
数据流转(Nifi续)
资料信息
Recruitment
文档集合:http://nifi.apache.org/docs/nifi-docs/html/
总览介绍:http://nifi.apache.org/docs/nifi-docs/html/overview.html
详细文档地址; https://nifi.apache.org/docs.html
快速开始:http://nifi.apache.org/docs/nifi-docs/html/getting-started.html
深入指南:http://nifi.apache.org/docs/nifi-docs/html/nifi-in-depth.html
表达式语言指南:http://nifi.apache.org/docs/nifi-docs/html/expression-language-guide.html
RecordPath指南:http://nifi.apache.org/docs/nifi-docs/html/record-path-guide.html
管理员指南:http://nifi.apache.org/docs/nifi-docs/html/administration-guide.html
指南补充(安装、构建、部署、配置):http://nifi.apache.org/docs/nifi-docs/html/walkthroughs.html
工具文档:http://nifi.apache.org/docs/nifi-docs/html/toolkit-guide.html
开发者指南:http://nifi.apache.org/docs/nifi-docs/html/developer-guide.html

上一篇数据流转(处理与分发)着重介绍了Nifi的背景,从大的轮廓了解Nifi的一些功能和特性以及方向上的用途,了解一下Nifi的整体架构与版本历史,这一篇着重更细节的内容深入一点补充。
01
安全
Nifi支持客户端证书、Apache Knox、OpenId Connect、密码认证:ldap-provider 、kerberos-provider、自定义等多种方式。
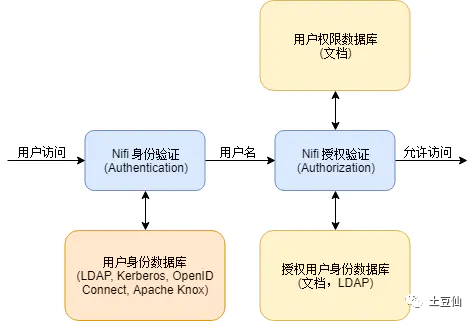
对权限熟悉的,很容易区分,本质上就是两步走,身份认证,权限分配。
这里以简单的配置Https+自定义认证简单处理,有条件可以接入公司的Ldap系统认证。
1.1下载工具wget https://mirrors.tuna.tsinghua.edu.cn/apache/nifi/1.13.2/nifi-toolkit-1.13.2-bin.tar.gz1.2 生成证书文件进入toolkit主目录下,执行./bin/tls-toolkit.sh standalone-n '域名','IP地址,如果前面的单引号填了域名,这里也可以忽略,具体原因如上述'-O -S '替换成你想设置的truststore密码'-P '设置一个keystore密码'-c 'hostname of NiFi Certificate Authority (default: localhost)'生成两个目录,区别在于nifi.properties里的host的值一个是域名,一个是IP,选其中一个就好了,推荐选域名那个目录,这样IP就不会暴露,没条件Ip也可以。1.3将文件移动到相应的位置生成Keystore.jks,Truststore.jks,nifi.properties移动到NIFI的./conf目录下(注:如果./conf路径下已经有nifi.properties,对比一下是否还要保留,保留的话需要自己配置nifi.properties里的信息,建议不保留直接覆盖,然后根据自己的需求修改nifi.properties里的其他信息,比如集群的相关配置信息)2.1自定义身份认证在nifi-ldap-iaa-providers添加CustomLoginIdentityProvider实现LoginIdentityProvider接口,自定义认证逻辑。resource下的org.apache.nifi.authentication.LoginIdentityProvider文件添加CustomLoginIdentityProvider打成Nar包,替换线上Nifi的lib中的包。重启2.2 配置认证修改nifi.properties#自定义provider配置nifi.security.user.login.identity.provider=custom-provider修改login-identity-providers.xml添加<provider><identifier>custom-provider</identifier><class>org.apache.nifi.authentication.CustomLoginIdentityProvider</class></provider>2.3权限修改authorizers.xml<userGroupProvider><identifier>file-user-group-provider</identifier><class>org.apache.nifi.authorization.FileUserGroupProvider</class><property name="Users File">./conf/users.xml</property><property name="Legacy Authorized Users File"></property><!-- 添加root --><property name="Initial User Identity 1">root</property></userGroupProvider><accessPolicyProvider><identifier>file-access-policy-provider</identifier><class>org.apache.nifi.authorization.FileAccessPolicyProvider</class><property name="User Group Provider">file-user-group-provider</property><property name="Authorizations File">./conf/authorizations.xml</property><!-- 添加root --><property name="Initial Admin Identity">root</property><property name="Legacy Authorized Users File"></property><property name="Node Identity 1"></property><property name="Node Group"></property></accessPolicyProvider>3.重启,登录
02
处理器介绍
上一文已经讲过,对于nifi最关键的莫过于Processor,有多少种Processor,Nifi就有多少功能。但是对于官方实现的280多种,我们还是有点不知从何下手的。更别说如何巧妙的组合使用,都是需要时间研究的。
以下是个人对processor的分类
一、数据源交互
1.emails交互
PutEmail、ConsumeIMAP、ConsumePOP3、ListenSMTP、ExtractEmailAttachments、ExtractEmailHeaders
2.http交互
GetHTTP、PostHTTP、ListenHTTP、InvokeHTTP、HandleHttpRequest / HandleHttpResponse
3.JMS交互
GetJMSQueue、GetJMSTopic、PutJMS、ConsumeJMS
GetKafka、PutKafka、ConsumeKafka、ConsumeKafkaRecord
ConsumeAMQP、ConsumeMQTT(消息队列遥测传输)、PublishAMQP、PublishMQTT
4.Mysql交互
QueryDatabaseTable : 数据库查询处理器, 支持: mysql
QueryDatabaseTableRecord
GenerateTableFetch
ListDatabaseTables
CaptureChangeMySQL : 从MySQL数据库中检索更改数据捕获(CDC)事件。CDC事件包括INSERT,UPDATE,DELETE操作。事件作为单个流文件输出,这些文件按操作发生的时间排序。
GenerateTableFetch 生成表分段查询语句,可做监听增量
ExecuteSQL:执行用户定义的SQL SELECT命令,结果为Avro格式的FlowFile
ExecuteSQLRecord:执行用户定义的SQL
PutSQL:通过执行FlowFile内容定义的SQL DDM语句来更新数据库
5.Hive、Hbase
SelectHiveQL:对Apache Hive数据库执行用户定义的HiveQL SELECT命令,结果为Avro或CSV格式的FlowFile
PutHiveQL:通过执行FlowFile内容定义的HiveQL DDM语句来更新Hive数据库
6.HDFS
GetHDFS 、PutHDFS 、ListHDFS / FetchHDFS、PutParquet、FetchParquet、DeleteHDFS、ListHDFS
FetchParquet(列存存储的文件格式,Hadoop)
7.File
GetFile、PutFile、FetchFile、ListFile、TailFile
8.FTP、SFTP
GetFTP、GetSFTP、PutFTP、PutSFTP、FetchFTP、FetchSFTP、ListFTP、ListSFTP
9.TCP、UDP、tSNMP、SmbFile
ListenUDP、GetTCP、ListenTCP、ListenTCPRecord、ListenUDP、ListenUDPRecord
10.缓存数据源Redis、MongoDB、IgniteCache
GetMongo、PutMongo、FetchGridFS(分布式文件系统)
FetchDistributedMapCache、PutDistributedMapCache
11.InfluxDB、Elasticsearch、Solr
ExecuteInfluxDBQuery
FetchElasticsearch、FetchElasticsearchHttp、JsonQueryElasticsearch、ScrollElasticsearchHttp、QueryElasticsearchHttp
GetSolr、QuerySolr
12.WebSocket
ConnectWebSocket、ListenWebSocket
13.GRPC(1.12.1有=》1.13.1无)
InvokeGRPC =>参考支持dubbo
ListenGRPC
14.亚马逊、微软、谷歌
1.亚马逊
DynamoDB(NoSQL数据库服务)、S3Object(对象储存)、SQS(消息队列)、AWSGatewayApi(网关API)
2.谷歌
GCPubSub(谷歌消息组件)、GCSObject(谷歌对象储存)
3.微软
ConsumeAzureEventHub、DeleteAzureDataLakeStorage、ConsumeWindowsEventLog、ConsumeEWS
15.其他数据库
KUDU、RethinkDB(mysql分支)、Splunk(数据搜集引擎)、Twitter、ListenBeats、ListenRELP、QueryDNS
二、数据提取加工转换分裂与聚合处理
1.提取
EvaluateJsonPath : 根据FlowFile的内容评估一个或多个JsonPath表达式。这些表达式的结果将分配给FlowFile属性,或者写入FlowFile本身的内容,具体取决于处理器的配置。
EvaluateXPath:用户提供XPath表达式,然后根据XML内容评估这些表达式,用结果值替换FlowFile内容或将结果值提取到用户自己命名的Attribute中。
EvaluateXQuery:用户提供XQuery查询,然后根据XML内容评估此查询,用结果值替换FlowFile内容或将结果值提取到用户自己命名的Attribute中。
ExtractText:用户提供一个或多个正则表达式,然后根据FlowFile的文本内容对其进行评估,然后将结果值提取到用户自己命名的Attribute中。
ExtractAvroMetadata
ExtractCCDAAttributes
GetHTMLElement、ModifyHTMLElement
LookupAttribute
LookupRecord
ModifyBytes
GeoEnrichIP、GeoEnrichIPRecord、ISPEnrichIP =》参考支持本土ip解析
其他:ExtractGrok、ExtractHL7Attributes、ExtractTNEFAttachments
2.转换
JoltTransformJSON:应用JOLT规范来转换JSON内容
FlattenJson 复杂多层次结构的json 平铺成 key-value形式的json
ConvertAvroToJSON、ConvertJSONToAvro : avro 数据格式与 json格式互转
TransformXml:应用XSLT转换XML内容
ScriptedTransformRecord:使用脚本处理格式转换
ConvertCharacterSet:将用于编码内容的字符集从一个字符集转换为另一个字符集
ConvertJSONToSQL:将JSON文档转换为SQL INSERT或UPDATE命令,然后可以将其传递给PutSQL Processor
ConvertRecord:通过指定Reader和Writer的类型,完成文件格式转换
JoltTransformRecord:转成Json
AttributesToJSON 将若干attribute转成json 到输出流文件 属性或内容
AttributesToCSV 将若干attribute转成csv 到输出流文件 属性或内容
ConvertExcelToCSVProcessor
其他ConvertAvroToORC、ConvertAvroToParquet、ConvertCharacterSet、ParseCEF、ParseEvtx、ParseNetflowv5、ParseSyslog
3.加工
ReplaceText : 文本组装与替换, 支持正则表达式
ReplaceTextWithMapping
UpdateAttribute:向FlowFile添加或更新任意数量的用户定义的属性。这对于添加静态的属性值以及使用表达式语言动态计算出来的属性值非常有用。该处理器还提供"高级用户界面(Advanced User Interface)",允许用户根据用户提供的规则有条件地去更新属性。
UpdateCounter、UpdateRecord
HashContent:对FlowFile的内容进行hash,并将得到的hash值添加到Attribute中。
HashAttribute:对用户定义的现有属性列表的串联进行hash。
4.分裂与聚合
1.分
SplitJson : 将JSON文件拆分为多个单独的FlowFiles, 用于由JsonPath表达式指定的数组元素。
SplitText:SplitText接收单个FlowFile,其内容为文本,并根据配置的行数将其拆分为1个或多个FlowFiles。例如,可以将处理器配置为将FlowFile拆分为多个FlowFile,每个FlowFile只有一行。
SplitXml:允许用户将XML消息拆分为多个FlowFiles,每个FlowFiles包含原始段。这通常在多个XML元素与"wrapper"元素连接在一起时使用。然后,此处理器允许将这些元素拆分为单独的XML元素。
SplitContent:将单个FlowFile拆分为可能的许多FlowFile,类似于SegmentContent。但是,对于SplitContent,不会在任意字节边界上执行拆分,而是指定要拆分内容的字节序列。
SplitAvro 切分avro数组
ForkRecord:切分
SplitRecord
PartitionRecord
SegmentContent:根据某些已配置的数据大小将FlowFile划分为可能的许多较小的FlowFile。不对任何类型的分界符执行拆分,而是仅基于字节偏移执行拆分。这是在传输FlowFiles之前使用的,以便通过并行发送许多不同的部分来提供更低的延迟。而另一方面,MergeContent处理器可以使用碎片整理模式重新组装这些FlowFiles。
2.合
MergeContent:此处理器负责将许多FlowFiles合并到一个FlowFile中。可以通过将其内容与可选的页眉,页脚和分界符连接在一起,或者通过指定存档格式(如ZIP或TAR)来合并FlowFiles。FlowFiles可以根据公共属性进行分箱(binned),或者如果这些流是被其他组件拆分的,则可以进行"碎片整理(defragmented)"。根据元素的数量或FlowFiles内容的总大小(每个bin的最小和最大大小是用户指定的)并且还可以配置可选的Timeout属性,即FlowFiles等待其bin变为配置的上限值最大时间。
MergeRecord
三、路由与调解、校验
DetectDuplicate:根据一些用户定义的标准去监视发现重复的FlowFiles。通常与HashContent一起使用
DistributeLoad:通过只将一部分数据分发给每个用户定义的关系来实现负载平衡或数据抽样
RetryFlowFile:重试
ControlRate:限制流程中数据流经某部分的速率
EnforceOrder:顺序
MonitorActivity:当用户定义的时间段过去而没有任何数据流经此节点时发送通知。(可选)在数据流恢复时发送通知
RouteOnAttribute:根据FlowFile包含的属性路由FlowFile。
RouteOnContent:根据FlowFile的内容是否与用户自定义的正则表达式匹配。如果匹配,则FlowFile将路由到已配置的关系。
RouteText:根据文本路由
RouteHL7:
ScanAttribute:扫描FlowFile上用户定义的属性集,检查是否有任何属性与用户定义的字典匹配。
ScanContent:在流文件的内容中搜索用户定义字典中存在的术语,并根据这些术语的存在或不存在来路由。字典可以由文本条目或二进制条目组成。
ValidateXml:以XML模式验证XML内容; 根据用户定义的XML Schema,判断FlowFile的内容是否有效,进而来路由FlowFile。
ValidateRecord
ValidateCsv
IdentifyMimeType:评估FlowFile的内容,以确定FlowFile封装的文件类型。此处理器能够检测许多不同的MIME类型,例如图像,文字处理器文档,文本和压缩格式,仅举几例。
其他:QueryWhois、QueryRecord
四、特殊操作类
1.日志类
LogMessage: 打日志信息
LogAttribute: 将属性打印到日志中
ListenSyslog
2.加密类
EncryptContent:加密或解密
CryptographicHashAttribute
CryptographicHashContent
FuzzyHashContent、CompareFuzzyHash
Base64EncodeContent
HashAttribute、HashContent(重要)
3.统计
CalculateRecordStats
CountText
4.压缩
CompressContent:压缩或解压
UnpackContent:解压缩不同类型的存档格式,例如ZIP和TAR。然后,归档中的每个文件都作为单个FlowFile传输。
5.测试、等待通知
GenerateFlowFile、DebugFlow、Wait、Notify、SpringContextProcessor
五、系统交互与脚本
1.系统交互
ExecuteProcess:运行用户自定义的操作系统命令。进程的StdOut被重定向,以便StdOut的内容输出为FlowFile的内容。此处理器是源处理器(不接受数据流输入,没有上游组件) - 其输出预计会生成新的FlowFile,并且系统调用不会接收任何输入。如果要为进程提供输入,请使用ExecuteStreamCommand Processor。
2.执行脚本
ExecuteStreamCommand : 一般用于执行sh脚本
ExecuteScript : 执行脚本处理器, 支持: clojure, ecmascript, groovy, lua, python, ruby
ExecuteGroovyScript 执行groovy脚本
InvokeScriptedProcessor
从以上可以看出,Nifi在国外用的比较多,对于微软、亚马逊、谷歌等都有支持,而对于国内阿里云、七牛云、华为云、腾讯云,甚至对象储存Minio,国内的Dubbo、RocketMq等都还没支持。都需要自定义Processor适配扩展。
03
自定义Processor
一. 插件原理
知其然,更要知其所以然
面试时,面试官总喜欢问抽象类和接口的区别,类加载过程。一旦面试者回答一二三四五六把面试题背的陈列出来,面试官微微一笑,小伙子还可以。一旦没有教条式的列全,面试官心里就嘀咕了,小伙子不行呀。其实教条式没什么用,版本升级一下,也许你以前回答对的面试题,现在就错了。知道它是什么,用来干什么,作者为什么这么设计才是最重要的。
回到插件模式,对于设计模式比较熟悉的,很容易联想到策略设计模式(眼熟策略设计模式、模板设计模式、观察者模式,无处不在),本质上没什么区别,策略设计模式是在类级别不同策略实现约定的接口,而插件模式在系统级别不同插件实现约定的规范。
策略模式 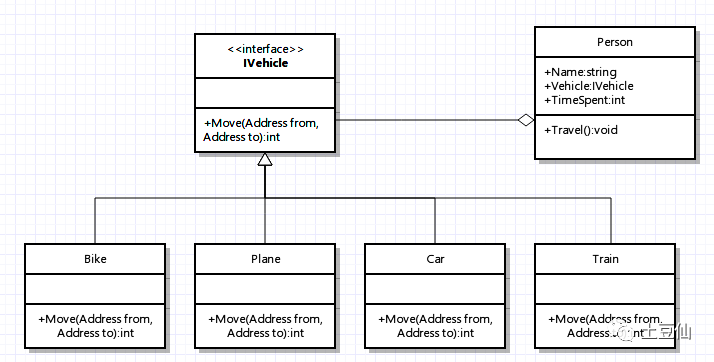
插件模式
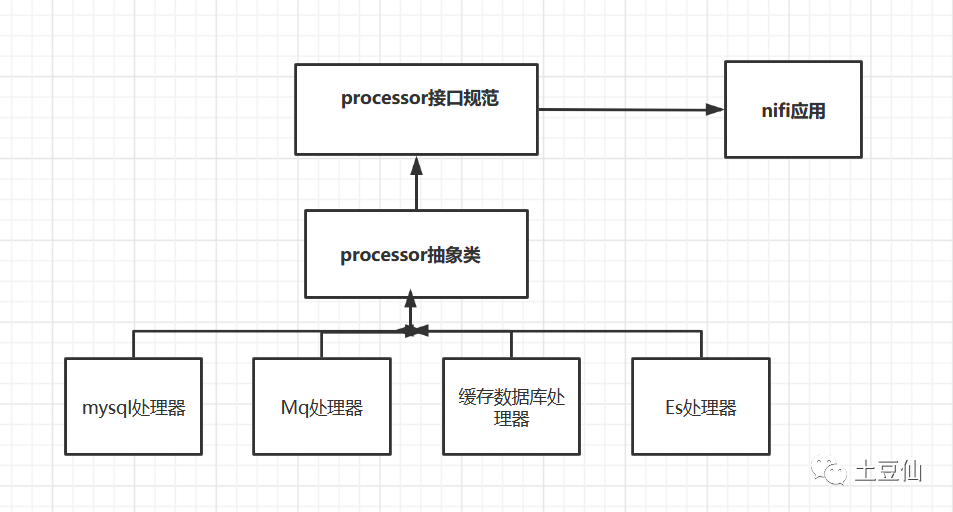
插件化在Java中主要实现过程
抽离出插件功能接口,定义插件的抽象类;
实现具体功能的插件实现插件抽象类,然后将该具体的插件打成JAR包,并将JAR包放到指定的插件目录下;
创建插件配置文件,可以使用JSON格式或者XML格式的文件,每当新增一个插件后,在配置文件中添加一条该插件的信息,该信息主要包括“插件名称(jar包名称)”和“插件主类的完整路径(包名类名)”。
主程序中首先解析插件配置文件,得到插件名称和插件主类的路径,然后获取插件的jar所在的URL,通过URLClassLoader得到插件的类加载器,最后通过类加载器即可得到对应的插件类的实例。
这里需要回顾一下Java的类加载机制:
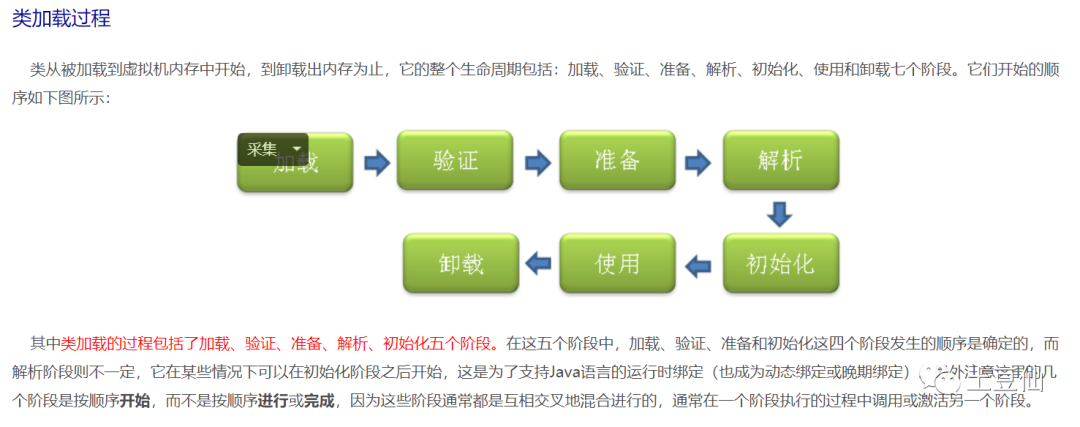
插件模式首先需要关注加载过程:
加载时类加载过程的第一个阶段,在加载阶段,虚拟机需要完成以下三件事情:
1、通过一个类的全限定名来获取其定义的二进制字节流。
(可以从Jar包中获取、从网络中获取(最典型的应用便是Applet)、由其他文件生成(JSP应用)等)
可以使用系统提供的类加载器来完成加载,也可以自定义自己的类加载器来完成加载。
对于任意一个类,都需要由它的类加载器和这个类本身一同确定其在就Java虚拟机中的唯一性,也就是说,即使两个类来源于同一个Class文件,只要加载它们的类加载器不同,那这两个类就必定不相等。这里的“相等”包括了代表类的Class对象的equals()、isAssignableFrom()、isInstance()等方法的返回结果,也包括了使用instanceof关键字对对象所属关系的判定结果。
2、将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
3、在Java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口。
从加载过程,我们大致能分析出,插件化,可以使用ClassLoader加载Jar包,其中类可能相同,为了避免冲突,所以需要不同的ClassLoader进行加载,做到Jar隔离。至于什么时候加载,如何去重,如何升级,如何使用,如何卸载都是值得看一看的。
分析成熟软件的做法:
1.Nifi的做法
final Bundle systemBundle = SystemBundle.create(properties, rootClassLoader);// 加载默认配置的nifi.nar.library.directory=./lib 的nars//加载默认配置的nifi.nar.working.directory=./work/nar/framework//加载默认配置的nifi.nar.working.directory=./work/nar/extensions//加载默认配置的//加载默认配置的nifi.nar.working.directory=./work/nar/extensions=./work/docs/componentsfinal ExtensionMapping extensionMapping = NarUnpacker.unpackNars(properties, systemBundle);// load the extensions classloadersNarClassLoaders narClassLoaders = NarClassLoadersHolder.getInstance();narClassLoaders.init(rootClassLoader,properties.getFrameworkWorkingDirectory(), properties.getExtensionsWorkingDirectory());// load the framework classloaderfinal ClassLoader frameworkClassLoader = narClassLoaders.getFrameworkBundle().getClassLoader();if (frameworkClassLoader == null) {throw new IllegalStateException("Unable to find the framework NAR ClassLoader.");}final Set<Bundle> narBundles = narClassLoaders.getBundles();
以上代码只是加载过程,至于使用过程和后续处理流程还有什么亮点,以后再看。因此我们自定义processor,只需要和其他模块一样。打成nar放入./lib目录即可。
2.Datax的做法
Datax读取插件的Json配置,根据配置路径加载Jar,反射创建执行实例。很普遍的写法。
3.serviceloader和SPI机制
ServiceLoader是实现SPI一个重要的类。为了解决接口与实现分离的场景。在资源目录META-INF/services中放置提供者配置文件,文件名以接口的类名命名,里面的内容为需要加载的实现类。然后在app运行时,遇到Serviceloader.load(XxxInterface.class)时,会到META-INF/services的配置文件中寻找这个接口对应的实现类全路径名,使用Class.forName()(传入设定的类加载器)完成类的加载。SpringBoot、Dubbo甚至JDBC加载都以集成了这种SPI机制。
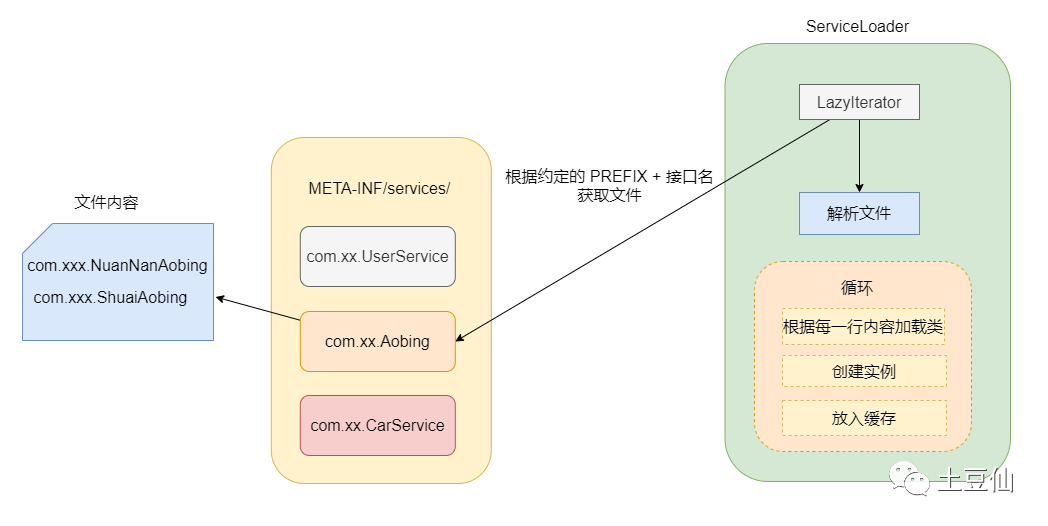
4.Dubbo的SPI机制
Java SPI 在查找扩展实现类的时候遍历 SPI 的配置文件并且将实现类全部实例化,假设一个实现类初始化过程比较消耗资源且耗时,但是你的代码里面又用不上它,这就产生了资源的浪费。
Dubbo 实现自定义的一套SPI,实现按需加载实现类,增加了 IOC 和 AOP 的特性,以及自适应扩展机制(根据请求时候的参数来动态选择对应的扩展。)。依靠 SPI 机制实现了插件化功能,几乎将所有的功能组件做成基于 SPI 实现,并且默认提供了很多可以直接使用的扩展点,实现了面向功能进行拆分的对扩展开放的架构。
根据请求时候的参数来动态选择对应的扩展。
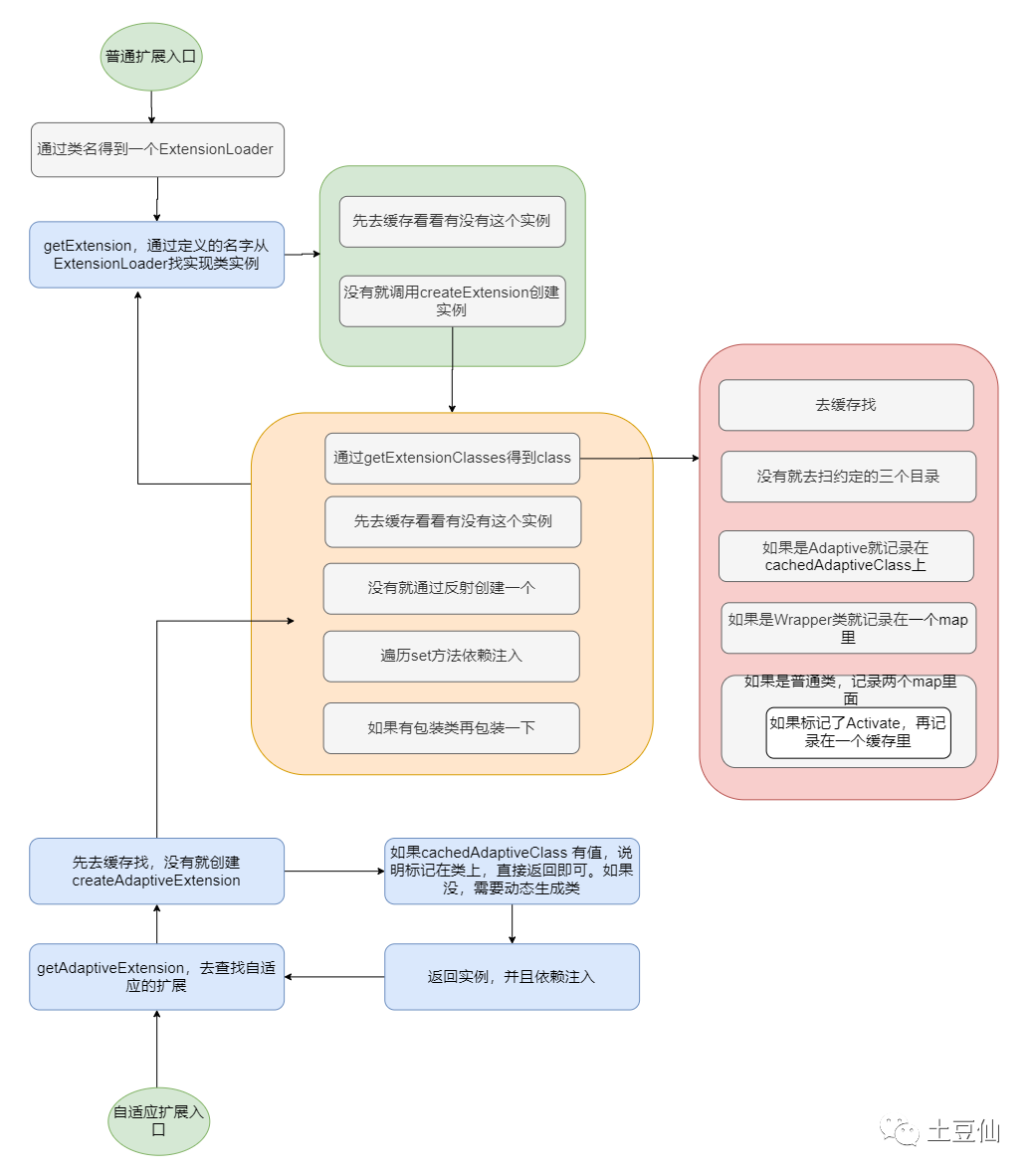
如何更好的实现扩展机制,是可以深度总结的一个分类,甚至不局限于Java领域,毕竟,插件机制在Java中感觉还是步骤冗余很多(主要是避免类冲突)。这里简单了解,以后深入。
二.自定义processor实现
打包上传到Nifi项目的lib包下。重起。
04
使用例子
1.Mysql同步
这里有两个点,一个Binlog同步知识(需开启Binlog和GTID模式),一个Jolt处理Json格式数据知识。
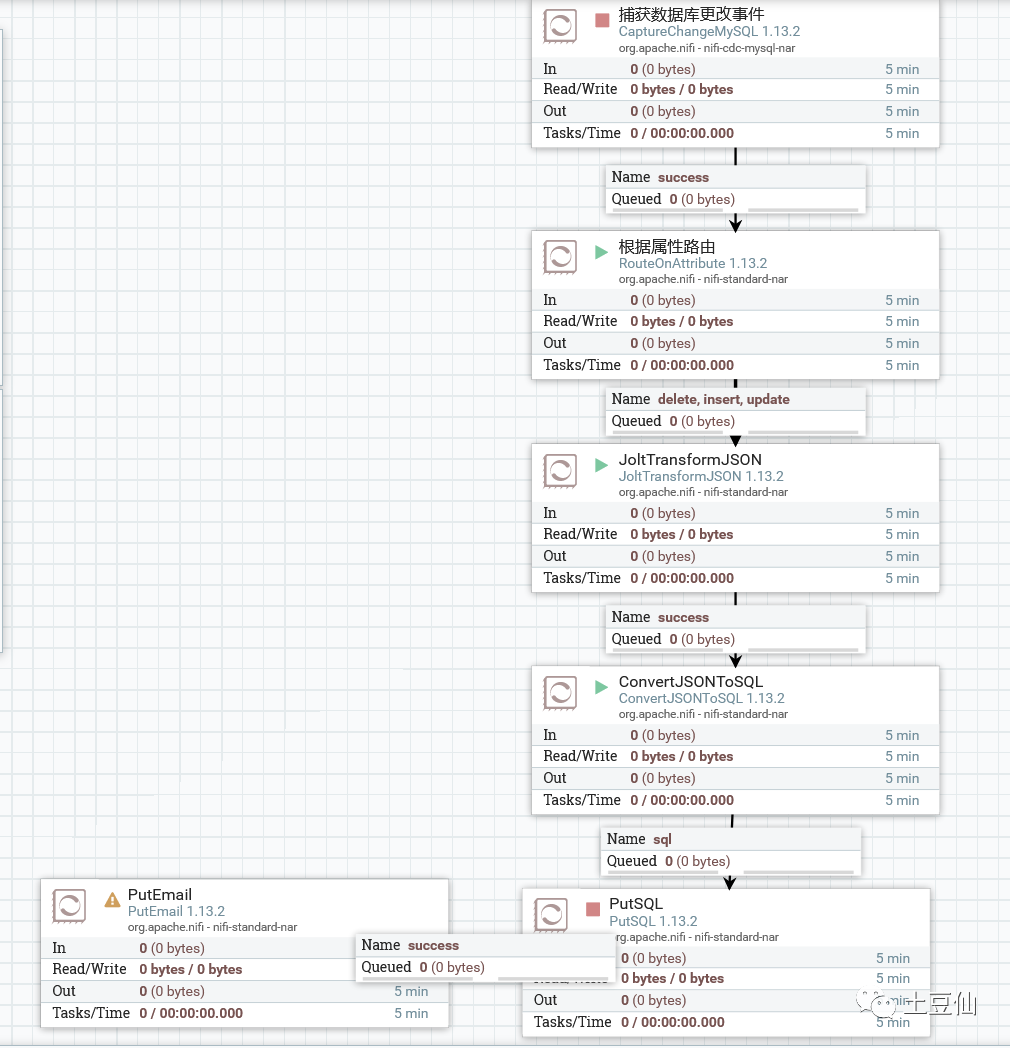
简单的查询插入
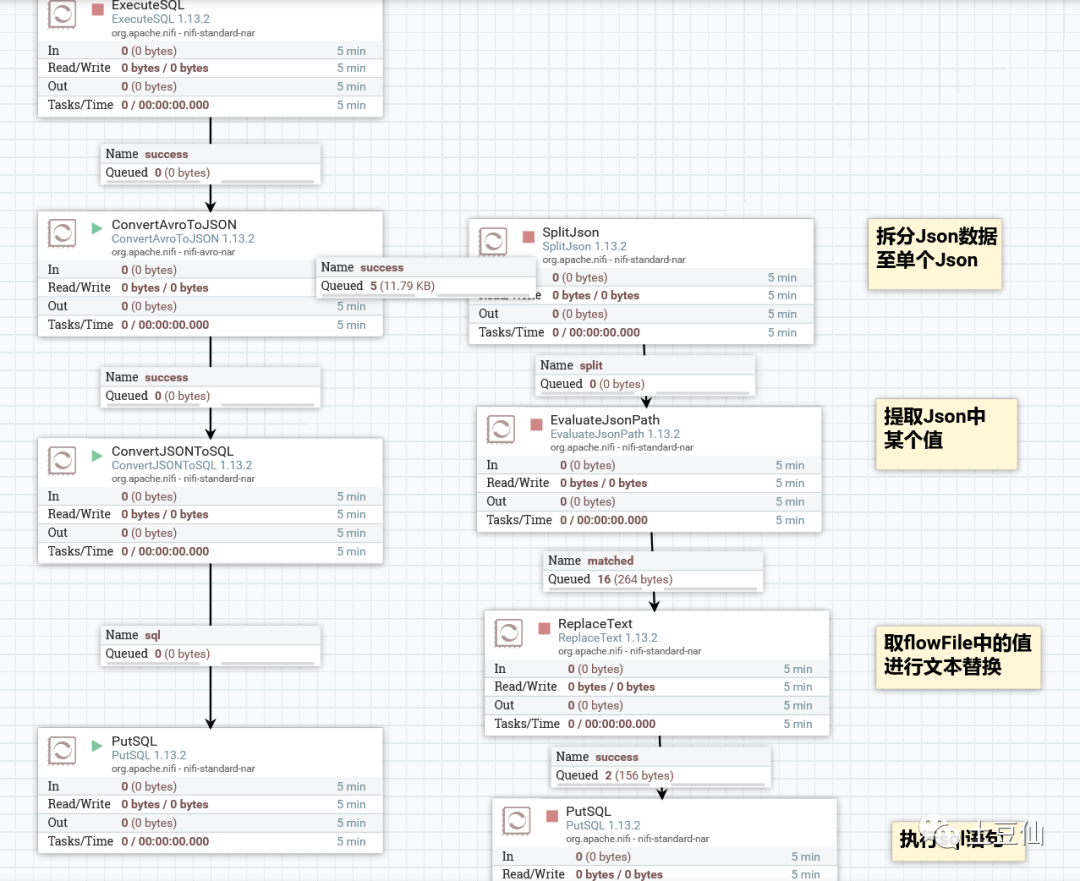
2.以Nifi优化地址信息提取过程
(略,实践中)
05
优缺点分析
优点:
上一篇已经讲解很多。我个人最喜欢的无非两点:可视化配置、插件化机制。这是我这一年的技术课题。
缺点:
上篇对于缺点讲得很少,这里重点分析,首先界面外观一般、Processors看起来有近300个,但丰富度总感觉不够,不支持国内生态,比如对象储存不支持七牛云、阿里云还不支持Minio等,数据源不支持dubbo,缓存Processor比如Redis操作性还不够,错误日志展示不友好。