五年引用量最高的10大论文:Adam登顶,AlphaGo、Transfromer上榜 关注 共
8043字,需浏览
17分钟
·
2021-05-08 13:19
来源 | AI科技评论
编译 | 琰琰
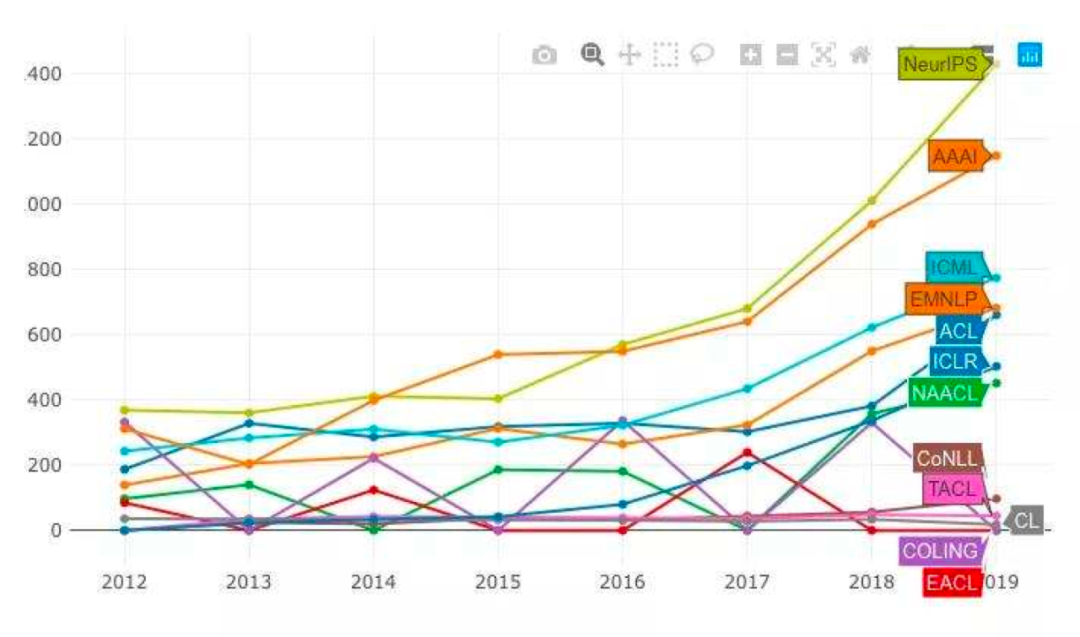
近五年来,AI学术论文的投稿量和接收量都在不断攀升,包括NeurIPS、AAAI、ACL,ICML、EMNLP等国际顶会。根据权威数据统计,NeurIPS论文收录量在2019年呈指数级增长,领先AAAI近300篇;而AAAI 在2020年创下历史新高,达到了1692篇。 如何在海量论文库中发现最具影响力的论文,谷歌引用次数是学者们参考的一项重要指标,它在一定程度上反映了论文的质量。 近日,知名外媒《Towards Data Science》按这一指标,统计了近五年来发表在各大国际顶级会上引用量排名前十的论文。 根据统计结果显示, Top 1 0 论文引用量最高为67514次,最低6995次,全部出自ICLR、NeurIPSR、NeurIPS、ICML以及《Nature》四家期刊,覆盖深度学习、机器学、强化学习、视觉处理、自然语言处理等多个领域。 其中,智能体AlphaGo、Transfromer模型、强化学习算法DQN,以及神经网络优化算法Adam全部在列。
大部分论文所属研究机构为Google Brain 、Facebook AI Research、DeepMind以及Amsterdam University,作者包括我们熟知的AI大佬Ian J. Goodfellow,Kaiming He Thomas Kipf 、Ashish Vaswani 等。 下面AI科技评论按引用次数从低到高的顺序对Top 10 论文进行简要整理: Top10:Explaining and Harnessing Adversarial Examples 作者:Ian J. Goodfellow, J Shlens, C Szegedy ,收录于 ICLR 2015,引用 6995次. 论文地址:https://arxiv.org/abs/1412.6572 该论文介绍了 快速生成神经网络对抗性示例的方法,并引入了对抗性训练作为正则化技术。 一些机器学习模型,包括最先进的神经网络都容易受到对抗攻击。如对数据集中的示例故意施加微小扰动,模型会对输入示例进行错误分类,从而使得扰动的输入结果以高置信度输出不正确的答案。 对于这一现象,早期的处理方法集中在非线性和过度拟合上。在本篇论文中,研究人员提出神经网络模型易受干扰的主要因其线性性质。通过定量实验,他们发现对抗样本在模型结构和训练集之间的泛化,并由此提出了一种简单而高效的生成对抗性例子的方法,即快速梯度符号法(Fast Gradient Sign Method)。 该方法的主要思想是让扰动的变化量与梯度的变化方向完全一致,通过增大误差函数,以对分类结果产生最大变化。他们认为,在构造对抗样本时更应该关心扰动的反向而不是扰动的数目。经实验,该方法可以 有效减少MNIST数据集上maxout网络的测试集误差。
图注:在ImageNet上用GoogLeNet快速对抗生成的示例 影响力:本篇论文揭示了一个普遍的现象,即攻击者对输入进行微小的修改就可以显著降低任何精确机器学习模型的性能。这一现象已经在其他任务和模式(如文本和视频)中观察到,并影响了了大量研究工作。 Top9:Semi-Supervised Classification with Graph Convolutional Networks 作者:Thomas Kipf 、Max Welling, 收录于ICLR 2017, 引用7021次 论文地址:https://arxiv.org/abs/1609.02907 这篇论文 证明了图卷积网络(GCN)在半监督节点分类任务中性能优越。 论文中,研究人员提出了一种可扩展的图结构数据半监督学习方法,该方法基于一种高效地、可直接操作于图的卷积神经网络。通过谱图卷积(spectral graph convolutions)的局部一阶近似来激励卷积结构的选择,可使模型在图的边数上线性伸缩,并且学习编码局部图结构和节点特征的隐藏层表示。通过在引文网络和知识图数据集中的大量实验,已证实该方法比相关研究有更大的优势。 影响:新型药物或高效能催化剂的发现需要将分子建模为图形。图卷积网络把深度学习的工具带到了图领域,并展示了相比于此前占主导地位的手动方法的优越性。 Top8:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks 作者:Alec Radford 、Luke Metz et al. 收录于 ICLR 2016, 引用 8681次。 论文地址: https://arxiv.org/abs/1511.06434该论文提出了一种深度CNN结构DCGAN,它在图像生成上获得了前所未有的效果。 近年来,卷积网络(Convolutional Networks ,CNNs )的监督学习在计算机视觉应用中得到了广泛应用。相对而言,使用CNNs的无监督学习受到的关注较少。在本篇论文中, 作者弥合了CNNs在有监督学习和无监督学习方面的差距,提出了一种被称为深层卷积生成式对抗网络的CN N, 即Deep Convolutional Generative Adversarial Networks ,简称DCGAN。 DCGAN模型的基本组成部分是用上采样卷积层替换生成器中的完全连接层。其完整体系结构如下: 图注:用于LSUN场景建模的DCGAN生成器
本质上,DCGAN是在GAN的基础上提出了一种训练架构,并对其做了训练指导,比如几乎完全用卷积层取代了全连接层,去掉池化层,采用批标准化(Batch Normalization, BN)等技术;将判别模型的发展成果引入到了生成模型中;强调了隐藏层分析和可视化计数对GAN训练的重要性和指导作用。
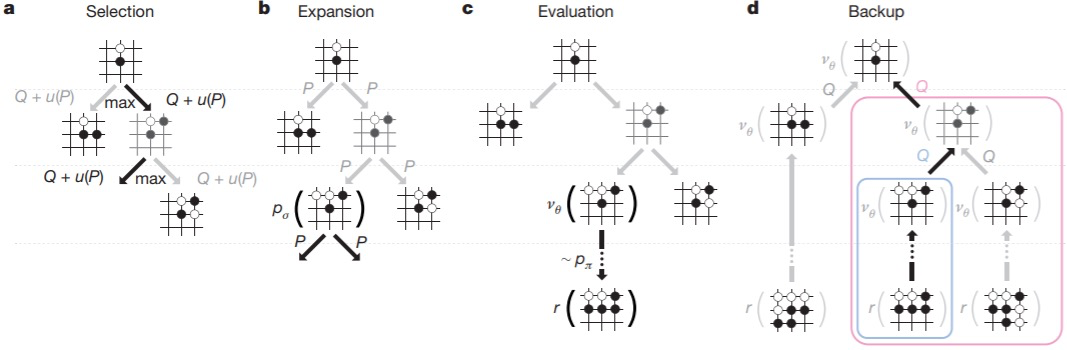
DCGAN的网络结构可以作为基础架构,用以评价不同目标函数的GAN,让不同的GAN得以进行优劣比较。DCGAN的出现极大增强了GAN的数据生成质量。而如何提高生成数据的质量(如生成图片的质量)一直是GAN研究的热门话题。 影响:GANs是一种机器学习模型,它能够生成人、动物或物体的新图像,GANs的性能决定了机器学习的创造力,以及它在诸多现实场景中的应用能力。就目前来看,该方法仍然是所有目前GAN模型生成图像的基础。 Top 7:Mastering the game of Go with deep neural networks and tree search 作者:David Silver 、Aja Huang et al. 2016年被《Nature》收录,引用9621次。 论文地址:https://www.nature.com/articles/nature16961 这篇论文代表了人工智能历史上的一个重要节点,它所描述的分布式AlphaGo第一次在围棋游戏中击败人类职业选手。AlphaGo是DeepMind公司针对围棋游戏而开发的AI智能体,其在2016年1月首次推出便在行业内引起不小震动。而在此之后,DeepMind不断优化智能体,AlphaGo又陆续战胜了世界顶级围棋选手李世石和柯洁。 围棋是人工智能最具挑战性的游戏之一。在这篇论文中,作者提出了一种新的计算围棋的方法,该方法使用“价值网络”评估棋子的位置,使用“策略网络”选择落子点,通过将两种网络与蒙特卡罗搜索树(MCTS)相结合所形成的搜索算法,能够使AlphaGo达到99.8%的获胜率。 具体来说,作者采用深度卷积神经网络,将19*19的棋盘看做是一个图像,使用网络构建棋盘每个位置的表示。 其中价值神经网络用于棋面局势评估,策略神经网络用于采样下一步动作,这两种网络能够有效减少搜索树的宽度和深度。 接下来再使用管道来组织和训练神经网络,管道由多个阶段的机器学习过程构成。第一阶段先构建一个监督学习策略网络, 训练数据来自人类专家棋手的比赛数据;
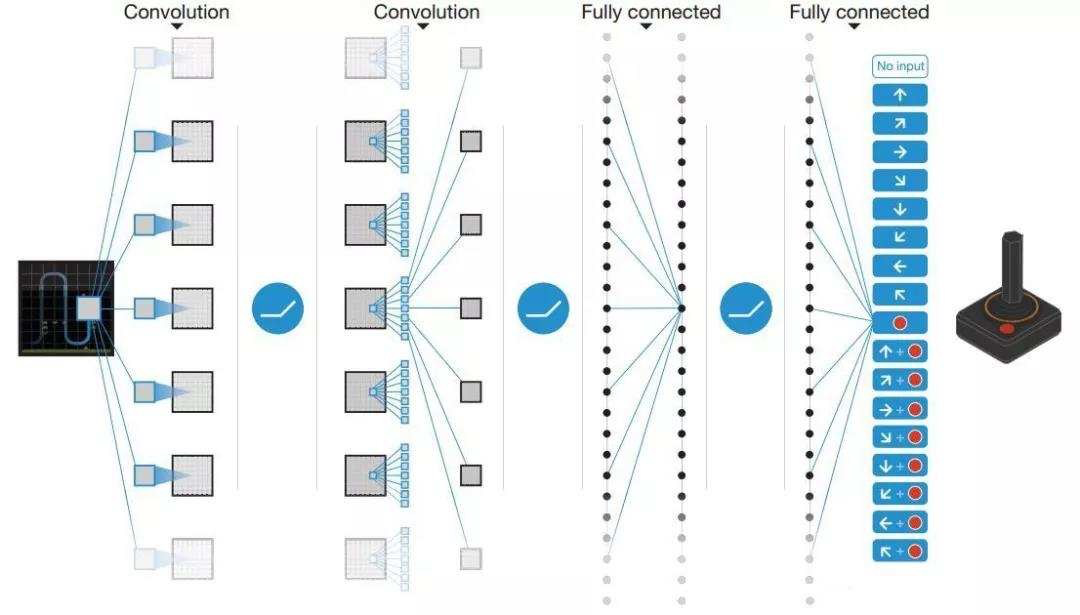
图注:AlphaGo采用蒙特卡洛树搜索获取最佳的落子点 第三阶段训练一个强化学习策略网络,通过自我对弈,在监督学习网络最终学习结果基础上调整优化学习目标。这里的学习目标是赢棋,战胜监督学习策略网络,而原始的监督学习策略网络预测的是跟专家走法一致的准确率。最后阶段训练一个价值网络,用于预测某个棋面局势下赢棋的概率。 以上这些离线训练的策略网络和价值网络能够有效的和蒙特卡罗搜索树(MCTS)结合在一起,进而在线上进行比赛。下图是分布式版AlphaGo和人类顶级职业棋手FanHui进行的5局对决的终局棋面,AlphaGo以5:0战胜FanHui。 AlphaGo之后,DeepMind又陆续推出了第二代、第三代智能体,其中, 第二代AlphaGoZero,只使用自监督强化学习+无人工特征+单一网络+蒙特卡罗搜索 第三代AlphaZero,在AlphaGoZero基础上做了进一步的简化,训练速度更快。 现阶段,DeepMind已将AI训练从围棋游戏扩展到了更为复杂的即时战略性游戏《星际争霸2》,所推出的智能体AlplaStar同样达到了战胜顶级职业选手的水平。 影响力:计算机程序第一次战胜人类职业选手,这是人工智能历史上的一个重要里程碑。 Top 6:Human-level control through deep reinforcement learning 作者:Volodymyr Mnih 、Koray Kavukcuoglu et al. 2015年被《Nature》收录,引用13615次。 论文地址:https://www.nature.com/articles/nature14236 本篇论文提出了一种强化学习算法Deep Q-Learning,简称DQN,它几乎在所有游戏上超越了之前的强化学习方法,并在大部分Atari游戏中表现的比人类更好。 人工智能领域的从业者对DQN可能并不陌生,它被视为深度强化学习的开山之作,是 将深度学习与强化学习结合起来从而实现从感知(Perception)到动作( Action )的端对端(End-to-end)学习的一种全新的算法。
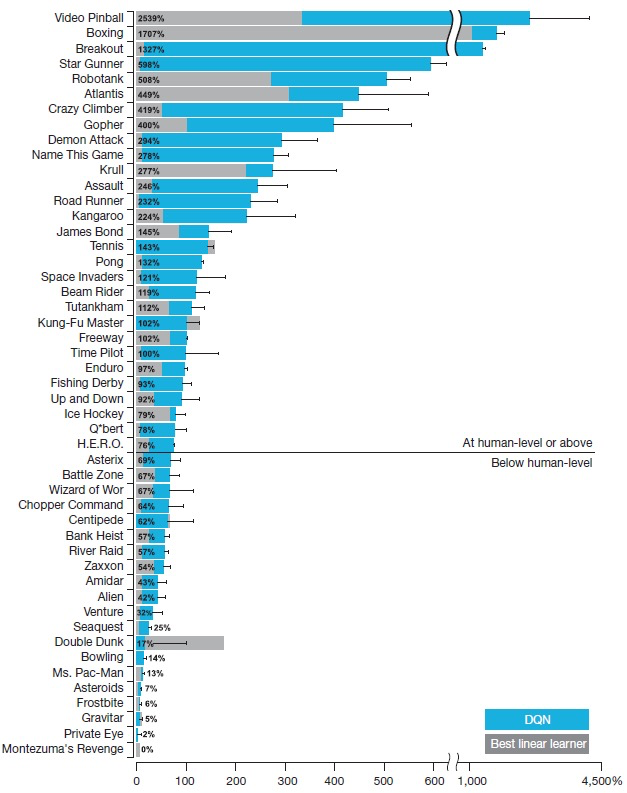
为了能够实现通用人工智能,即用单一的算法解决某个领域的多类挑战性任务,作者开发了一个深度Q网络(DQN),它是强化学习和深度学习的结合。我们知道,要想模拟现实世界中成功使用强化学习,智能体必须从高维感官输入中获得对环境的有效表示,并利用它们将过去的经验推广到新的场景中,而DQN使用端到端强化学习可以直接从高维感官输入中学习策略。 在深度学习方面,作者表示通过卷积神经网络,使用多层的卷积滤波器模仿感受野的作用——灵感来自于Hubel和Wiesel在视觉回路的原始前馈处理,因此,它可以挖掘图像中局部的空间相关的信息,建立对于视角和比例缩放自然转换非常鲁棒。 通过在Atari 2600款游戏中的测试表明,仅接收像素和游戏得分作为输入的深度Q网络超越了之前所有算法的性能,并在49款游戏中达到与人类玩家相当的水平。
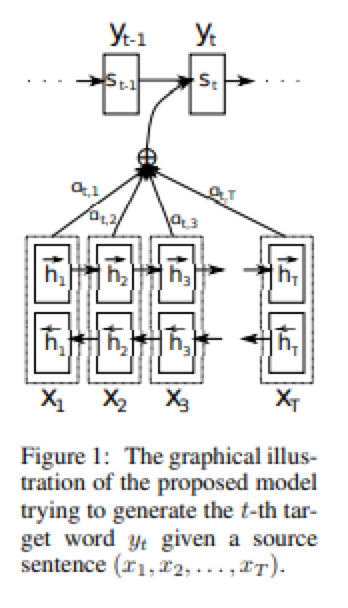
图注:DQN算法(蓝色)、SOTA算法(灰色)以及人类玩家(百分比)在Atari游戏中的比较 影响力:机器人、智能制造、智能物流等领域背后的算法已经从硬编码规则转向强化学习模型。DQN是目前最流行的深度强化学习算法之一,它在各种应用中表现出了优异性能, 而且不需要人工策略的参 与。 Top 5:Neural Machine Translation by Jointly Learning to Align and Translate 作者:Dzmity Bahdanau、KyungHyun Cho et al. 收录于 ICLR 2015, 引用16866次。 论文地址 : https://arxiv.org/abs/1409.0473 该论文 首次提出 将带有注意力机制的神经网络应用于机器翻译。“注意”表征的是特定词,而不是整个句子。 与传统的统计机器翻译不同,神经机器翻译的目的是构建可实现最大化翻译性能的单个神经网络。现有的神经机器翻译模型通常属于编码器-解码器家族,编码器将源句子编码为固定长度的向量的编码器,解码器再根据该固定长度向量生成翻译。 在此基础上,作者提出使用固定长度的向量可以提高编码器-解码器体系结构的性能,并且允许模型自动搜索对象可扩展此范围。后者意味着模型课搜索与预测目标单词相关的源句子,而无需进行明确的分割。 实验表明, 该方法达到了与最先进的基于短语的最新系统相同的表现。 此外, 定性分析也表明该方法发现的软对齐方式与我们的直觉一致。
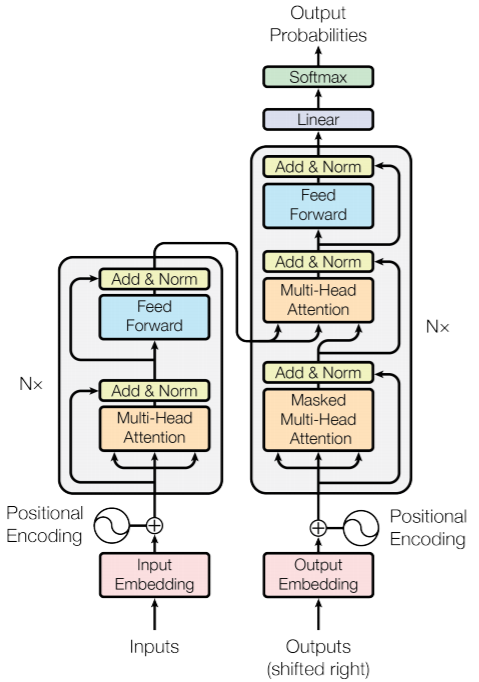
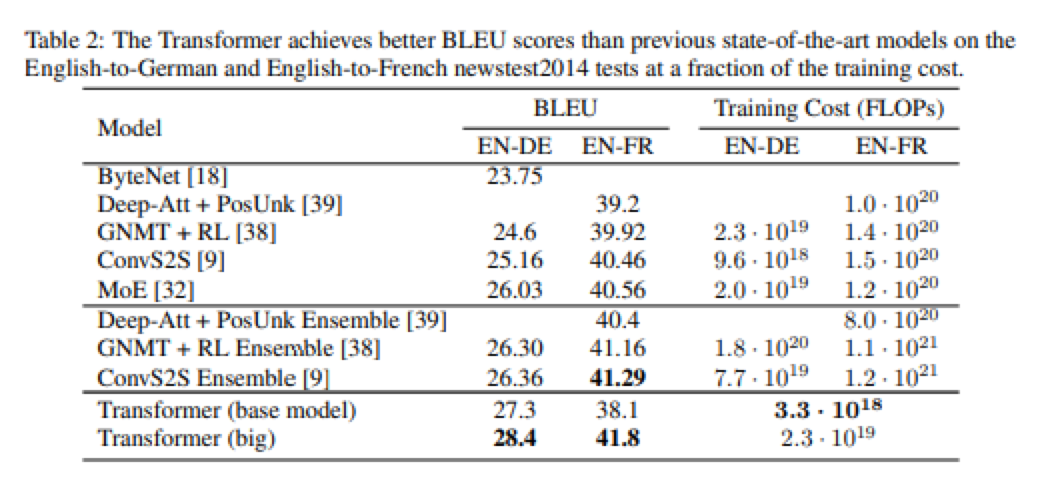
图注:英法翻译的注意矩阵, 较浅的区域代表单词之间相似性很高 影响:在机器翻译中,RNN等传统模型试图将源语句的所有信息压缩成一个向量。而本篇论文提出模型应将每个词表示为一个向量,然后关注每个词,这一认识对于神经网络的构建是一个巨大的范式转变,不仅在NLP领域,在ML的所有其他领域均是如此。 Top 4:Attention is all you need 作者:Ashish Vaswani 、Noam Shazeer 等人;收录于NeurIPS 2017, 引用18178次; 论文地址: https://arxiv.org/abs/1706.03762 该论文提出了一种有效的神经网络Transformer,它基于注意机制在机器翻译中取得了优异的性能。 通常来讲,序列转导模型基于复杂的递归或卷积神经网络,包括编码器和解码器,表现最佳的模型还通过注意力机制连接编码器和解码器。基于此,作者提出了一种新的简单网络架构,即Transformer,它完全基于注意力机制,完全消除了重复和卷积。 实验表明,该模型在机器翻译任务上表现良好,具有更高的可并行性,所需的训练时间也大大减少。如在WMT 2014英语到德语的翻译任务上达到了28.4 BLEU,比包括集成学习在内的现有最佳结果提高了2 BLEU;在2014年WMT英语到法语翻译任务中,创造了新的单模型最新BLEU分数41.8,比文献中最好的模型的训练成本更小。 由此 证明了Transformer应用于具有大量训练数据和有限训练数据的英语解析可以很好的概括其他任务。 影响力:在Transformer模型中引入的多头注意力是最受欢迎的深度学习模块,也是另一主流语言模型BERT的一部分,它取代RNNs和CNNs,成为了处理文本和图像任务的默认模型。 Top 3:Faster R-CNN: towards real-time object detection with region proposal networks 作者:Shaoqing Ren ,Kaming He et al.收录于NeurIPS 2015, 引用19915次。 论文地址:https://arxiv.org/abs/1506.01497 该论文提出了一种 用于目标检测的高效端到端卷积神经网络,包括图像和视频中。 最先进的物体检测网络依靠区域提议算法来假设物体的位置,基于此,作者在现有研究基础上,提出了一种区域提议网络(RPN), 该网络与检测网络共享全图像卷积特征,从而实现几乎免费的区域提议。 RPN是一个完全卷积的网络,能够同时预测每个位置的对象边界和对象性分数。对RPN进行了端到端训练,可以生成高质量的区域建议,然后Fast R-CNN再通过这些建议进行检测。 作者表明通过共享RPN和Fast R-CNN的卷积特征,具有“注意力”机制的神经网络可将这些特征合并为一个网络。对于深层VGG-16模型,该检测系统在GPU上的帧速率为5fps(包括所有步骤),同时在PASCAL VOC 2007、2012和MS COCO数据集上实现了最新的对象检测精度(每张图片有300个建议)。在ILSVRC和COCO 2015竞赛中,Faster R-CNN和RPN是多个项目上获得最佳模型的基础。
图注:在PASCAL VOC 2007测试中,使用RPN可以检测各种比例和宽高比的物体 影响:更快速是R-CNN是在工业场景中被广泛应用的主要原因之一。它在安全摄像头、自动驾驶和移动应用程序中的应用极大地影响了我们对机器的感知。 Top2:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 作者:Sergey Ioffe and Szegedy, 收录于ICML 2015, 引用 25297次。 论文地址:https://theaisummer.com/normalization/ 该论文提出通过对输入特征进行归一化的方法,可使神经网络训练更快,更稳定。 训练深度神经网络是一个复杂的过程,一方面,随着各层参数的变化,输入的分布也会发生改变,而由于参数初始化和较低的学习效率,会导致训练速度减慢。另一方面,训练饱和的非线性模型非常困难。 作者将这两种现象归结为内部协变量偏移,并提出通过归一化输入层来解决。即通过将归一化作为模型体系结构的一部分,并为每次小批量训练执行归一化。这种批处理规范化处理方法可以显著提高学习率,同时不必对初始化进行任何注意,在某些情况下,也无需进行辍学。
论文中指出批归一化应用于最先进的图像分类模型,能够以相同精度,减少14倍的训练速度击败原始模型。论文中,作者展示了使用批归一化网络处理ImageNet分类图像的结果:达到4.82%的top-5测试错误,超过了人类评分者的准确性。 影响力:该方法广泛应用于大多数神经网络体系结构。 批处理规范化是现代深度神经年网络获得最佳结果的原因之一。 Top 1:Adam: A Method for Stochastic Optimization 作者:Kingma and Ba,收录于ICLR 2015,引用 67514次。 本篇论文在五年里引用量最高接近7万次,它主要描述了一种新型的随机梯度下降优化算法(Adam), 显著提高了神经网络的快速收敛率,在所有模型训练中具有普遍的适用性。 基于低阶矩的自适应估计的Adam,是一种基于一阶梯度的随机目标函数优化算法。它具有易实现,计算高效,存储需求小,对梯度对角线缩放无影响的特点,适合处理参数量、数据量较大,非固定目标以及嘈杂或稀疏梯度等问题。作者在论文中分析了Adam的理论收敛性,并提供了与在线凸优化框架下的最佳结果相当的收敛。
实验结果表明,与其他随机优化方法相比,Adam在实践中的效果更好。作者在论文中还进一步探讨了Adam的变体,即基于无穷范数的AdaMax。 影响:作为优化算法的默认方法,Adam已训练了的数以百万计的神经网络。 参考来源:https://towardsdatascience.com/top-10-research-papers-in-ai-1f02cf844e26
浏览
44
分享
手机扫一扫分享
分享
手机扫一扫分享





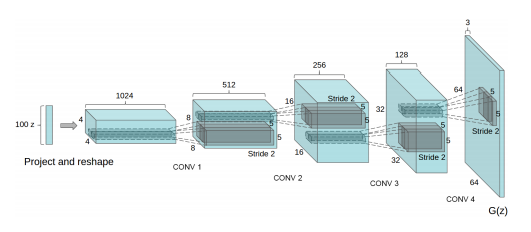 图注:用于LSUN场景建模的DCGAN生成器
图注:用于LSUN场景建模的DCGAN生成器