
(附链接)ShuffleNetV2-Yolov5:更轻更快易于部署的yolov5
点击左上方蓝字关注我们

一、消融实验结果比对
| ID | Model | Input_size | Flops | Params | Size(M) | ||
|---|---|---|---|---|---|---|---|
| 001 | yolo-faster | 320×320 | 0.25G | 0.35M | 1.4 | 24.4 | - |
| 002 | nanodet-m | 320×320 | 0.72G | 0.95M | 1.8 | - | 20.6 |
| 003 | shufflev2-yolov5 | 320×320 | 1.43G | 1.62M | 3.3 | 35.5 | - |
| 004 | nanodet-m | 416×416 | 1.2G | 0.95M | 1.8 | - | 23.5 |
| 005 | shufflev2-yolov5 | 416×416 | 2.42G | 1.62M | 3.3 | 40.5 | 23.5 |
| 006 | yolov4-tiny | 416×416 | 5.62G | 8.86M | 33.7 | 40.2 | 21.7 |
| 007 | yolov3-tiny | 416×416 | 6.96G | 6.06M | 23.0 | 33.1 | 16.6 |
| 008 | yolov5s | 640×640 | 17.0G | 7.3M | 14.2 | 55.4 | 36.7 |
| 注:yolov5原FLOPS计算脚本有bug,请使用thop库进行计算: |
input = torch.randn(1, 3, 416, 416)
flops, params = thop.profile(model, inputs=(input,))
print('flops:', flops / 900000000*2)
print('params:', params)
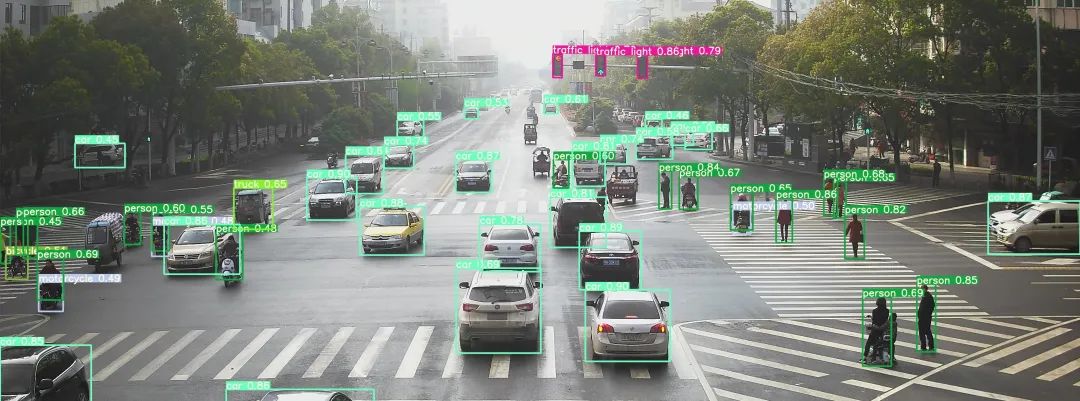
二、检测效果






三、Relect Work
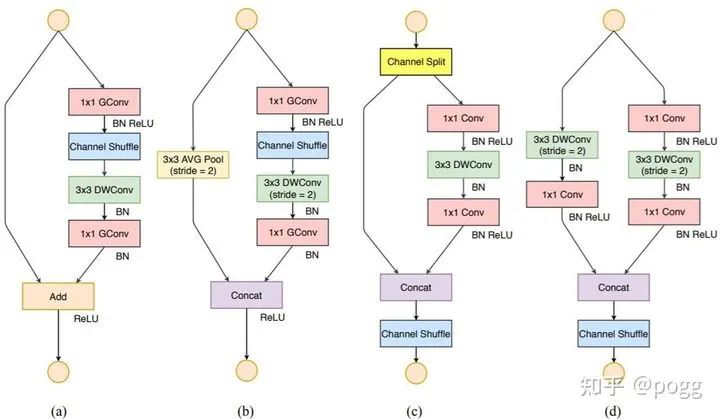
shufflev2-yolov5的网络结构实际上非常简单,backbone主要使用的是含shuffle channel的shuffle block,头依旧用的是yolov5 head,但用的是阉割版的yolov5 head
shuffle block:
yolov5 head:
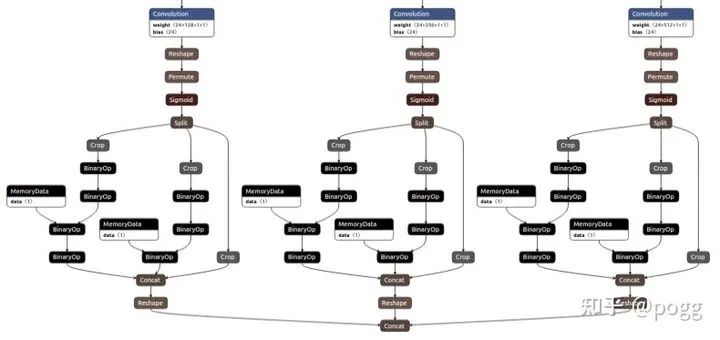
yolov5 backbone:
在原先U版的yolov5 backbone中,作者在特征提取的上层结构中采用了四次slice操作组成了Focus层
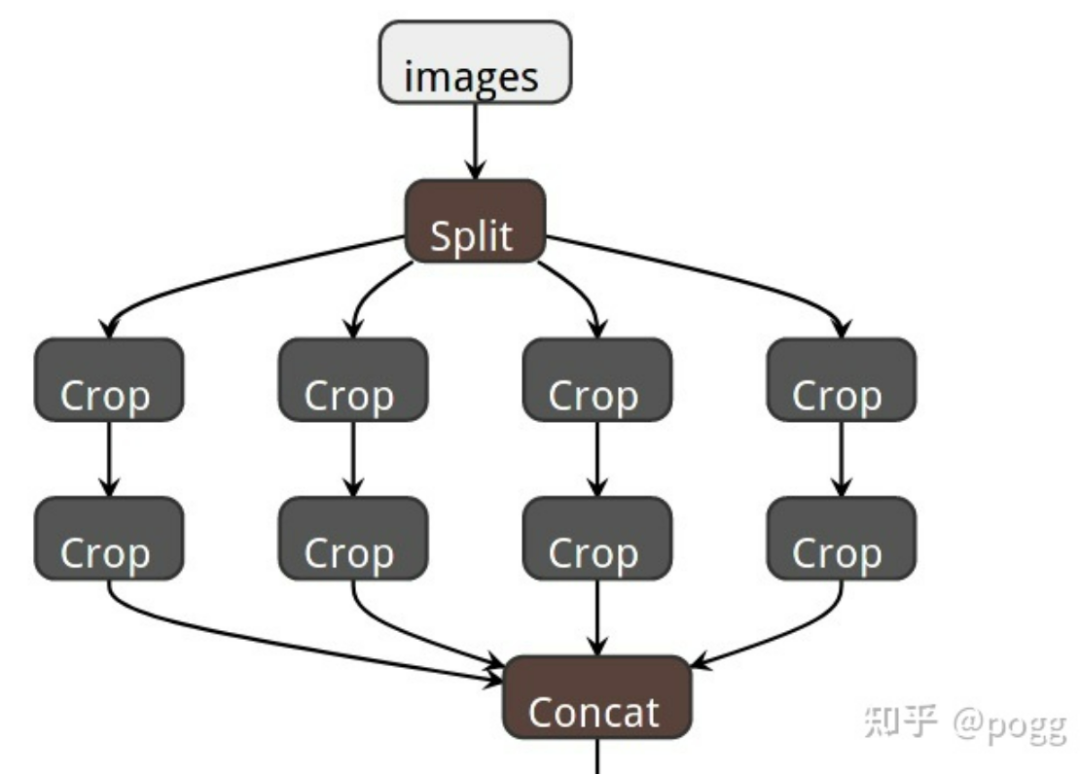
对于Focus层,在一个正方形中每 4 个相邻像素,并生成一个具有 4 倍通道数的feature map,类似与对上级图层进行了四次下采样操作,再将结果concat到一起,最主要的功能还是在不降低模型特征提取能力的前提下,对模型进行降参和加速。
1.7.0+cu101 cuda _CudaDeviceProperties(name='Tesla T4', major=7, minor=5, total_memory=15079MB, multi_processor_count=40)
Params FLOPS forward (ms) backward (ms) input output
7040 23.07 62.89 87.79 (16, 3, 640, 640) (16, 64, 320, 320)
7040 23.07 15.52 48.69 (16, 3, 640, 640) (16, 64, 320, 320)
1.7.0+cu101 cuda _CudaDeviceProperties(name='Tesla T4', major=7, minor=5, total_memory=15079MB, multi_processor_count=40)
Params FLOPS forward (ms) backward (ms) input output
7040 23.07 11.61 79.72 (16, 3, 640, 640) (16, 64, 320, 320)
7040 23.07 12.54 42.94 (16, 3, 640, 640) (16, 64, 320, 320)
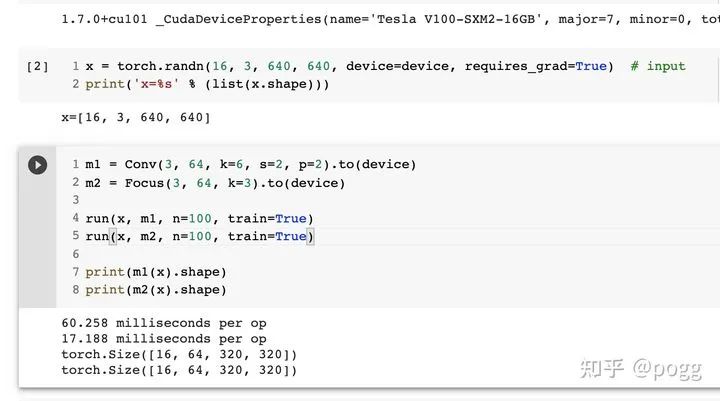 从上图可以看出,Focus层确实在参数降低的情况下,对模型实现了加速。
从上图可以看出,Focus层确实在参数降低的情况下,对模型实现了加速。
但!这个加速是有前提的,必须在GPU的使用下才可以体现这一优势,对于云端部署这种处理方式,GPU不太需要考虑缓存的占用,即取即处理的方式让Focus层在GPU设备上十分work。
对于的芯片,特别是不含GPU、NPU加速的芯片,频繁的slice操作只会让缓存占用严重,加重计算处理的负担。同时,在芯片部署的时候,Focus层的转化对新手极度不友好。
四、轻量化的理念
shufflenetv2的设计理念,在资源紧缺的芯片端,有着许多参考意义,它提出模型轻量化的四条准则:
(G1)同等通道大小可以最小化内存访问量
(G2)过量使用组卷积会增加MAC
(G3)网络过于碎片化(特别是多路)会降低并行度
(G4)不能忽略元素级操作(比如shortcut和Add)
shufflev2-yolov5
设计理念:(G1)摘除Focus层,避免多次采用slice操作
(G2)避免多次使用C3 Leyer以及高通道的C3 Layer
C3 Leyer是YOLOv5作者提出的CSPBottleneck改进版本,它更简单、更快、更轻,在近乎相似的损耗上能取得更好的结果。但C3 Layer采用多路分离卷积,测试证明,频繁使用C3 Layer以及通道数较高的C3 Layer,占用较多的缓存空间,减低运行速度。
(为什么通道数越高的C3 Layer会对cpu不太友好,主要还是因为shufflenetv2的G1准则,通道数越高,hidden channels与c1、c2的阶跃差距更大,来个不是很恰当的比喻,想象下跳一个台阶和十个台阶,虽然跳十个台阶可以一次到达,但是你需要助跑,调整,蓄力才能跳上,可能花费的时间更久)
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
(G3)对yolov5 head进行通道剪枝,剪枝细则参考G1
(G4)摘除shufflenetv2 backbone的1024 conv 和 5×5 pooling
这是为imagenet打榜而设计的模块,在实际业务场景并没有这么多类的情况下,可以适当摘除,精度不会有太大影响,但对于速度是个大提升,在消融实验中也证实了这点。
五、What can be used for?
(G1)训练
这不废话吗。。。确实有点废话了,shufflev2-yolov5基于yolov5第五版(也就是最新版)上进行的消融实验,所以你可以无需修改直接延续第五版的所有功能,比如:
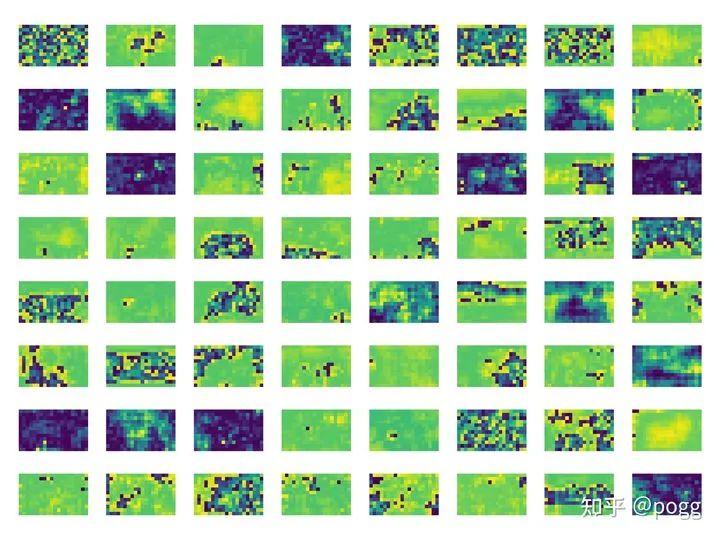
导出热力图:
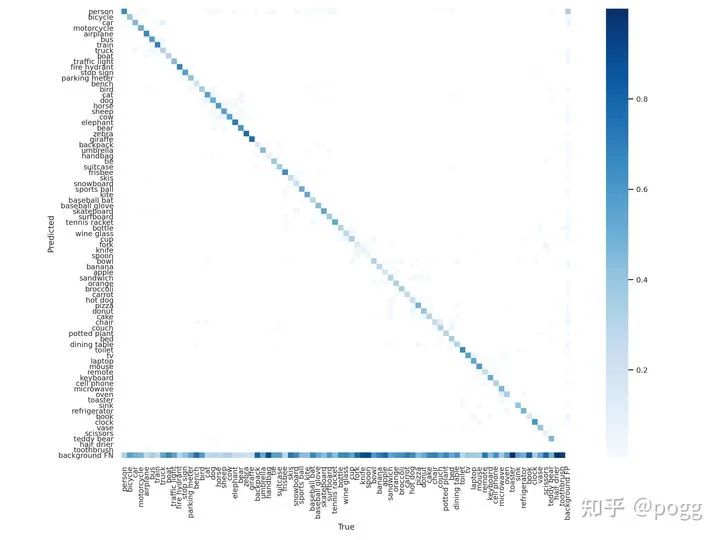
 导出混淆矩阵进行数据分析:
导出混淆矩阵进行数据分析:
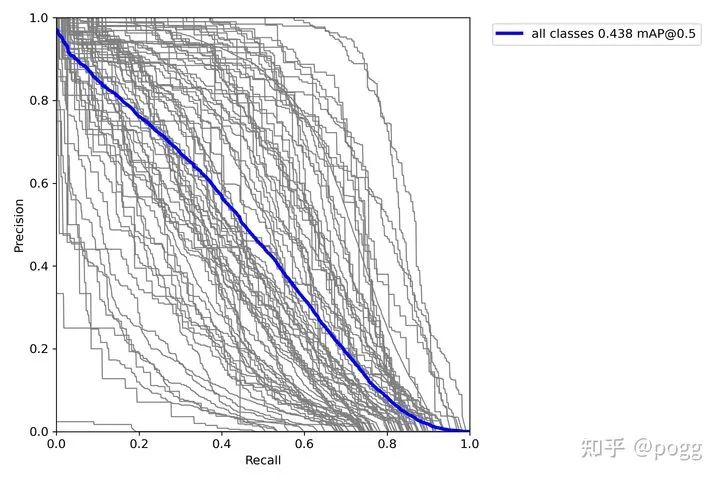
 导出PR曲线:
导出PR曲线:
 (G2)导出onnx后无需其他修改(针对部署而言)
(G2)导出onnx后无需其他修改(针对部署而言)
(G3)DNN或ort调用不再需要额外对Focus层进行拼接(之前玩yolov5在这里卡了很久,虽然能调用但精度也下降挺多):
(G4)ncnn进行int8量化可保证精度的延续(在下篇会讲)
(G5)在0.1T算力的树莓派上玩yolov5也能实时
以前在树莓派上跑yolov5,是一件想都不敢想的事,单单检测一帧画面就需要1000ms左右,就连160*120输入下都需要200ms左右,实在是啃不动。
但现在shufflev2-yolov5做到了,毕设的检测场景在类似电梯轿厢和楼道拐角处等空间,实际检测距离只需保证3m即可,分辨率调整为160*120的情况下,shufflev2-yolov5最高可达18帧,加上后处理基本也能稳定在15帧左右。
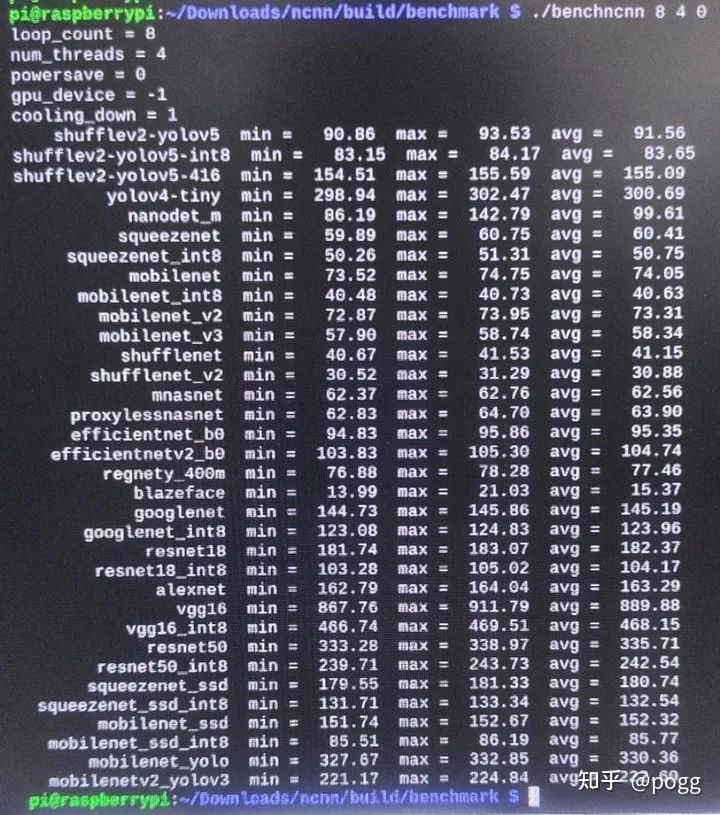
除去前三次预热,设备温度稳定在45°以上,向前推理框架为ncnn,记录两次benchmark对比:
# 第四次
pi@raspberrypi:~/Downloads/ncnn/build/benchmark $ ./benchncnn 8 4 0
loop_count = 8
num_threads = 4
powersave = 0
gpu_device = -1
cooling_down = 1
shufflev2-yolov5 min = 90.86 max = 93.53 avg = 91.56
shufflev2-yolov5-int8 min = 83.15 max = 84.17 avg = 83.65
shufflev2-yolov5-416 min = 154.51 max = 155.59 avg = 155.09
yolov4-tiny min = 298.94 max = 302.47 avg = 300.69
nanodet_m min = 86.19 max = 142.79 avg = 99.61
squeezenet min = 59.89 max = 60.75 avg = 60.41
squeezenet_int8 min = 50.26 max = 51.31 avg = 50.75
mobilenet min = 73.52 max = 74.75 avg = 74.05
mobilenet_int8 min = 40.48 max = 40.73 avg = 40.63
mobilenet_v2 min = 72.87 max = 73.95 avg = 73.31
mobilenet_v3 min = 57.90 max = 58.74 avg = 58.34
shufflenet min = 40.67 max = 41.53 avg = 41.15
shufflenet_v2 min = 30.52 max = 31.29 avg = 30.88
mnasnet min = 62.37 max = 62.76 avg = 62.56
proxylessnasnet min = 62.83 max = 64.70 avg = 63.90
efficientnet_b0 min = 94.83 max = 95.86 avg = 95.35
efficientnetv2_b0 min = 103.83 max = 105.30 avg = 104.74
regnety_400m min = 76.88 max = 78.28 avg = 77.46
blazeface min = 13.99 max = 21.03 avg = 15.37
googlenet min = 144.73 max = 145.86 avg = 145.19
googlenet_int8 min = 123.08 max = 124.83 avg = 123.96
resnet18 min = 181.74 max = 183.07 avg = 182.37
resnet18_int8 min = 103.28 max = 105.02 avg = 104.17
alexnet min = 162.79 max = 164.04 avg = 163.29
vgg16 min = 867.76 max = 911.79 avg = 889.88
vgg16_int8 min = 466.74 max = 469.51 avg = 468.15
resnet50 min = 333.28 max = 338.97 avg = 335.71
resnet50_int8 min = 239.71 max = 243.73 avg = 242.54
squeezenet_ssd min = 179.55 max = 181.33 avg = 180.74
squeezenet_ssd_int8 min = 131.71 max = 133.34 avg = 132.54
mobilenet_ssd min = 151.74 max = 152.67 avg = 152.32
mobilenet_ssd_int8 min = 85.51 max = 86.19 avg = 85.77
mobilenet_yolo min = 327.67 max = 332.85 avg = 330.36
mobilenetv2_yolov3 min = 221.17 max = 224.84 avg = 222.60
# 第八次
pi@raspberrypi:~/Downloads/ncnn/build/benchmark $ ./benchncnn 8 4 0
loop_count = 8
num_threads = 4
powersave = 0
gpu_device = -1
cooling_down = 1
nanodet_m min = 84.03 max = 87.68 avg = 86.32
nanodet_m-416 min = 143.89 max = 145.06 avg = 144.67
shufflev2-yolov5 min = 84.30 max = 86.34 avg = 85.79
shufflev2-yolov5-int8 min = 80.98 max = 82.80 avg = 81.25
shufflev2-yolov5-416 min = 142.75 max = 146.10 avg = 144.34
yolov4-tiny min = 276.09 max = 289.83 avg = 285.99
nanodet_m min = 81.15 max = 81.71 avg = 81.33
squeezenet min = 59.37 max = 61.19 avg = 60.35
squeezenet_int8 min = 49.30 max = 49.66 avg = 49.43
mobilenet min = 72.40 max = 74.13 avg = 73.37
mobilenet_int8 min = 39.92 max = 40.23 avg = 40.07
mobilenet_v2 min = 71.57 max = 73.07 avg = 72.29
mobilenet_v3 min = 54.75 max = 56.00 avg = 55.40
shufflenet min = 40.07 max = 41.13 avg = 40.58
shufflenet_v2 min = 29.39 max = 30.25 avg = 29.86
mnasnet min = 59.54 max = 60.18 avg = 59.96
proxylessnasnet min = 61.06 max = 62.63 avg = 61.75
efficientnet_b0 min = 91.86 max = 95.01 avg = 92.84
efficientnetv2_b0 min = 101.03 max = 102.61 avg = 101.71
regnety_400m min = 76.75 max = 78.58 avg = 77.60
blazeface min = 13.18 max = 14.67 avg = 13.79
googlenet min = 136.56 max = 138.05 avg = 137.14
googlenet_int8 min = 118.30 max = 120.17 avg = 119.23
resnet18 min = 164.78 max = 166.80 avg = 165.70
resnet18_int8 min = 98.58 max = 99.23 avg = 98.96
alexnet min = 155.06 max = 156.28 avg = 155.56
vgg16 min = 817.64 max = 832.21 avg = 827.37
vgg16_int8 min = 457.04 max = 465.19 avg = 460.64
resnet50 min = 318.57 max = 323.19 avg = 320.06
resnet50_int8 min = 237.46 max = 238.73 avg = 238.06
squeezenet_ssd min = 171.61 max = 173.21 avg = 172.10
squeezenet_ssd_int8 min = 128.01 max = 129.58 avg = 128.84
mobilenet_ssd min = 145.60 max = 149.44 avg = 147.39
mobilenet_ssd_int8 min = 82.86 max = 83.59 avg = 83.22
mobilenet_yolo min = 311.95 max = 374.33 avg = 330.15
mobilenetv2_yolov3 min = 211.89 max = 286.28 avg = 228.01
 (G6)shufflev2-yolov5与yolov5s的对比
(G6)shufflev2-yolov5与yolov5s的对比
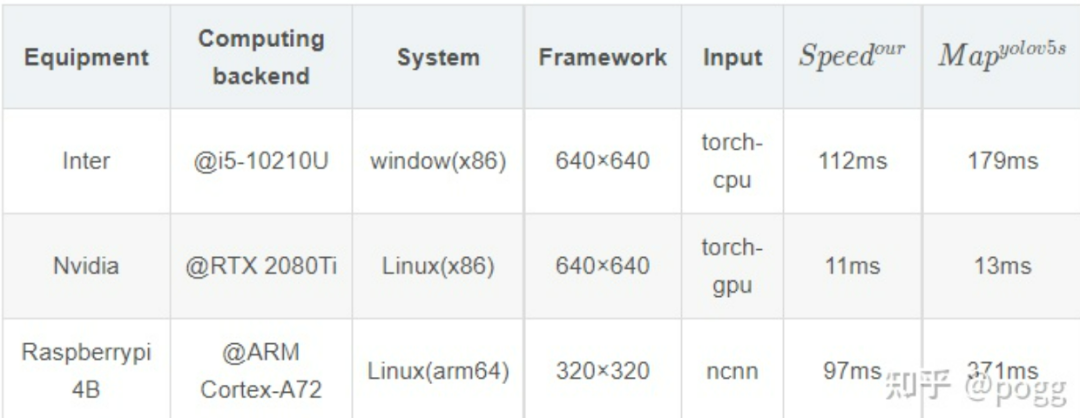
注:随机抽取一百张图片进行推理,四舍五入计算每张平均耗时。
六、后语
之前使用自己的数据集跑过yolov3-tiny,yolov4-tiny,nanodet,efficientnet-lite等轻量级网络,但效果都没有达到预期,反而使用yolov5取得了超过自己预想的效果,但也确实,yolov5并不在轻量级网络设计理念内,于是萌生了对yolov5修改的idea,希望能在它强大的数据增强和正负anchor机制下能取得满意的效果。总的来说,shufflev2-yolov5在基于yolov5的平台进行训练,对少样本数据集还是很work的。
没有太多复杂的穿插并行结构,尽最大限度保证网络模型的简洁,shufflev2-yolov5纯粹为了工业落地而设计,更适配Arm架构的处理器,但你用这东西跑GPU,性价比贼低。

那么!!!
shufflev2-yolov5在速度与精度均衡下超过nanodet了吗?并没有,在320×320@.5:0.95的条件下逊于nanodet。
shufflev2-yolov5在速度上超过yolo-fastest了吗,也没有,被yolo-fastest按在地上摩擦。
对于上个月刚出的yolox,那更是被吊起来锤。

优化这玩意,一部分基于情怀,毕竟前期很多工作是基于yolov5开展的,一部分也确实这玩意对于我个人的数据集十分work(确切的说,应该是对于极度匮乏数据集资源的我来说,yolov5的各种机制对于少样本数据集确实鲁棒)。
项目地址:https://github.com/ppogg/shufflev2-yolov5
另外,会持续更新和迭代此项目,欢迎star和fork!
最后插个题外话,其实一直都在关注YOLOv5的动态,最近U版大神更新的频率快了许多,估计很快YOLOv5会迎来第六版~
END
点赞三连,支持一下吧↓