AI告诉你,83家顶级媒体各有何偏见?

大数据文摘授权转载自数据实战派
作者:李玉婷
媒体的新闻报道存在偏见是一个老生常谈的问题。但究竟如何能量化它们的偏见情况?
近日,麻省理工学院的一个团队便使用机器学习技术,来识别美国及其他地区大约 100 家最大且最有影响力的新闻媒体的偏见情况,其中包括 83 家最具影响力的纸媒。
这项研究工作展示了通往自动化系统的道路,该系统可能会自动对出版物的政治特性进行分类,并让读者更深入地了解媒体在他们可能热衷的话题上的道德立场。
该研究集中在如何用特定措辞处理主题上,例如无证移民/非法移民,胎儿/未出生的婴儿,示威者/无政府主义者。
研究团队使用自然语言处理(NLP)技术将此类“有倾向的”语言的例子(假设看起来更“中立”的术语也有其政治立场)提取和分类为一个广泛的映射,映射揭示了来自约 100 个新闻媒体的 300 多万篇文章左倾和右倾的立场,这导致了相关出版物的偏见。
这篇来自麻省理工学院物理系的 Samantha D'Alonzo 和 Max Tegmark的论文观察到,在众多“假新闻”丑闻之后,一系列主动的“事实核查”都是虚伪且服务于特殊利益的(“数据实战派”后台回复“媒体”可获取)。
他们希望提供一种更加偏向数据驱动方法来研究偏见和“有影响力的”语言在理应中立的新闻背景下的使用。
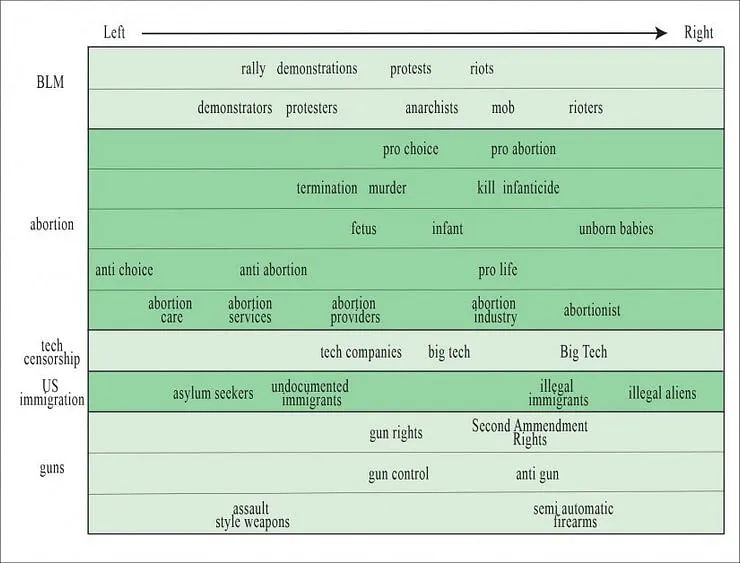
从左倾到右倾用词的表格(来源:https://arxiv.org/pdf/2109.00024.pdf)
自然语言处理过程
该研究的源数据来自开源数据库 Newspaper3K,包括从 100 家新闻媒体获得的 3,078,624 篇文章,其中 83 家是纸媒。这些纸媒是根据其影响范围选择的。同时,网络媒体来源还包括来自军事新闻分析网站 Defense One 和 Science 的文章。

图 | 该研究中用到的源数据
下载的文本经过“最低程度的”预处理。直接引用被删除,这是因为该研究对记者选择的语言感兴趣(尽管如何选择引用本身也是一个有趣的研究领域)。
为了让数据库标准化,英式拼写被改为美式拼写,所有标点符号被删除,除序数外的所有数字也删除。同时,首句大写转换为小写,但所有其他大写保留。
研究识别出前 100,000 个最常见的短语,然后对其进行排序、整理并合并到短语列表中。所有多余的语言(例如“分享这篇文章”和“文章已被重新发布”)都被识别并删除。基本相同的短语(如“big tech”和“Big Tech”、“cybersecurity”和“cyber security”)也被标准化。
挑选谬论
最初的测试关于“黑人的命也是命”主题,研究识别出了数据中的偏见习语和同义词。
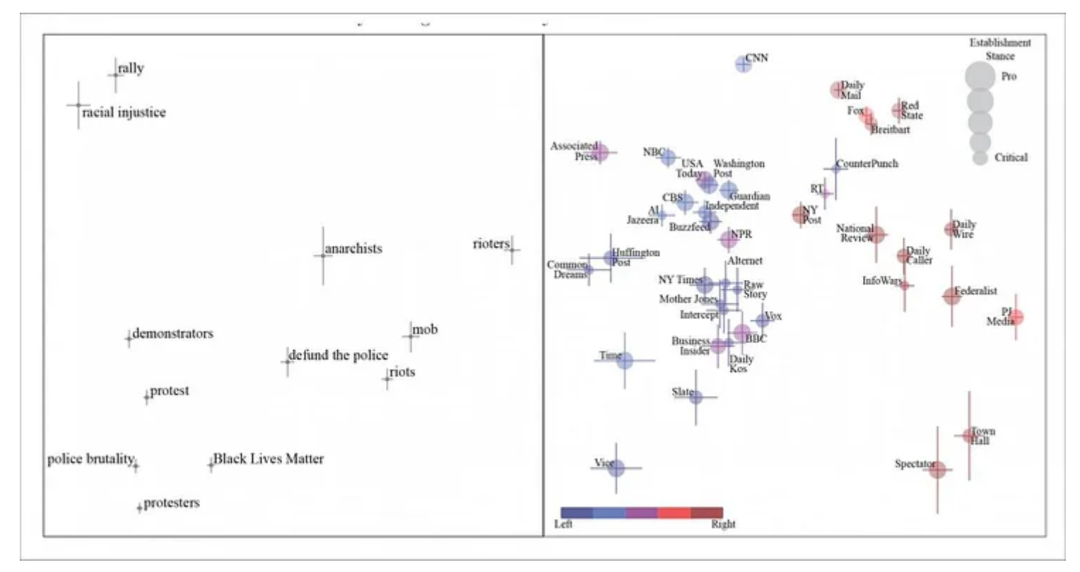
关于黑人的命也是命文章的通用原则组件。我们看到参与公民活动的人从字面上和比喻上从左到右被描述为示威者、无政府主义者,而在最右端,则被称为“暴徒”。使用短语的报纸显示在右侧面板中。
当我们的用词随着政治立场变动时,“抗议者”就会从“无政府主义者”转变为“暴徒”。但该论文指出,自然语言处理提取和分析立场受到“挑选谬论”行为的阻挠——在这种情况下,媒体将引用一个被社会不同政治阶层视为有意义的短语,并且(显而易见的)依靠其读者来消极地看待该短语。该论文引用了“撤销对警察的资助”作为例子。
自然而然的,这意味着一个“左倾”短语出现在一右翼背景下,这对依赖编码短语作为政治立场标志的自然语言处理系统来说是一个不寻常的挑战。
这些短语是具有两面性的,而某些其他短语却有着普遍的负面含义(如“杀婴”),以至于它们总是在新闻中代表负面。
该研究还揭示了热门话题的类似映射,如堕胎、技术审查、美国移民和枪支管制。
狂热爱好
媒体中存在某些有争议的政治倾向,但不会以一种可预见地方式分裂,例如军费话题。该论文发现,“左倾”的 CNN 在这个主题上最终立场接近了右倾的National Review 和 Fox News。
然而,一般情况下,政治立场可以由其他短语决定,例如选用“军事工业综合体”而不是更右倾的“国防工业”。结果表明,前者被 Canary 和 American Conservative 等重要机构媒体使用,而后者更常被 Fox 和 CNN 使用。
该研究建立了从对批判性语言到支持性语言的其他几个进展,包括从“被枪杀”到更被动的“杀戮”的范围;“重罪犯”到“被监禁的人”;从“石油生产商”到“大型石油公司”。
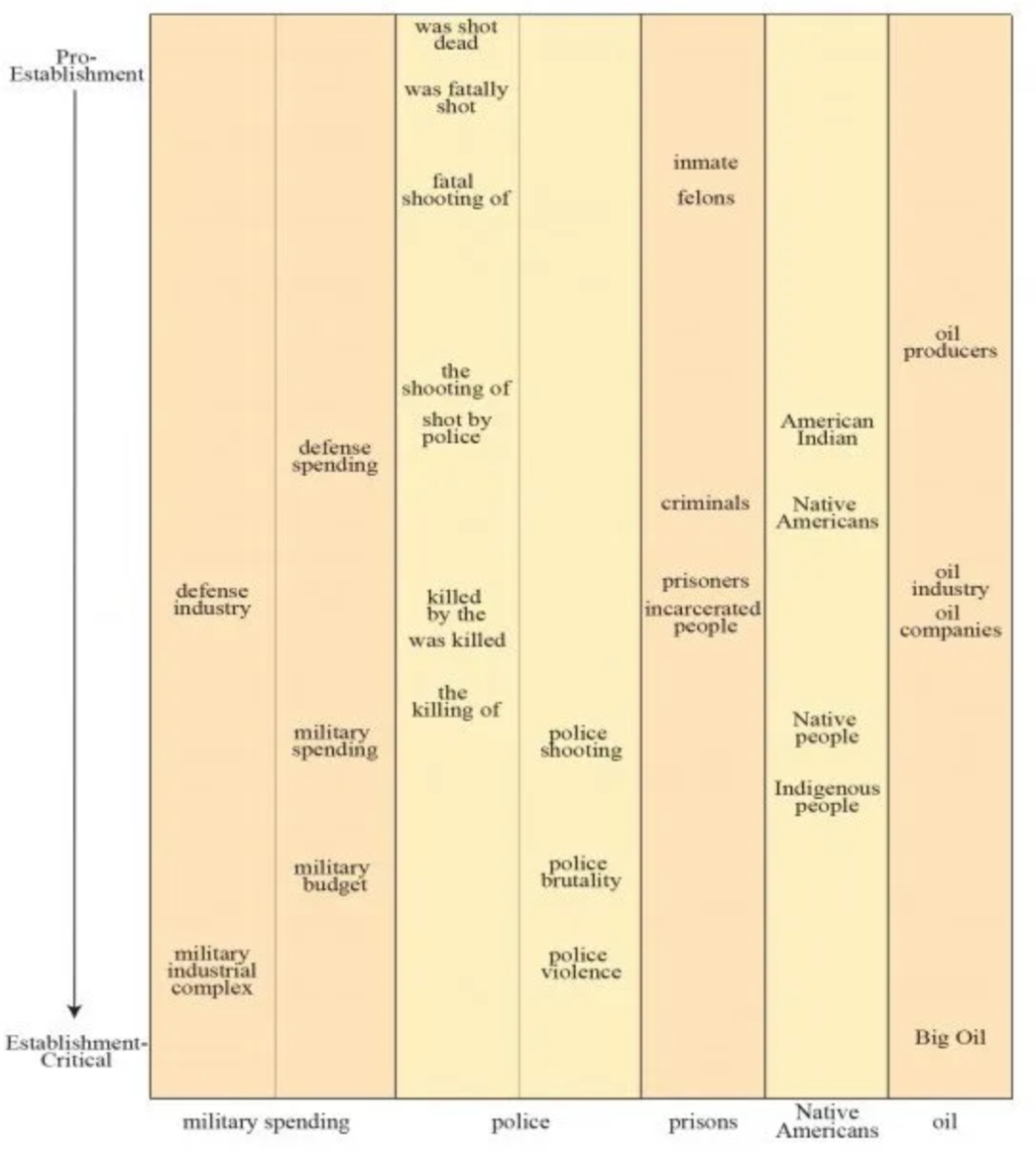
图 | 从上到下,建立偏见的价值同义词
研究承认,无论是在语言层面(例如使用具有两面性的短语),还是出于各种其他动机,媒体都会“摆脱”他们的基本政治立场。
例如,成立于 1828 年的受人尊敬的右翼英国出版物 The Spectator 经常突出展示具有左翼思想的作品,这些作品与其内容通常的政治倾向背道而驰。这样做是为了拥有公正报道的感觉,还是为了定期激怒其核心读者群以在评论区产生流量,目前还尚不确定——对于寻找清晰且一致的标记的机器学习系统来说,这不是一个简单的案例。
这些特殊的“狂热爱好”和个别新闻机构对“并不协调的”观点的模棱两可的使用,在某种程度上混淆了研究最终提供的左倾和右倾的映射,尽管它提供了不同政治倾向的迹象。
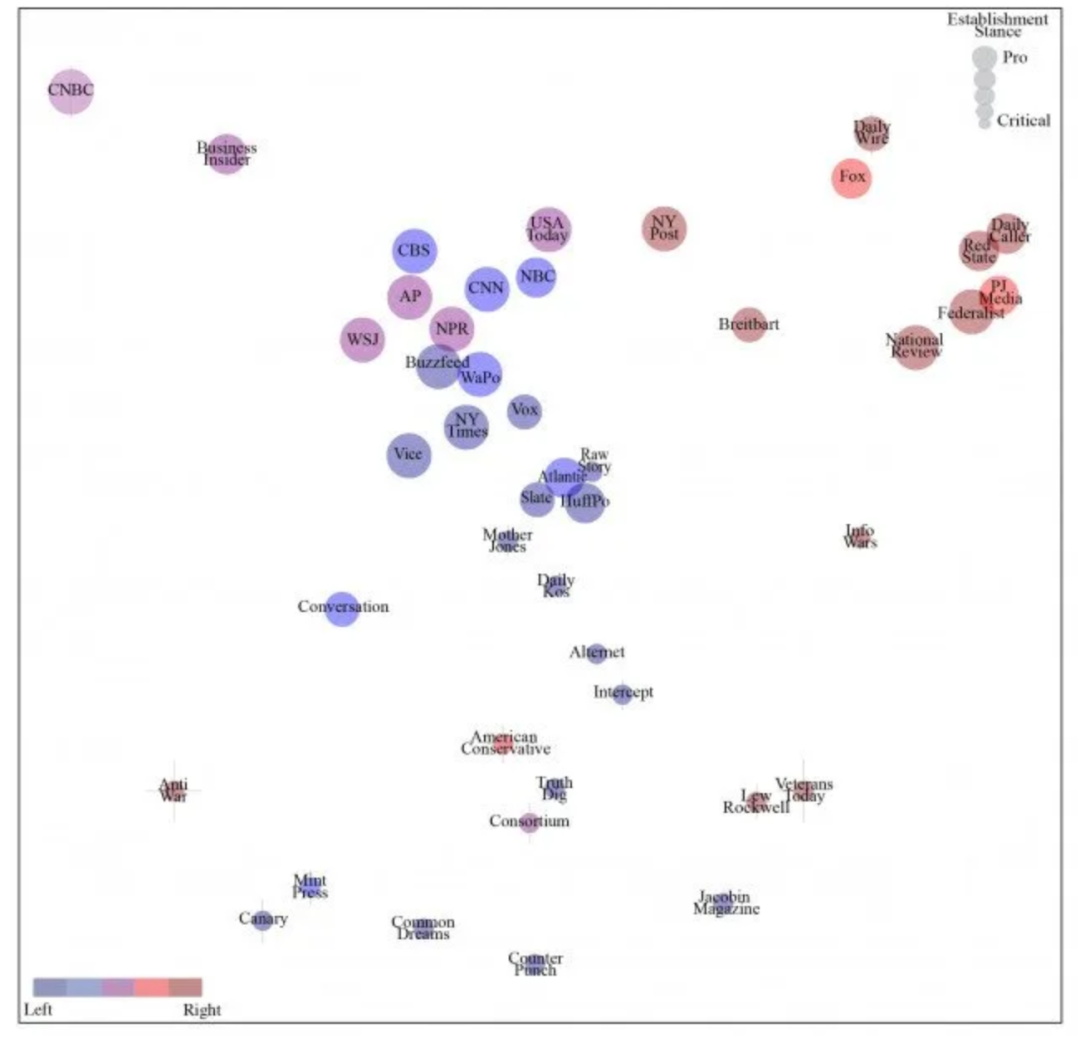
被隐藏的可关注性
尽管该论文的日期为 9 月 2 日并于 2021 年 8 月末发表,但其获得的关注度还是相对较小。部分原因可能是因为针对主流媒体的批判性研究不太可能被它们自己热情接受;但也可能是由于作者不愿制作清晰明确的图表,把有影响力的媒体出版物在各种问题上的立场分层,以表明出版物左倾或右倾的程度。实际上,作者似乎在努力抑制该结果潜在的煽动性影响。
同样,该项目发布的大量数据显示了单词出现的频率计数,但似乎是匿名的,因此很难清楚地了解其所研究的出版物中的媒体偏见。如果该项目不被付诸实践,就会只剩下论文中介绍的选定示例。
如果他们不仅要考虑用于主题的措辞,还考虑该主题是否被涵盖,那么其后期研究可能会更有用。无声胜有声,本身明显的政治特征不仅仅取决于预算限制或其他可能影响新闻选择的现实因素。
尽管如此,麻省理工学院的研究似乎是迄今为止同类研究中规模最大的,并且可以形成未来分类系统的框架,甚至有益于诸如浏览器插件之类的技术。这些技术可能会提醒普通读者,注意他们正在阅读的的出版物的政治色彩。
泡沫、偏见和反冲
此外,还必须考虑这样的系统是否会进一步加剧算法推荐系统最具争议的方面之一——将观众引导到没有相反意见或具有挑战性观点的环境的趋势,这可能会进一步减弱读者在核心问题上的立场。
这样的内容泡沫是否是一种“安全环境”,或是对部分宣传的保护,是一种价值判断——一个从机器学习系统的机械、统计角度很难接近的哲学问题。
尽管麻省理工学院的研究煞费苦心地让数据来定义结果,但不可避免的是,对短语政治价值的分类也是一种价值判断。一旦语言在新的短语中产生意义的变动,且这种变动超出了该研究的手册、规则和数据库,那么机器也就很难对其进行处理。
如果这种语言的意义变动出现在常见的线上系统中,那么绘制主要新闻媒体道德和政治偏向的努力就会陷入困局:为了表达观点,新闻媒体工作者对习语的使用是在不断变化并快速发展的,而这种发展的速度则远超人工智能分辨偏见的能力。
Reference: