
数据还是模型?人类知识在深度学习里还有用武之地吗?

极市导读
随着模型规模越来越大,训练模型的数据越来越多,模型是否还需要人类的知识这一问题也不断被提起,不断被争论。后深度学习时代,模型真的还需要人类的“知识”吗? >>加入极市CV技术交流群,走在计算机视觉的最前沿
近些年来,随着数据量越来越多,算力价格越来越便宜,根植于数据+算力的深度学习茁壮成长。在这种背景下,作为一种强有力的表示学习方法的深度学习让人们惊讶的发现,只要投喂足够多的数据,DNN 模型即可展现出强大的威力。看上去,模型似乎不再需要由人去教它如何看数据了(特征工程)。
从这之后,各个领域、各个任务都相继出现了不少大规模的预训练模型,它们从无监督的数据中学习到一些东西,然后再使用小规模任务数据去精调模型,就可以让模型拥有非常优秀的表现。看上去,模型也不再需要由人去告诉它什么是正确的了,不需要准备大量的数据去“教”它了,只靠模型自己就可以学到“知识”。
同时,这期间也出现了 AlphaGo Zero ,可以完全不需要学习人类的棋谱,通过自己脑补,自己训练,就可以下出世界第一的围棋。看上去,模型甚至可以脱离人类的经验,自己去发现更好、更优的“知识”。
所以自然而然,我们就会去反思,后深度学习时代,模型真的还需要人类的“知识”吗?

随着模型规模越来越大,训练模型的数据越来越多,模型是否还需要人类的知识这一问题也不断被提起,不断被争论。就像 GPT-3 被发布时,哪怕它已经展现出了那么多“神奇”的能力,研究者们依然会去争论,大模型是否真正学到了知识?是否还需要人类的知识去指导它?
而面对这一切,让我们从 2019 年的一场争论谈起。
缘起
2019年3月,阿尔伯塔大学教授 Rich Sutton 在博客上发表了一篇文章 《 The Bitter Lesson 》 (惨痛的教训)[1],开篇就说道:“在70年的AI研究中可以得到的最大的教训是,利用计算能力的一般方法最终是最有效的方法,且是大幅度的领先。”他认为,尽管在算力恒定的情况下,使用人类知识去提升性能可能是唯一的方法,但正如我们大家所看到的,这些年算力成本却在持续地指数级下降,在取消算力恒定的约束后,人类知识的重要性也就变得可有可无了,也即是说,提升计算能力才是 AI 研究进步的最一般且最有效的方法。
Sutton 教授举出来的例子也非常实际,例如前文所提到的 AlphaGo Zero ,在其自学围棋之后,又迅速扩展到了所有棋类。在其他领域,人们使用各种五花八门的特征工程去训练模型,而依赖大量计算的 DNN 模型发挥其威力,又打败了特征工程(如CNN vs SIFT,神经机器翻译 vs 传统的对齐方法等)。
最后,Sutton 教授认为,随着算力的增强去提升“搜索”能力与“学习”能力是唯二的方法可以通用的提升所有 AI 模型与研究的性能和效果。
而心智是极其复杂的东西,应停止试图用简单的方法来进行“思考”,已有的“心智”不应该包含在 AI 之中,而是要让 AI 获得能够得到“心智”的能力,AI应当自己去发现,而不是去包含已经发现的东西。
这篇博客自然在学界掀起了轩然大波,支持者们认为,从近些年的工作来看,DNN 的确展现了强大的威力,尤其各大预训练模型横空出世,在训练 DNN 的过程中,也的确在逐渐剥离人类的经验,未来可能真的仅靠算力就可以了。
反对者则认为,的确看上去 DNN 模型的发展是一步步地在抛弃人类知识,但是其展现威力的原因还是在于那些没有被抛弃的知识。毕竟现在的 DNN 模型,还是无法避开卷积、LSTM、No-Linear 等人类知识,正是因为利用了一些人类知识,AI 才得以取得今天的成就。

而今天,笔者还是想借着阿姆斯特丹大学教授 Max Welling 于 2019 年 4 月写的一篇回应文章《Do we still need models or just more data and compute?》[2]浅谈一下这个问题。
模型 OR 数据+算力?
Welling 教授是部分认同 Sutton 教授的第二点设想的,即让模型自己去“发现”这个世界的一些“知识”——如物理学、心理学、社会学等规律。但是问题在于,Sutton 的想法是完全理想化的,即数据是绝对充足的,在现实中,数据往往不是那么的充足,比如强化学习的确在围棋上取得了非常大的成就,但我们不能忽略,围棋是一个有强规则限制,且数据近乎无限(已有规则之内,可以任意生成对弈数据)的任务。但是如果到了自动驾驶的场景,每一个问题则又变得长尾。

在文章中,Welling 教授提出了自己的方法。数据不足其实是真实世界的常态,所以使用大量的人类知识也是AI的常态。理想状况下当然是真实世界每一个问题中,每一个领域中数据都是充足的,但这又显然是不可能的。当然,领域这么多,总会有那么若干个领域数据是足够的,而在充足的数据中,也是可以训练出一个非常好的模型的。
但是问题就在于,从足够的数据中所训练出来的模型,只具备归纳能力(原文为 Discriminative methods,即判别模型),而我们又需要从模型中剥离原本数据的归纳偏置,只留下“知识”(原文为讲判别模型反推成为一个生成模型,其实就是让模型具备演绎能力),那么该模型就可以轻松地迁移到新的领域了。
例如,我们要训练一个语言模型,在训练好了之后,却又让模型忘掉训练数据中的“事实”(如刘德华的老婆是朱丽倩)而仅剩下知识(【男人】的老婆是【女人】),那么这个语言模型就可以去“想象”其他的文本,那它就适用于任何类似的文本了。
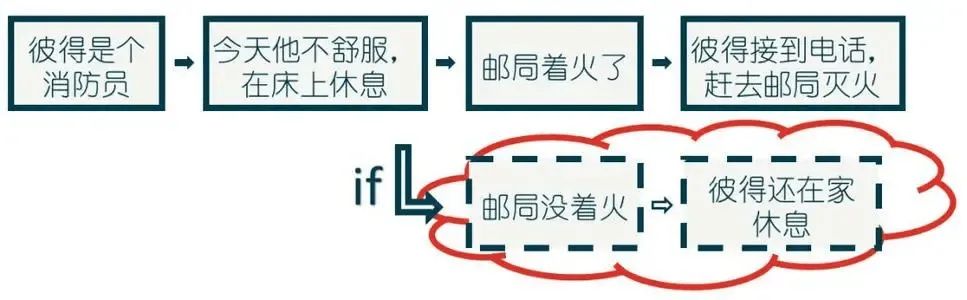
这正是人类自身具备的一个强大的能力——“反事实”的能力,即在脑中想象一个不存在的世界的能力,例如我如果做了某件事会发生什么,如果某件事没有发生,现在会怎么样。Welling 教授认为,人具备这种能力的程度,恰恰又取决于他对这个世界知识的了解程度(如物理学、心理学知识等)。
当然符号 AI 就是以这种方式构筑的,但它又受限于专家所写的规则,无法应对复杂的世界(Sutton 教授所秉持的观点)。
而如果有一个 AI 具备了从数据中学习这种东西的能力( Welling 教授认为是基于强化学习方法),的确,可以只使用一点点人类知识,以及充足的算力,就可以训练出来一个 AGI(通用人工智能) ,至于这个模型还是不是使用人类所设计的结构(毕竟人类设计的模型结构也是人类知识),那就不知道了。
笔者的一点想法
Welling 教授的想法和愿景,笔者是大部分同意的,或者说,笔者前几年秉持的观点,在做的工作,其实就是想要训练出来一个“只有知识,没有事实”的语言模型。现在的想法,也是想在部分问题上让模型做到“知识化”(虽然部分是符号的做法),但关于现状,笔者也想谈谈自己粗浅的想法。
首先,Sutton 教授所举的例子(本质上是 DNN 表示学习 vs 特征工程),实际上也是没有脱离人类知识的。例如围棋,游戏规则就是人类知识,整个就是在游戏规则下走下去的。
而且包括下棋在内的,所有的 DNN 模型,虽然人类不去指导模型去“怎么看数据”了,但人类还是在指导模型“应该看什么,注意看哪些”。即上面所讨论的所有关于模型结构的部分,哪怕是可以从数学上证明,部分模型结构虽然看上去差别挺大,但是从特征捕捉的角度来讲是等价的,但仍旧没有脱离它。
从最初的 MLP 到现在大流行的 Transformers ,我们就是不断地在教模型怎么样去看数据,同时,我们也在不断地用数据分布试图去描述这个模型所要面对的世界,预训练模型亦是如此。这么说来,只不过如 Welling 教授所说,我们用的知识变少了而已。

而 Welling 教授所讲反事实部分,人类的确是拥有了一定的规则,甚至是规律之后,就会进行“反事实”思考,但问题却不在判别模型与生成模型,而是现如今的统计模型,都难以做到。Welling 教授就判别模型的评价更像是对整个统计模型的评价:统计模型只能进行归纳,却无法进行演绎( Welling 教授对生成模型的描述更像是一种演绎能力),而如 《 The book of WHY 》 作者在书中所说:统计学习只能去寻找关联,而不能得到因果。所以或许 Welling 所提到的愿景,现如今也只能是愿景。
更简单地说,统计模型所学的一切,都只是“是什么”,而学不到“不是什么”,那么它其实就完全无法分辨真和假,这其实就直接导致它是无法将学到的东西应用到完全未知的领域的。预训练模型起到作用,其实也是因为数据足够大,且足够通用了,让模型见过了绝大多数下游任务的数据,学到了足够的关联,而到了未知的专业领域,其同样又会掣肘。
更玄幻一点儿,也是笔者会感到无力的地方,则是,人类现阶段是不具备描述知识的能力的,自然也无法描述自己是怎么样学到的知识,以及学到了什么样的知识。那么,如何去探寻模型怎样拥有这样的能力,或许还前路茫茫,但研究者们仍以不同的方式探索,或许有一日真的找到了,那我们也自然期待人工智能真正的大变革。
争论与未来
Sutton 教授的博客中写的内容其实比较客观合理,他并不是秉持算力与算法对立的极端观点,虽然其部分说法像是试图挑起这种对立。而这件事情在学术圈开始争论的时候,却又走向了算法 vs 算力的方向。
Welling 教授前面看上去反驳了 Sutton 教授的观点,强调了人类知识的作用,但后面他也还在部分认同 Sutton 教授。Welling 教授所反驳的 Sutton 教授所阐述的数据规模的问题、其他反对者所提到的模型结构的问题以及所谓的自己学习的模型是否利用了人类经验的问题等等,看上去似乎是“显而易见”且没必要争论的,那么大佬们为什么要掀起来这场争论呢?
首先我是相信大佬的智商和知识储备的,就好像训练 GPT-3 的大佬们,我认为他们是不可能不知道统计模型的局限的。但是在 PR 的时候又会说 GPT-3 的种种“智能”。那么当大佬们在鼓吹这些看上去不切实际的言论的时候,他们到底想要干什么呢?
其实回顾人工智能几十年的历史,技术在发展的同时,又往往免不了各个派系之间的争辩,而每一次的争辩,都不免会有一些看上去不切实际,甚至完全没有逻辑支撑的构想,或者产生一些完全断章取义的攻击,它们或是想要提出一个努力的目标,或是单纯想打败对面的立场,或是仅仅就是想保持自己研究方向的讨论热度,毕竟讨论趋势到了,这个方向才能有各方面的支撑继续发展下去。
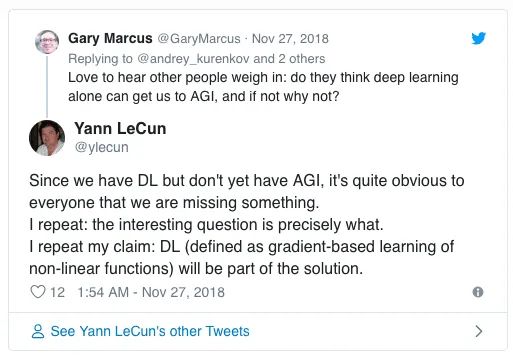
而现如今,Twitter 的每一场论战,或许也是要去“欺骗”舆情系统,让这个领域继续保持繁荣。而每一次这样的争论,哪怕是有这种目的,其碰撞的火花也能让我们有一些新的思考,这是对我们受用无穷的。
参考文献
[1].The Bitter Lesson http://incompleteideas.net/IncIdeas/BitterLesson.html
[2].Do we still need models or just more data and compute? https://staff.fnwi.uva.nl/m.welling/wp-content/uploads/Model-versus-Data-AI-1.pdf
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
