
作者:Mattia Cinelli
翻译:朱启轩
校对:欧阳锦
本文通过一些Python示例代码介绍了可以提高代码可靠性的SOLID编码准则。
SOLID原则是由Robert C. Martin提出的以首字母缩写命名的编码准则,它代表了五种不同的编码习惯。如果您遵循这些原则,您就可以通过完善代码的结构和逻辑来提高代码的可靠度。
Photo by ThisisEngineering RAEng on UnsplashThe Single-Responsibility Principle (SRP)
单一任务原则
The Open-Closed Principle (OCP)
开闭原则
The Liskov Substitution Principle (LSP)
Liskov替换原则
The Interface Segregation Principle (ISP)
界面分离原则
The Dependency inversion Principle (DIP)
从属倒置原则
这五个原则并没有一个特定的先后顺序(做这个,然后做那个,等等),他们是历经几十年发展而成的最佳组合。为了方便记忆,他们被用一个缩略词(SOLID)所概括。类似的方法在计算机中也有出现过,例如: DRY: Don 't Repeat Yourself;KISS: Keep It Small and Simple;每一个首字母背后都是人们智慧的结晶。顺便提一下,这个缩写词是在这五项原则建立多年后才产生的。一般来说,SOLID原则是每个代码开发人员的基本学习步骤,但通常它会被那些不把代码质量放在第一位的人所忽略。然而,作为一名数据科学家,我认为遵循这些原则是有益的。具体地说,它提高了代码的可测试性,减少了技术上的障碍和为了实现客户/股东的新需求而修改代码所需的时间。在下文里,我将探讨这五个原则,并提供一些Python的示例。通常,SOLID原则应用于面向对象的编程情景中(即:Python的类),但我相信无论您的写码水平如何,他们都对您是有效的。我会在这里提供示例和解释,面向的是“高级初学者”的级别。
换言之,代码的每个部分((通常是一个类,但也可以是一个函数))应该有且只有一个职责。因此,应该只能有一个理由来改变它。您经常会看到一段代码在处理整个进程。即,在那些返回结果之前加载数据、修改数据并绘制数据图的函数。举一个简单的例子,我们有一串数组L = [n1, n2,…,nx],然后我们将对这个数组进行一些数学运算。例如,计算平均值、中位数等。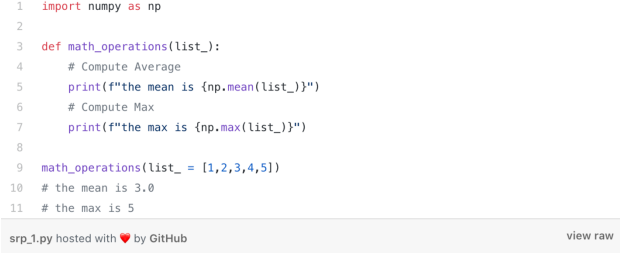
为了使这个函数更符合SRP原则,我们应该做的第一件事是将函数math_operations分解为只有单一功能的函数!这样的话,这个函数的职责就不能再往下继续去细分了。第二步是创建一个函数(或类),一般命名为“main”。然后通过这个函数一步一步地调用所有其他函数。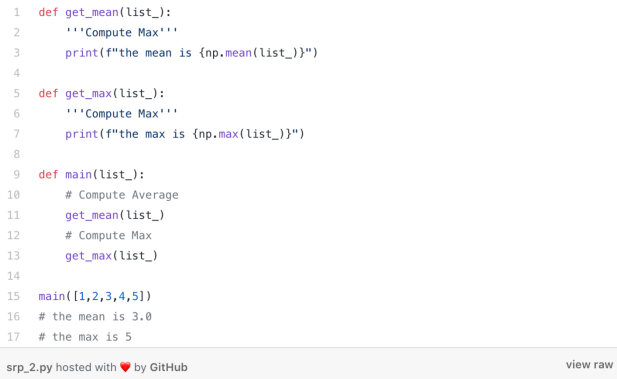
现在,您就只有一个更改与“main”连接的函数的理由了。1. 错误范围缩小起来会更容易。进程中的任何错误都更具有指向性,从而加速了调试进程。3. 此外,经常被忽视的一点是,这样做使得函数测试起来更加容易。关于测试的附注:您应该在实际编写脚本之前就编写好了测试。但是,为了创造一些好的结果并展示给利益相关者,这常常会被忽视。对于第一个示例来说,这已经是一个很大的改进了。但是,创建一个“main”函数和调用只有单一责任的函数并没有实现SR的全部原则。事实上,我们的“main”有许多原因需要去改变。这个类实际上是很脆弱的,很难去维护。2) 开闭原则 (OCP
“软件实体 … 应该对拓展升级开放,对调试修改封闭”
也就是说:您不需要修改已经编写好的代码以适应新的需求,而只需添加您现在需要的东西。这并不是说,当代码的前提需要修改时,您不用更改代码,而是说,如果您需要添加与现有函数类似的新函数,您不应当更改代码的其他部分。为了澄清这一点,让我们参考前面看到的示例。如果我们想添加新的功能,例如,计算中位数,我们应该创建一个新的函数,并将其调用添加到“main”中。这将增加一个扩展函数,同时也修改了“main”。我们可以通过将我们编写的所有函数转换成一个类的子类的方法来解决这个问题。在本例中,我创建了一个名为“Operations”的抽象类和一个抽象方法“get_operation”。(抽象类这个知识点通常要求比较高。如果您不知道什么是抽象类,您可以先运行以下代码进行尝试)。现在,所有旧的函数和类都被__subclasses__()方法调用。它将找到所有从Operations继承的类,并运行存在于所有子类中的函数“Operations”。
如果现在我们想要添加一个新的功能,例如:median,我们只需要添加一个从类“Operations”继承的类“median”。新形成的子类将立即被__subclasses__()获取,不需要对代码的其他部分进行修改。我们将会得到一个非常灵活的类,它所需的维护时间也会是最少的。3) Liskov 替换原则(LSP)
“那些使用指针或者引用基类的函数必须要在不知情的情况下使用派生类的对象”
也可以说,“派生类对于他们的基类来说必须要是可替换的才行”.简单地说,如果子类重新定义了同样在父类中出现的函数,用户不应该注意到任何差异,它只是基类的一个替代品。例如,如果您正在使用一个函数,而您的同事更改了基类,那您不应该注意到任何差异。在所有的SOLID原则中,这是最难理解和解释的。对于这个原则,没有标准的“教科书式的”解决方案,而且很难提供一个“标准示例”来展示。如果在子类中重新定义了基类中也存在的函数,那么这两个函数应该具有相同的行为。但是,这并不意味着它们必须强制性等同,而是:给定相同输入能得出相同类型的结果。在示例ocp.py中,“operation”方法出现在子类和基类中,终端用户应该期望从这两个类中得到相同的行为。这一原则的结果是,我们将以一致的方式编写代码,只有终端用户会需要去了解我们的代码是如何工作的。LSP的一个结果是: 在子类中重新定义的新函数应该是有效的,并且可能在父类中使用相同的函数时被调用。这不是我们所常见的情况,事实上,通常我们人类,用集合论的方法来思考。我们的类会首先定义概念,然后用子类去扩展之前定义的类的概念及其不同行为。例如,超类“哺乳动物”的子类 “鸭嘴兽”就是一个例外,那就是这些哺乳动物会产卵。LSP原则告诉我们它将创建一个名为“give_birth”的函数,这个函数将对子类Platypus和子类Dog有不同的行为。因此,我们应该会有一个比哺乳类更抽象的基类来适应这一点。如果这听起来非常令人困惑,请不要担心,LSP原则在这方面的应用很少有被实现,目前还停留在理论阶段。4) 界面分离原则 (ISP
“具有很多面向特定客户的界面会比只有一个的通用的界面要好”
在写类的时候,我们一般都只考虑使用一个界面,所有的方法和属性都“暴露”出来了,因此,所有用户可以与之交互的东西都属于这个类。在这种意义上,IS原则告诉我们,类其实有所需的界面(SRP)就行了,我们应该避免那些无法工作或没有理由成为该类一部分的方法。当子类从它不需要的基类继承方法时,就会出现这个问题。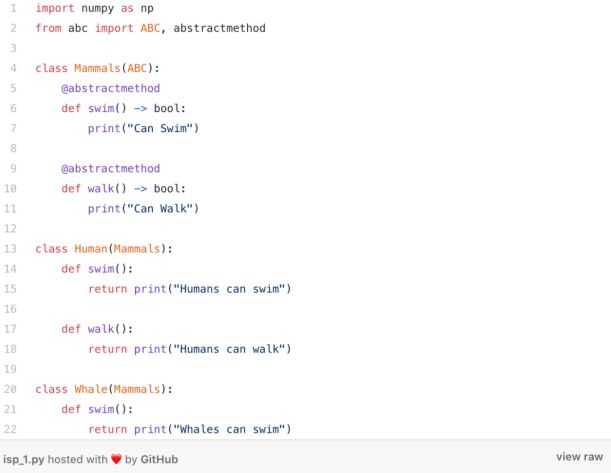
对于这个例子,我们有一个抽象类 “Mammal”,它有两个抽象方法:“walk”和“swim”。这两个元素将属于“Human”子类,而只有“swim”将属于“Whale”子类。
实际上,如果我们运行这段代码,我们会得到:

子类whale仍然可以调用方法“walk”,但它不应该这样做,我们必须避免它。
ISP建议的方法是创建更多面向特定用户的界面,而不是一个通用的界面。因此,我们的代码示例变成如下:

现在,每个子类只继承它需要的东西,避免了调用断章取义(错误)的子方法。如果继承了不需要的东西,可能会产生难以捕捉的错误。
这一原则与其他原则紧密相连,具体来说,它告诉我们要保证子类的内容整洁度,排除对子类没有用处的元素。这样做的最终目的是让我们的类能够保持整洁,并将错误最小化。
5) 从属倒置原则(DIP)
“抽象类不应该依赖于细节。细节应该依赖于抽象类。高级模块不应该依赖于低级模块。两者都应该依赖于抽象类”因此,抽象类(例如,上面看到的界面)不应该依赖于低级方法,而应该都依赖于第三个界面。
为了更好地解释这个概念,我倾向于认为这是一种信息流。
假设您有一个程序,它接收一组特定的信息(文件、格式等),然后您编写了一个脚本来处理它。
如果这些信息有变化会发生什么?
你将不得不重写你的脚本并调整新的格式。失去与旧文件的兼容性。
然而,您可以通过创建第三个抽象类来解决这个问题,该抽象类将信息作为输入并将其传递给其他抽象类。
这基本上也是API的用途。
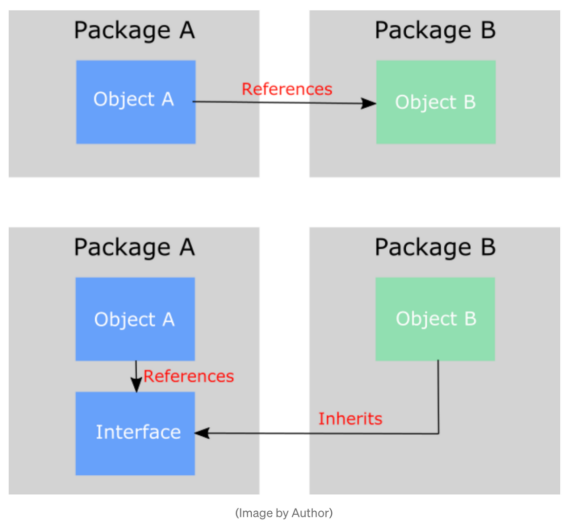
这一原则的设计理念有趣在于,它与我们通常的做法相反。
考虑到DIP原则,我们将从项目的尾部开始,我们的代码独立于所输入的内容,它不受更改的影响,并且不受我们的直接控制。
我希望您能在您的代码中运用这些概念,我知道它们是为我准备的。除此以外,我还提供了一些我用来理解这些原则的材料。
R. C. Martin, “The Principles of OOD,” 2013.
http://butunclebob.com/ArticleS.UncleBob.PrinciplesOfOod
https://codingwithjohan.com/blog/solid-python-introduction
“Clean Code in Python” by Mariano Anaya
https://towardsdatascience.com/solid-coding-in-python-1281392a6a94朱启轩,康奈尔大学研究生在读,专业领域是应用统计,方向是数据科学。本科毕业于加州大学洛杉矶分校。热爱数据科学,对处理数据,分析数据有自己的独特见解。对新知识充满了渴望,目前正在学习自然语言处理和深度学习方面的知识,希望能认识更多志同道合的人,一起努力,一起进步。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

