作者团队:Kaiming He(何恺明), Xiangyu Zhang, Shaoqing Ren, Jian Sun等
引用量:3778
论文链接(收录于ECCV 2016):
https://arxiv.org/abs/1603.05027
本文是继ResNet(CVPR 2016)的第二篇文章,对ResNet为何能够有效的原因进行进一步的分析并且对原始模型结构进行调整,提出性能更强的网络结构,如下图所示:
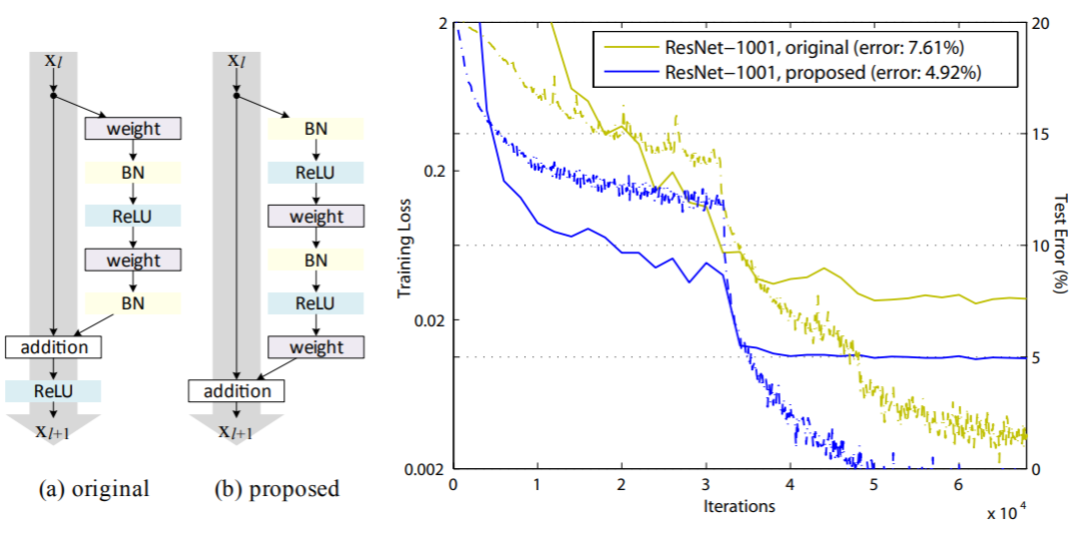
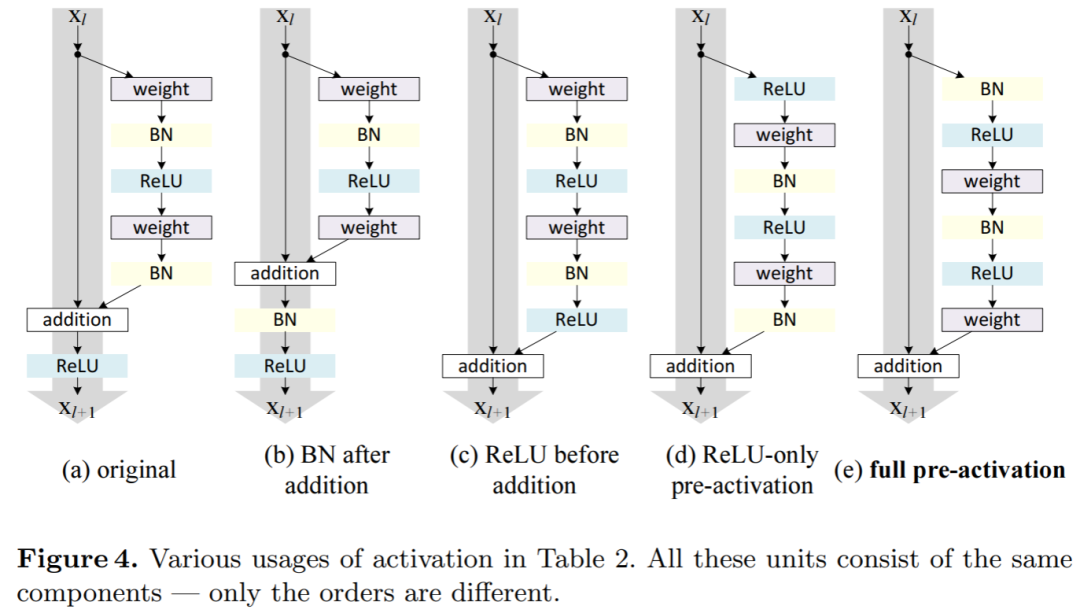
第三名:Perceptual Losses for Real-Time Style Transfer and Super-Resolution
Perceptual Losses for Real-Time Style Transfer and Super-Resolution
作者单位:斯坦福大学
作者团队:Justin Johnson, Alexandre Alahi, Li Fei-Fei(李飞飞)等
引用量:3317
论文链接(收录于ECCV 2016):
https://arxiv.org/abs/1603.08155
本文提出采用感知损失函数训练前馈网络进行图像转换的任务,如成功应用于风格迁移和超分辨率任务。
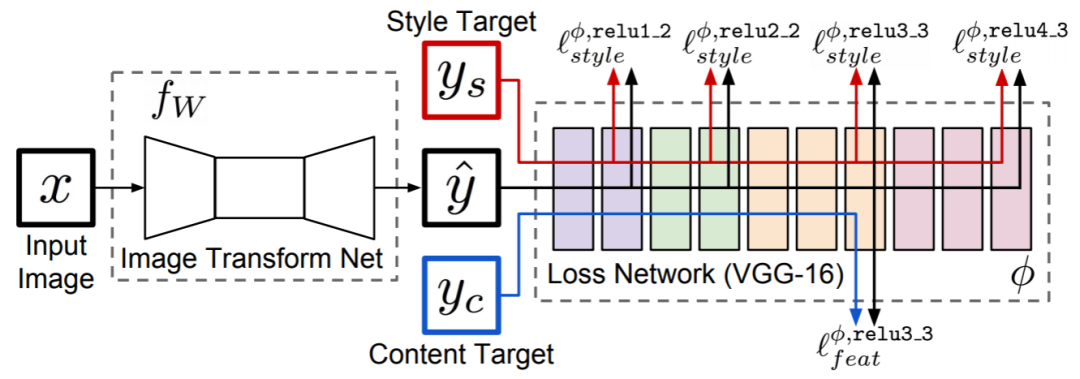
System overview
第四名:XNOR-Net
XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
作者单位:华盛顿大学
作者团队:Mohammad Rastegari, Vicente Ordonez, Joseph Redmon等
注:作者中惊现YOLO之父 Joseph Redmon(之前看论文时,都没注意到)
引用量:2203
论文链接(收录于ECCV 2016):
https://arxiv.org/abs/1603.05279
XNOR 使用位运算和异或运算替换了加减运算,实现了速度的大幅提升。
说句题外话,感觉模型压缩里的几个细分方向中,剪枝的论文比二值(化)的论文要多很多。
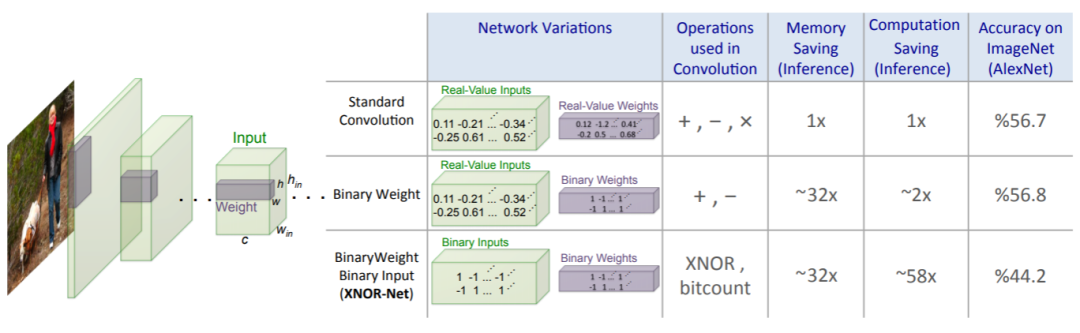
Binary-Weight-Networks 和
XNOR-Networks
第五名:Stacked Hourglass Networks
Stacked Hourglass Networks for Human Pose Estimation
作者单位:密歇根大学
作者团队:Alejandro Newell, Kaiyu Yang, Jia Deng
引用量:1825
论文链接(收录于ECCV 2016):
https://arxiv.org/abs/1603.06937
本文提出了知名的 Stacked Hourglass Networks(堆叠沙漏网络),其在人体关键点检测任务上表现很好。同时拿下MPII 2016冠军!
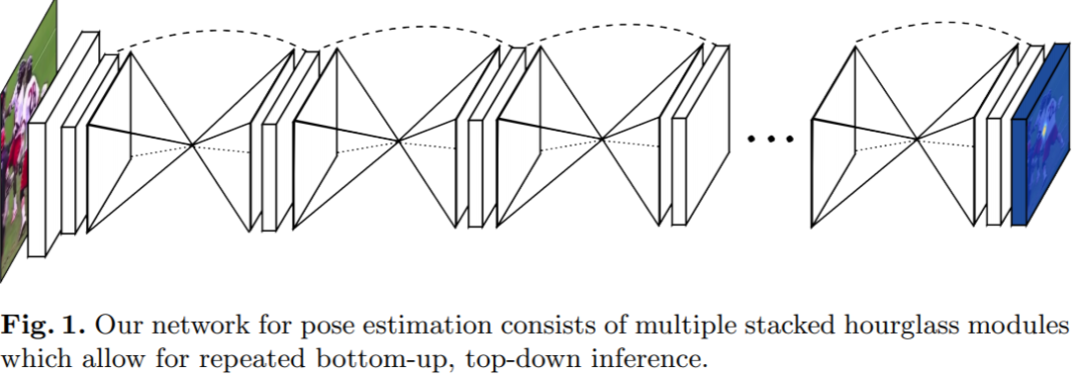
Single “hourglass” module
第六名:DeepLabv3+
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
作者单位:谷歌
作者团队:Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam
引用量:1782
论文链接(收录于ECCV 2018):
https://arxiv.org/abs/1802.02611
DeepLab系列 在语义分割中的重要性应该相当于R-CNN系列在目标检测中的重要性,而这篇DeepLabv3+ 也正是目前该系列的最终篇。技巧很多,如将depthwise separable convolution应用于ASPP中,最终性能超级强。
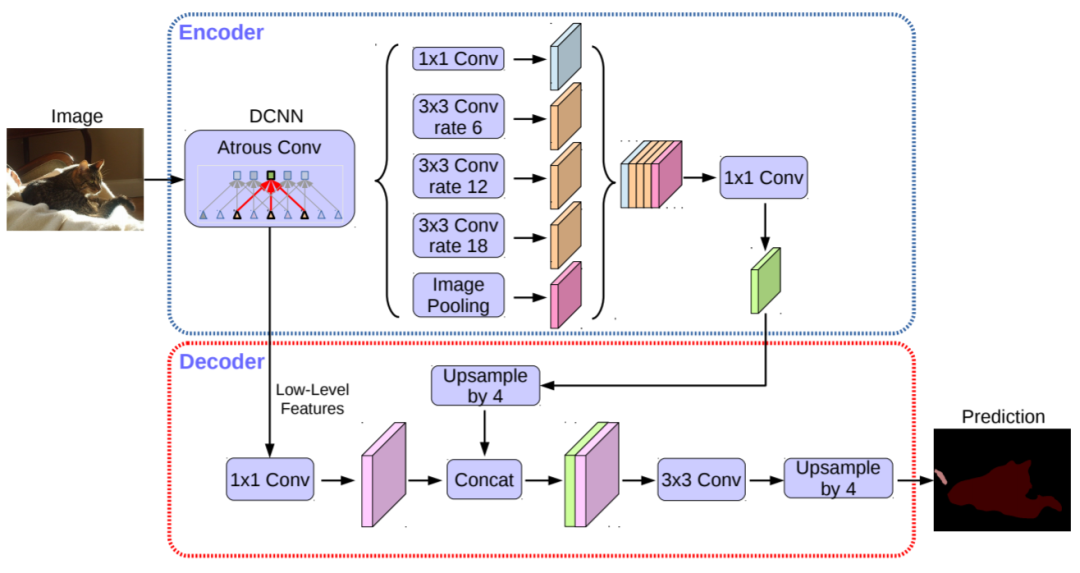
DeepLabv3+
第七名:Center Loss
A Discriminative Feature Learning Approach for Deep Face Recognition
作者单位:中国科学院深圳先进技术研究院&港中文
作者团队:Yandong Wen , Kaipeng Zhang, Zhifeng Li, Yu Qiao
引用量:1540
论文链接(收录于ECCV 2016):
https://kpzhang93.github.io/papers/eccv2016.pdf
本文提出center loss 让softmax 能够训练出更有内聚性的特征。核心目标还是为了增加类间距离,减小类内距离。
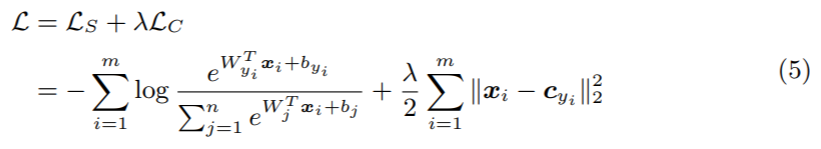
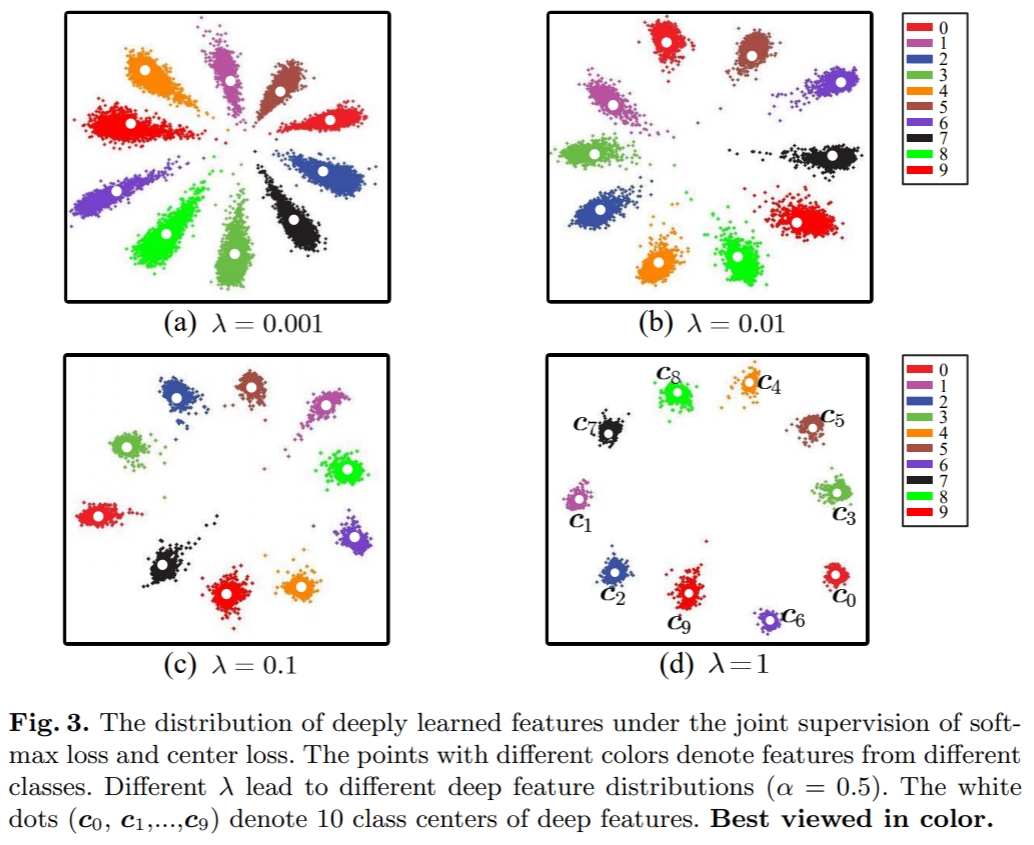
第八名:TSN
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
作者单位:ETH Zurich&港中文&中国科学院深圳先进技术研究院
作者团队:Limin Wang(王利民), Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin,
Xiaoou Tang, and Luc Van Gool
引用量:1465
论文链接(收录于ECCV 2016):
https://arxiv.org/abs/1608.00859
TSN 是行为/动作识别、视频理解方向必读的论文之一!基于TSN 还夺得了 ActivityNet challenge 2016 冠军,其期刊版论文也收录于TPAMI 2018。
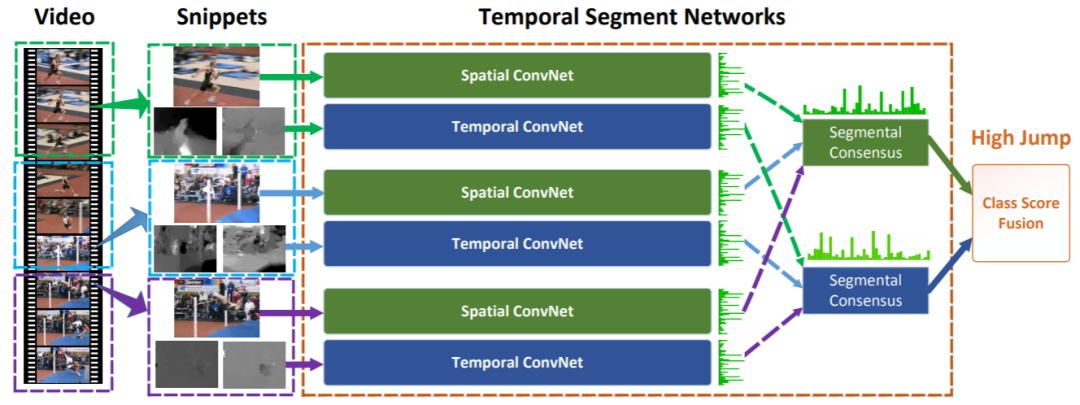
TSN
第九名:SiamFC
Fully-Convolutional Siamese Networks for Object Tracking
作者单位:牛津大学
作者团队:Luca Bertinetto, Jack Valmadre, Jo˜ao F. Henriques等
引用量:1326
论文链接(收录于ECCV 2016):
https://arxiv.org/abs/1606.09549
SiamFC 深度学习时代目标跟踪方向的开山之作!引领了一系列孪生网络,比如后面的SiamRPN、SiamFC++、SiamRPN++、SiamMask等。
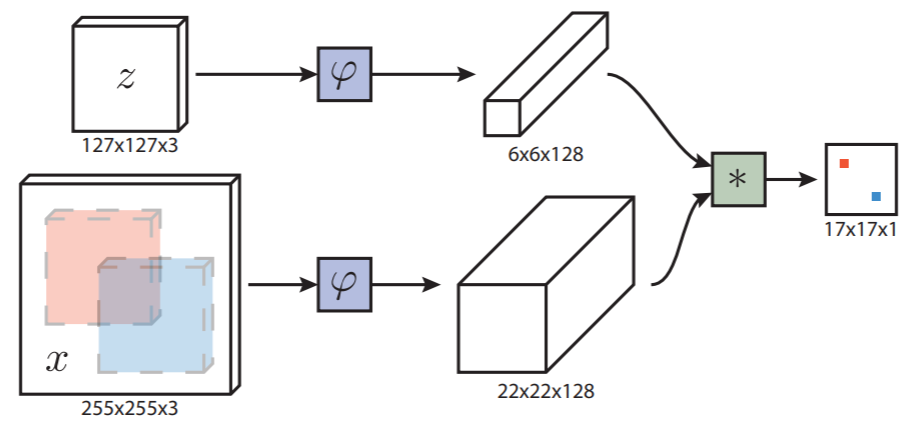
SiamFC
第十名:Colorful Image Colorization
Colorful Image Colorization
作者单位:加州大学伯克利分校
作者团队:Richard Zhang, Phillip Isola, Alexei A. Efros
引用量:1090
论文链接(收录于ECCV 2016):
https://arxiv.org/abs/1603.08511
对灰度图进行自动着色
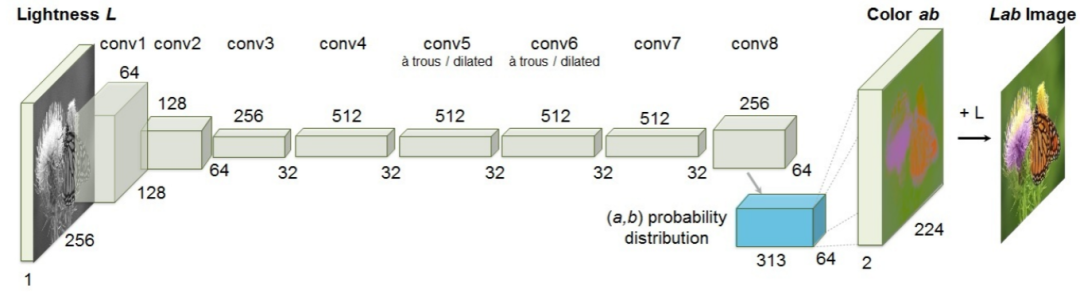
Network Architecture
侃侃
1. DeepLabv3+是唯一一篇收录于ECCV 2018的论文,其他均是2016;
2. 谷歌、密歇根大学、中国科学院深圳先进技术研究院和香港中文大学均有两篇论文入围;