
一行代码教你绘制顶级期刊要求配图
↑↑↑关注后"星标"简说Python 人人都可以简单入门Python、爬虫、数据分析 简说Python推荐 来源|python数据分析之 作者|小dull鸟
R-ggpubr包主要类型函数介绍 R-ggpubr包主要案列展示
R-ggpubr包主要类型函数介绍
虽然在Python中我们也可以通过使用Matplotlib定制化出符合出版要求的图表,但这毕竟对使用者的绘图技能要求较高,当然也是还有部分轮子可以用的。而我们今天则介绍一个高性能的R包-ggpubr,从名字就可以看出这个包的主要用途了。
官网:https://rpkgs.datanovia.com/ggpubr/index.html
几大绘图函数类型
这个包对于绘图类型分的较为详细,主要按照变量个数进行划分,详细介绍如下
「绘制一个变量-X,连续」
ggdensity(): 密度图 stat_overlay_normal_density(): 覆盖法线密度图 gghistogram(): 直方图 ggecdf(): 经验累积密度函数 ggqqplot(): QQ图 「绘制两个变量-X和Y,离散X和连续Y」
ggboxplot(): 箱形图 ggviolin(): 小提琴图 ggdotplot(): 点图 ggstripchart(): 条形图 ggbarplot(): 条形图 ggline(): 线图 ggerrorplot(): 错误图 ggpie(): 饼图 ggdonutchart(): 甜甜圈图 ggdotchart()、theme_cleveland(): 克利夫兰点图 ggsummarytable()、ggsummarystats():添加摘要统计信息表 「绘制两个连续变量」
ggscatter(): 散点图 stat_cor(): 将具有P值的相关系数添加到散点图中 stat_stars(): 将星星添加到散点图中 ggscatterhist(): 具有边际直方图的散点图 「比较均值并添加p值」
compare_means(): 均值比较 stat_compare_means(): 将均值比较P值添加到ggplot stat_pvalue_manual():手动将P值添加到ggplot stat_bracket()、geom_bracket(): 将带有标签的括号添加到GGPlot
其他更多优秀函数,小伙伴们可自行查阅官网进行探索。
R-ggpubr包主要案列展示
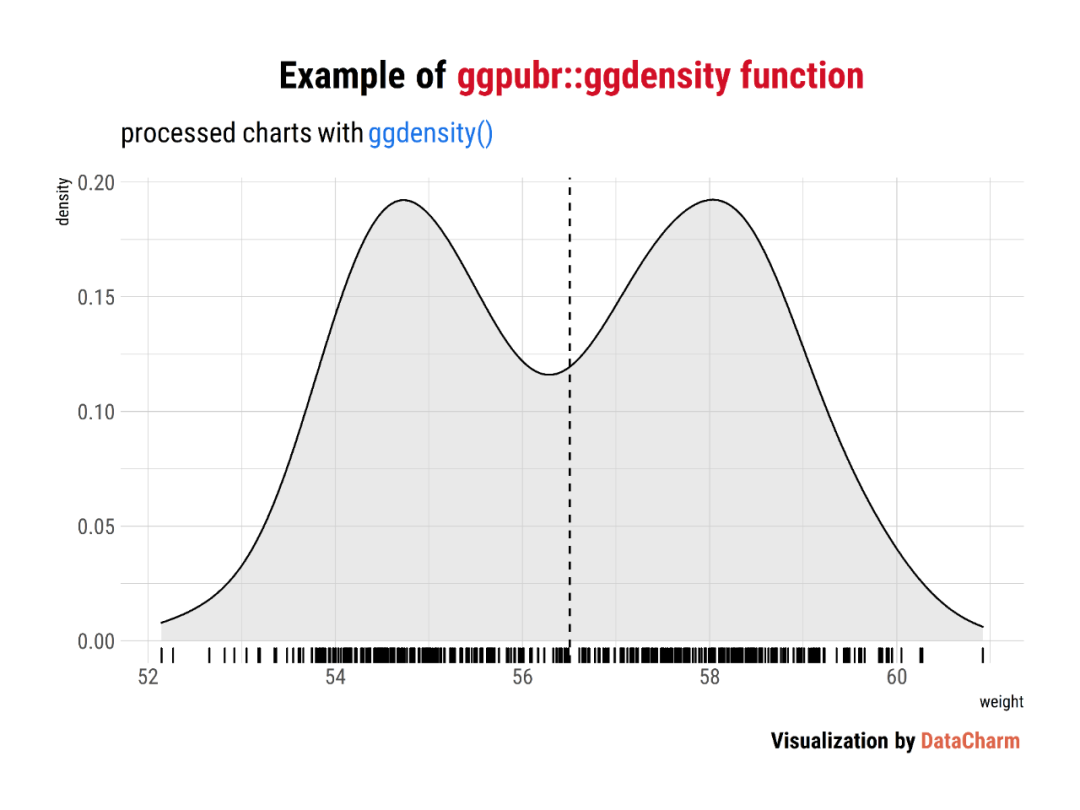
Density plot
set.seed(1234)
wdata = data.frame(
sex = factor(rep(c("F", "M"), each=200)),
weight = c(rnorm(200, 55), rnorm(200, 58)))
ggdensity <- ggdensity(wdata, x = "weight", fill = "lightgray",
add = "mean", rug = TRUE) +
labs(
title = "Example of <span style='color:#D20F26'>ggpubr::ggdensity function</span>",
subtitle = "processed charts with <span style='color:#1A73E8'>ggdensity()</span>",
caption = "Visualization by <span style='color:#DD6449'>DataCharm</span>") +
hrbrthemes::theme_ipsum(base_family = "Roboto Condensed") +
theme(
plot.title = element_markdown(hjust = 0.5,vjust = .5,color = "black",
size = 20, margin = margin(t = 1, b = 12)),
plot.subtitle = element_markdown(hjust = 0,vjust = .5,size=15),
plot.caption = element_markdown(face = 'bold',size = 12),
)
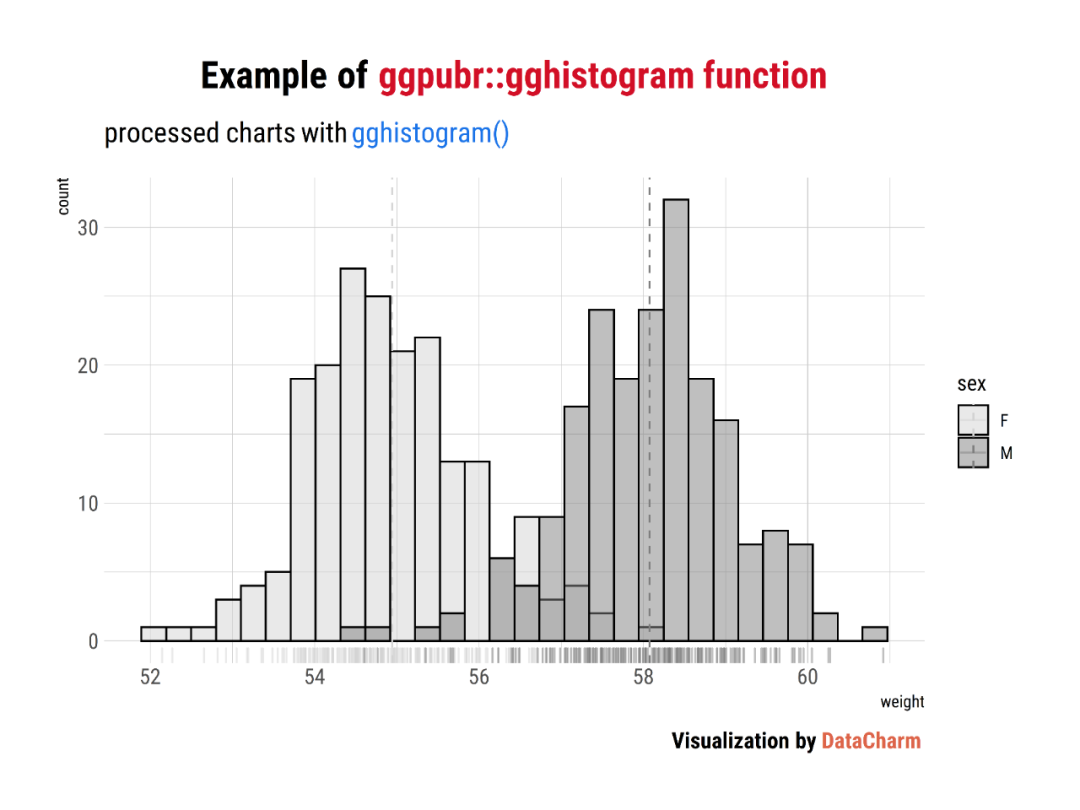
Histogram plot
set.seed(1234)
wdata = data.frame(
sex = factor(rep(c("F", "M"), each=200)),
weight = c(rnorm(200, 55), rnorm(200, 58)))
gghistogram <- gghistogram(wdata, x = "weight", fill = "sex",
add = "mean", palette = c("lightgray", "gray50"),add_density = TRUE,rug = TRUE)+
labs(
title = "Example of <span style='color:#D20F26'>ggpubr::gghistogram function</span>",
subtitle = "processed charts with <span style='color:#1A73E8'>gghistogram()</span>",
caption = "Visualization by <span style='color:#DD6449'>DataCharm</span>") +
hrbrthemes::theme_ipsum(base_family = "Roboto Condensed") +
theme(
plot.title = element_markdown(hjust = 0.5,vjust = .5,color = "black",
size = 20, margin = margin(t = 1, b = 12)),
plot.subtitle = element_markdown(hjust = 0,vjust = .5,size=15),
plot.caption = element_markdown(face = 'bold',size = 12),
)
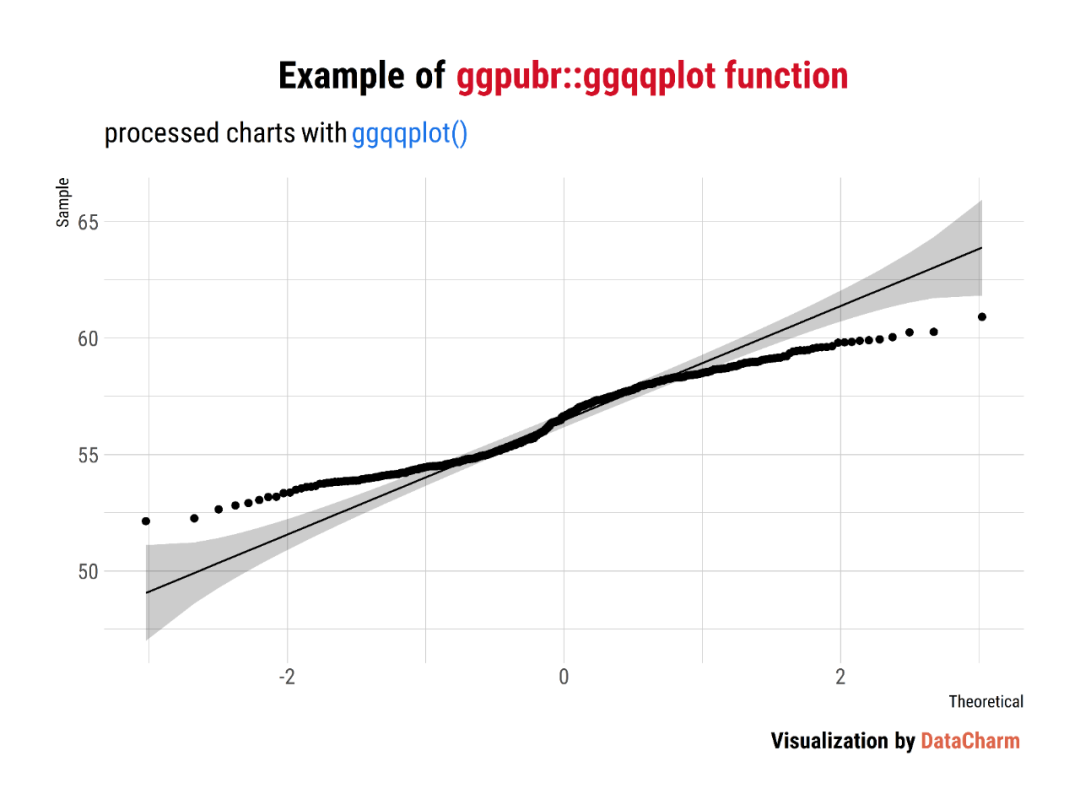
QQ Plots
# Create some data format
set.seed(1234)
wdata = data.frame(
sex = factor(rep(c("F", "M"), each=200)),
weight = c(rnorm(200, 55), rnorm(200, 58)))
# Basic QQ plot
ggqqplot <- ggqqplot(wdata, x = "weight") +
labs(
title = "Example of <span style='color:#D20F26'>ggpubr::ggqqplot function</span>",
subtitle = "processed charts with <span style='color:#1A73E8'>ggqqplot()</span>",
caption = "Visualization by <span style='color:#DD6449'>DataCharm</span>") +
hrbrthemes::theme_ipsum(base_family = "Roboto Condensed") +
theme(
plot.title = element_markdown(hjust = 0.5,vjust = .5,color = "black",
size = 20, margin = margin(t = 1, b = 12)),
plot.subtitle = element_markdown(hjust = 0,vjust = .5,size=15),
plot.caption = element_markdown(face = 'bold',size = 12),
)
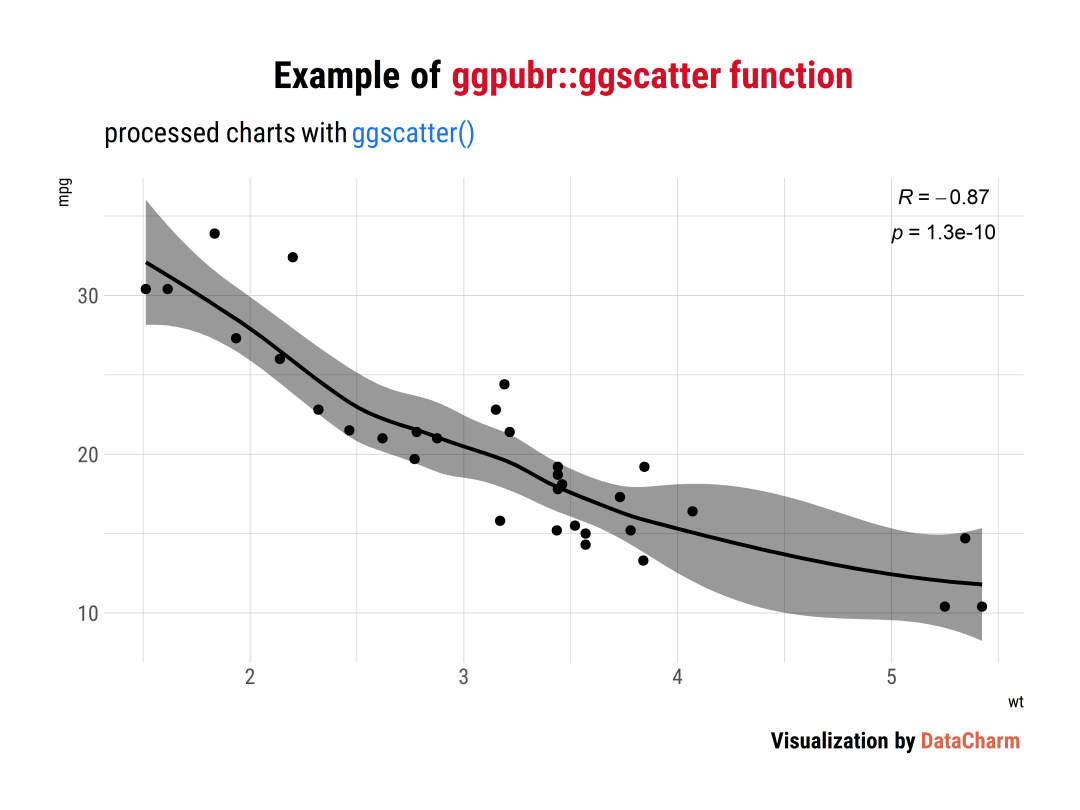
Scatter plot
# Load data
data("mtcars")
df <- mtcars
df$cyl <- as.factor(df$cyl)
ggscatter <- ggscatter(df, x = "wt", y = "mpg",
add = "loess", conf.int = TRUE,
cor.coef = TRUE,
cor.coeff.args = list(method = "pearson", label.x = 5,label.y=35, label.size=25,label.sep = "\n"))+
labs(
title = "Example of <span style='color:#D20F26'>ggpubr::ggscatter function</span>",
subtitle = "processed charts with <span style='color:#1A73E8'>ggscatter()</span>",
caption = "Visualization by <span style='color:#DD6449'>DataCharm</span>") +
hrbrthemes::theme_ipsum(base_family = "Roboto Condensed") +
theme(
plot.title = element_markdown(hjust = 0.5,vjust = .5,color = "black",
size = 20, margin = margin(t = 1, b = 12)),
plot.subtitle = element_markdown(hjust = 0,vjust = .5,size=15),
plot.caption = element_markdown(face = 'bold',size = 12),
)
Add Manually P-values to a ggplot
ToothGrowth$dose <- as.factor(ToothGrowth$dose)
# Comparisons against reference
stat.test <- compare_means(
len ~ dose, data = ToothGrowth, group.by = "supp",
method = "t.test", ref.group = "0.5"
)
bp <- ggbarplot(ToothGrowth, x = "supp", y = "len",
fill = "dose", palette = "jco",
add = "mean_sd", add.params = list(group = "dose"),
position = position_dodge(0.8))
bp + stat_pvalue_manual(
stat.test, x = "supp", y.position = 33,
label = "p.signif",
position = position_dodge(0.8)
) +
labs(
title = "Example of <span style='color:#D20F26'>ggpubr::stat_pvalue_manual function</span>",
subtitle = "processed charts with <span style='color:#1A73E8'>stat_pvalue_manual()</span>",
caption = "Visualization by <span style='color:#DD6449'>DataCharm</span>") +
hrbrthemes::theme_ipsum(base_family = "Roboto Condensed") +
theme(
plot.title = element_markdown(hjust = 0.5,vjust = .5,color = "black",
size = 20, margin = margin(t = 1, b = 12)),
plot.subtitle = element_markdown(hjust = 0,vjust = .5,size=15),
plot.caption = element_markdown(face = 'bold',size = 12),
)

Draw a Textual Table
# data
df <- head(iris)
# Default table
table1 <- ggtexttable(df, rows = NULL)
table2 <- ggtexttable(df, rows = NULL, theme = ttheme("blank")) %>%
tab_add_hline(at.row = 1:2, row.side = "top", linewidth = 2)
总结
今天推文我们介绍了「R-ggpubr」实现极少代码绘制出符合期刊要求的可视化图表,极大省去了绘制单独图表元素的时间,为统计分析及可视化探索提供非常便捷的方式,感兴趣的小伙伴可探索更多的绘图函数哦~~
扫码回复:2021
获取最新学习资源

推荐大家关注两个公号
分享程序员生活、互联网资讯、理财复盘日记等 专注于Java学习分享,从零和你一起学Java
关注后回复【1024】 送上独家资料 ◆◆◆ 欢迎大家围观朋友圈,我的微信:pythonbrief 学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
“点赞”传统美德不能丢 
扫码回复:2021
获取最新学习资源
推荐大家关注两个公号
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
“点赞”传统美德不能丢
评论