
干货 | 十种常用的标注方法与十种标注工具
点击左上方蓝字关注我们

一、什么是图像标注
图像标注是一个给图像添加标签的过程。它可以为整个图像添加一个标签,也可以分别为图像内每组像素添加多个标签。一个简单例子是向人工标注器提供动物图像,让其用正确的动物名称标记每个图像。
当然,标记的方法依赖于项目所使用的图像标注类型。这些带标注的图像有时被称为地面实况数据,之后将馈入计算机视觉算法中。通过训练,模型可以对已标注的动物图像与未经标注的图像进行区分。
1.矩形框标注
是指给人工标注器提供一幅图像,让其在图像内特定对象周围绘制一个框。该方框应尽可能靠近特定对象的每个边缘。如果你的项目有特殊需求,一些公司一般也可进行一定的调整来满足此种需求。矩形框标注又叫拉框标注,是目前应用最广泛的一种图像标注方法。
2.语义分割
语义分割是指根据物体的属性,对复杂不规则图片进行进行区域划分,并标注对应的属性,以帮助训练图像识别模型,常应用于自动驾驶汽车、人机交互、虚拟现实等领域。
关键点标注是指通过人工的方式,在规定位置标注上关键点,例如人脸骨骼点、场景目标物体等,常用来训练面部识别模型以及统计模型。
4.点云标注
点云是三维数据的一种重要表达形式,通过激光雷达等传感器,采集各类障碍物及其位置坐标,而标注员则需要将这些密集的点云分类,并标注上不同的属性。
5.3D长方体标注
与边界框类似,3D长方体标注是在图中对象周围用标注器绘制一个框。与只描绘长和宽的2D边界框不同,3D长方体标注了对象的长、宽和近似深度。
使用3D长方体标注,人工标注器会绘制一个框把感兴趣的对象封起来,并将锚点放置在对象的每个边缘。如果对象的一个边缘不在视图中或被图像中的另一个对象挡住,那么标注器就会根据对象的大小和高度以及图像的角度来估算其边缘所在的位置。
6.2D/3D融合标注
2D/3D融合标注是指同时对2D和3D传感器所采集到的图像数据进行标注,并建立关联。该类型标注方法能够标注物体在平面和立体中的位置和大小,帮助自动驾驶模型增强视觉和雷达的感知。
7.多边形标注
图像中的对象由于光照或角度等原因,其形状、大小或方向无法被很好地适配上2D边界框或3D长方体。同时,开发人员希望对图像中的对象,进行更加精确的标注。在这些情况下,我们需要选择多边形进行标注。在使用多边形时,标注器会通过在需要标注的对象的外边缘,放置许多个点来绘制成线。这个过程有点类似我们小时候玩过的“连点成线,勾勒轮廓”的练习。

9. 线和样条线
虽然线和样条线适用于多种用途,但它们主要用于训练机器识别车道和边界。顾名思义,标注器将简单地沿着你需要机器学习的边界画线。
线和样条线标注可以用来训练仓库机器人准确地将箱子排成一排,或将物品放在传送带上。该标注最常见的应用是在无人驾驶汽车领域,通过标注车行道和人行道,可以训练自动驾驶车辆理解边界,并保持在一条车道上而不转向。

10.OCR转写
OCR转写这种类型的标注,可能大家听说的不是很多,它主要是对图像中的文字内容进行标记与转写,帮助训练和完善图片与文本识别模型。
二、图像数据标注概述
在深度学习领域,训练数据对训练结果有种至关重要的影响,在计算机视觉领域,除了公开的数据集之外,对很多应用场景都需要专门的数据集做迁移学习或者端到端的训练,这种情况需要大量的训练数据,取得这些数据方法有如下几种:
人工数据标注
自动数据标注
外包数据标注
人工数据标注的好处是标注结果比较可靠,自动数据标注一般都需要二次复核,避免程序错误,外包数据标注则在很多时候会面临数据泄密与流失风险。
常用的标注工具从标注工具的软件属性上分类:
客户端
WEB端标注工具
笔者强烈建议大家使用客户端标注工具或者离线的WEB端标注工具。在线的WEB端标注工具存在数据流失的风险,尤其是重要的数据,一定要更加小心谨慎。
十大常用工具
1.LabelImg
链接
https://github.com/tzutalin/labelImg下载以后根据作者提供的安装指南即可安装,如果安装不上怎么办,不用这么麻烦,下面这个地址提供了直接下载的地址,下载预编译exe即可:
https://github.com/zhaobai62/labelImg支持VOC2012格式与tfrecord自动生成。
强烈推荐,简单好用。
2.Labelme
链接
https://github.com/wkentaro/labelme支持对象检测、图像语义分割数据标注,实现语言为Python与QT。
支持矩形、圆形、线段、点标注。
支持视频标注。
支持导出VOC与COCO格式数据实例分割。
强烈推荐,实例分割都可以用它标注。

3.RectLabel
链接
https://rectlabel.com/
支持对象检测,图像实例分割数据标注。
支持导出YOLO、KITTI、COCOJSON与CSV格式。
读写Pascal VOC格式的XML文件。
4.OpenCV/CVAT
链接
https://github.com/opencv/cvat高效的计算机视觉标注工具,支持图像分类、对象检测框、图像语义分割、实例分割数据标注在线标注工具。支持图像与视频数据标注,最重要的是支持本地部署,无需担心数据外泄。

5.VOTT
链接
https://github.com/microsoft/VoTT微软发布的基于WEB方式本地部署的视觉数据标注工具。
支持图像与视频数据标注。
支持导出CNTK/Pascal VOC格式。
支持导出TFRecord、CSV、VoTT格式。
当前主要分支版本有V1与V2版本。
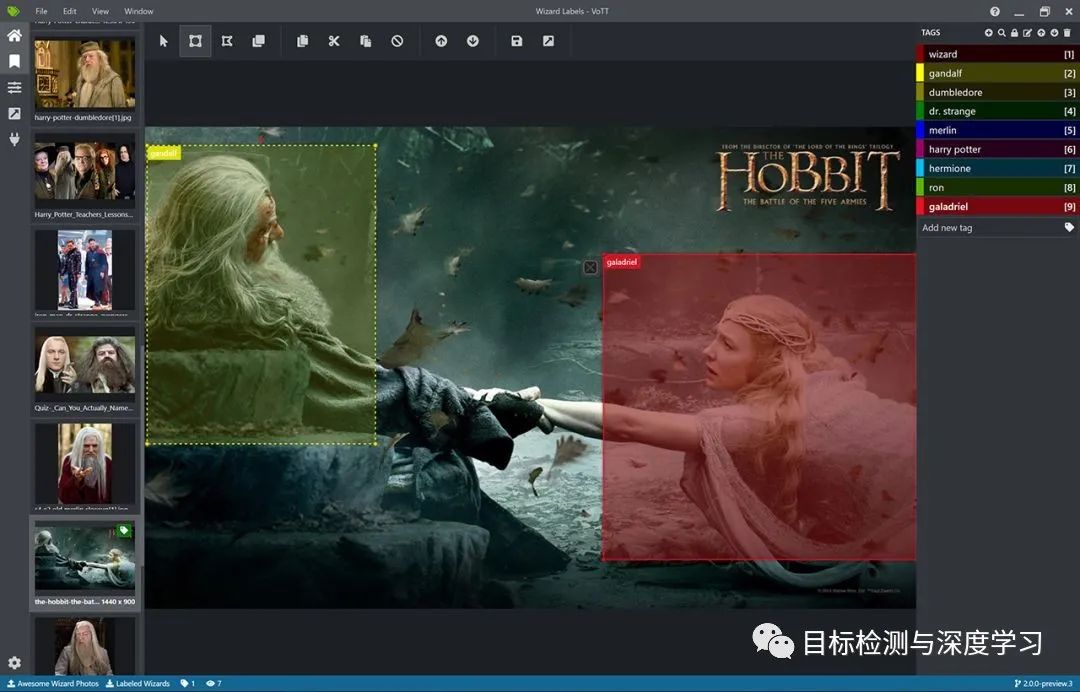
6.LableBox
链接
https://github.com/Labelbox/Labelbox支持对象检测框、实例分割数据标注。
WEB方式的标注工具。
提供自定义标注API支持。
纯JS+HTML操作支持。
7.VIA-VGG Image Annotator
链接
http://www.robots.ox.ac.uk/~vgg/software/via/VGG发布的图像标准工具。
支持对象检测、图像语义分割与实例分割数据标注。
基于WEB方式的标注工具。
可以下载运行部署在本地。
特别之处,对人脸数据标注提供了各种方便的操作,人脸数据标注首选工具。
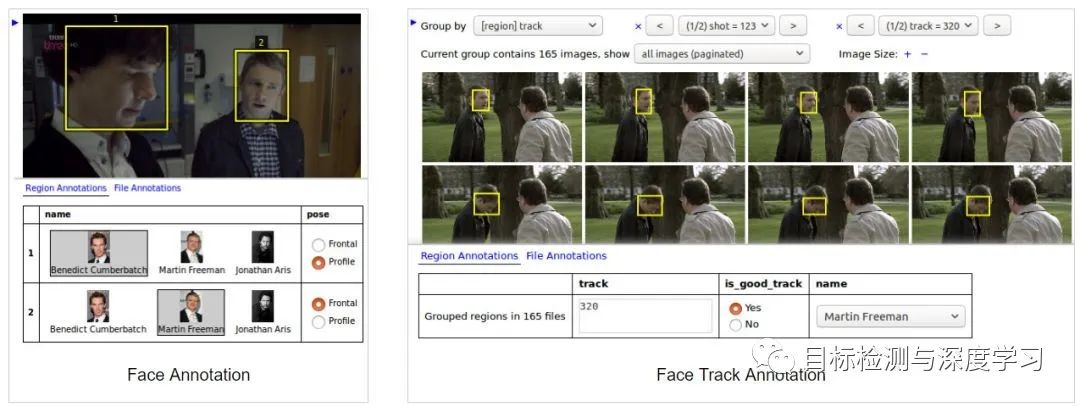
8.PixelAnnotationTool
链接
https://github.com/abreheret/PixelAnnotationTool图像语义分割与实例分割标注神器,交互式标注算法思想是基于OpenCV中分水岭算法实现。支持,可以直接下载编译好的二进制文件使用,链接如下:
https://github.com/abreheret/PixelAnnotationTool/releases
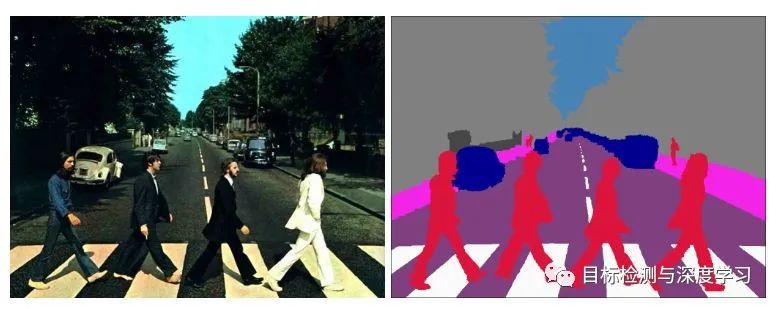
9.point-cloud-annotation-tool
链接
https://github.com/springzfx/point-cloud-annotation-tool3D点云数据标注神器。
支持点云数据加载、保存与可视化。
支持点云数据选择。
支持3D BOX框生成。
支持KITTI-bin格式数据。

10.Boobs
链接
https://github.com/drainingsun/boobs专属的YOLO BBox标注工具,支持图像数据标准为YOLO格式。
现在也支持VOC/COCO格式数据导出。
基于WEB方式的标注工具。
支持下载zip包本地部署。
无需服务器端支持,直接浏览器支持打开boobs.html即可开始数据标注。
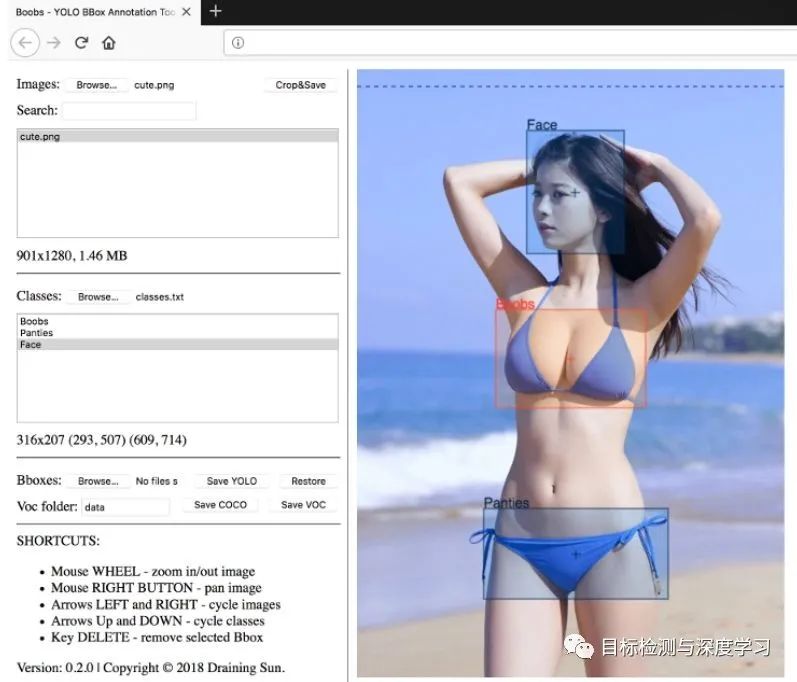
END
整理不易,点赞三连↓