
【统计学习方法】 第4章 朴素贝叶斯法(二)
点击上方“公众号”可订阅哦!
这篇文章主要介绍使用sklearn开源库,实现三种朴素贝叶斯算法。
常用的三种朴素贝叶斯为:
高斯朴素贝叶斯
伯努利朴素贝叶斯
多项式朴素贝叶斯
1
●
高斯朴素贝叶斯
适用于连续变量,其假定各个特征xi在各个类别y下是服从正态分布的,算法内部使用正态分布的概率密度函数来计算概率如下:
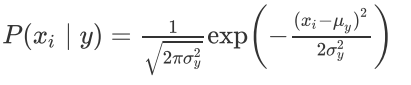

代码演示:
import numpy as npimport pandas as pdfrom sklearn.naive_bayes import GaussianNBnp.random.seed(0)# 当我们预先使用 random.seed(x) 设定好种子之后,# 其中的 x 可以是任意数字,如10,这个时候,先调用它的情况下,# 使用 random() 生成的随机数将会是同一个x = np.random.randint(0,10,size=(6,2))y = np.array([0,0,0,1,1,1])data = pd.DataFrame(np.concatenate([x, y.reshape(-1,1)], axis=1), columns=['x1','x2','y'])# pd.DataFrame,主要包含三个参数,data=数据, index=行名称, columns=列名称# y.reshape(-1,1) 把y变成只有一列,行数Numpy自动计算出来display(data)gnb = GaussianNB()gnb.fit(x,y)#每个类别的先验概率print('概率:', gnb.class_prior_)#每个类别样本的数量print('样本数量:', gnb.class_count_)#每个类别的标签print('标签:', gnb.classes_)#每个特征在每个类别下的均值print('均值:',gnb.theta_)#每个特征在每个类别下的方差print('方差:',gnb.sigma_)#测试集x_test = np.array([[6,3]])print('预测结果:', gnb.predict(x_test))print('预测结果概率:', gnb.predict_proba(x_test))
输出:
| x1 | x2 | y | |
|---|---|---|---|
| 0 | 5 | 0 | 0 |
| 1 | 3 | 3 | 0 |
| 2 | 7 | 9 | 0 |
| 3 | 3 | 5 | 1 |
| 4 | 2 | 4 | 1 |
| 5 | 7 | 6 | 1 |
概率:[0.5 0.5]
样本数量:[3. 3.]
标签:[0 1]
均值:[[5. 4.]
[4. 5.]]
方差:[[ 2.66666667 14.00000001]
[ 4.66666667 0.66666667]]
预测结果:[0]
预测结果概率:[[0.87684687 0.12315313]]2
●
伯努利朴素贝叶斯
设试验E只有两个可能的结果:A与A¯,则称为E为伯努利试验。
伯努利朴素贝叶斯,适用于离散变量,其假设各个特征xi在各个类别y下是服从n重伯努利分布(二项分布)的,因为伯努利试验仅有两个结果,因此,算法会首先对特征值进行二值化处理(假设二值化的结果为1与0)。
计算方式如下:
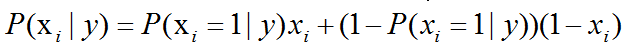
在训练集中,会进行如下的估计:
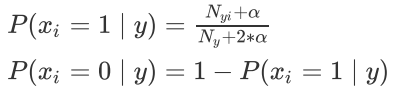

代码演示:
from sklearn.naive_bayes import BernoulliNBnp.random.seed(0)x = np.random.randint(-5,5,size=(6,2))y = np.array([0,0,0,1,1,1])data = pd.DataFrame(np.concatenate([x,y.reshape(-1,1)], axis=1), columns=['x1','x2','y'])display(data)bnb = BernoulliNB()bnb.fit(x,y)#每个特征在每个类别下发生(出现)的次数。因为伯努利分布只有两个值。#我们只需要计算出现的概率P(x=1|y),不出现的概率P(x=0|y)使用1减去P(x=1|y)即可。print('数值1出现次数:', bnb.feature_count_)#每个类别样本所占的比重,即P(y)。注意该值为概率取对数之后的结果,#如果需要查看原有的概率,需要使用指数还原。print('类别占比p(y):',np.exp(bnb.class_log_prior_))#每个类别下,每个特征(值为1)所占的比例(概率),即p(x|y)#该值为概率取对数之后的结果,如果需要查看原有的概率,需要使用指数还原print('特征概率:',np.exp(bnb.feature_log_prob_))
输出:
| x1 | x2 | y | |
|---|---|---|---|
| 0 | 0 | -5 | 0 |
| 1 | -2 | -2 | 0 |
| 2 | 2 | 4 | 0 |
| 3 | -2 | 0 | 1 |
| 4 | -3 | -1 | 1 |
| 5 | 2 | 1 | 1 |
数值1出现次数:[[1. 1.]
[1. 1.]]
类别占比p(y):[0.5 0.5]
特征概率:[[0.4 0.4]
[0.4 0.4]]3
●
多项式朴素贝叶斯
多项式朴素贝叶斯,适用于离散变量,其假设各个特征xi在各个类别y下是服从多项式分布的,故每个特征值不能是负数。
计算如下:

代码演示:
from sklearn.naive_bayes import MultinomialNBnp.random.seed(0)x = np.random.randint(0,4,size=(6,2))y = np.array([0,0,0,1,1,1])data = pd.DataFrame(np.concatenate([x,y.reshape(-1,1)], axis=1), columns=['x1','x2','y'])display(data)mnb = MultinomialNB()mnb.fit(x,y)#每个类别的样本数量print(mnb.class_count_)#每个特征在每个类别下发生(出现)的次数print(mnb.feature_count_)#每个类别下,每个特征所占的比例(概率),即P(x|y)#该值为概率取对数之后的结果,如果需要查看原有的概率,需要使用指数还原print(np.exp(mnb.feature_log_prob_))
输出:
| x1 | x2 | y | |
|---|---|---|---|
| 0 | 0 | 3 | 0 |
| 1 | 1 | 0 | 0 |
| 2 | 3 | 3 | 0 |
| 3 | 3 | 3 | 1 |
| 4 | 1 | 3 | 1 |
| 5 | 1 | 2 | 1 |
[3. 3.]
[[4. 6.]
[5. 8.]]
[[0.41666667 0.58333333]
[0.4 0.6 ]]
参考来源:
https://blog.csdn.net/ws19920726/article/details/105726570
END

深度学习入门笔记
微信号:sdxx_rmbj
日常更新学习笔记、论文简述
评论