
拥有SAM的标注工具,提高标注效率
特性
目前第一版提供以下功能,后期计划加入多模态大模型,满足更广泛的需求:
支持多边形、矩形、圆形、直线和点的图像标注。
支持文本检测、识别和
KIE(关键信息提取)标注。
支持检测-分类级联模型进行细粒度分类。
支持一键人脸和关键点检测功能。
支持转换成标准的
COCO-JSON、VOC-XML以及YOLOv5-TXT文件格式。
支持PaddlePaddle、OpenMMLab、Pytorch-TIMM等主流深度学习框架。
提供先进的检测器,包括
YOLOv5、YOLOv6、YOLOv7、YOLOv8、YOLOX以及DETR系列模型。
框架
添加模型推理是自动化标记任务的关键。AnyLabeling 的早期版本完成对 Segment Anything模型的支持。模型推理架构如下图所示:
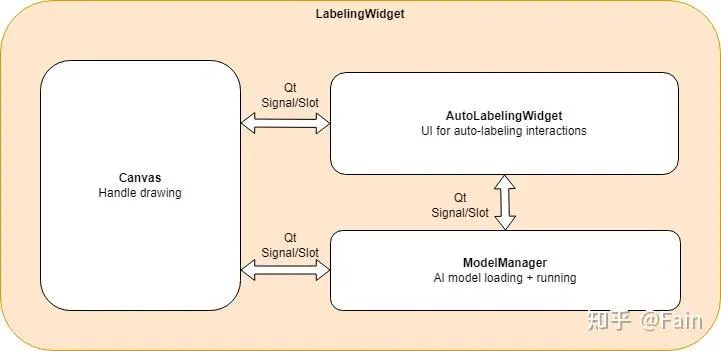
在AnyLabeling的架构中,LabelingWidget是任何功能的主要小部件。绘图区域由Canvas类处理。AutoLabelingWidget则作为自动标记功能和ModelManager的主要部件用于管理和运行 AI 模型。
SAM
SAM 是 Meta 的新细分模型。使用 11M 图像和 1B 分割掩码进行训练,它可以在不针对特定对象进行训练的情况下分割图像中的对象。出于这个原因,Segment Anything 是自动标记的一个很好的候选框,即使是从未见过的新对象。
优化点:
因为
Encoder的计算是需要时间的,所以我们可以把结果缓存起来,也可以对Encoder在以后的图片上做预计算。这将减少用户等待编码器运行的时间。
对于缓存,添加了一个
LRU缓存来保存编码器的结果。图像保存在缓存中,键是标签路径。当缓存中存在图像嵌入时,不会再次运行编码器,这样可以节省很多时间。缓存大小默认为 10 张图像。
对于预计算,创建一个线程来为下一个图像运行编码器。当加载新图像时,它将和下一张图像一起发送到工作线程进行编码器计算。之后,
image embedding会缓存到上面的LRU缓存中。如果图像已经在缓存中,工作线程将跳过它。
使用步骤
选择左侧的
Brain按钮以激活自动标记。
从下拉菜单
Model中选择Segment Anything Models类型的模型。模型精度和速度因模型而异。其中,Segment Anything Model (ViT-B)是最快的但精度不高。Segment Anything Model (ViT-H)是最慢和最准确的。Quant表示量化过的模型。
使用自动分割标记工具标记对象。
+Point:添加一个属于对象的点。
-Point:移除一个你想从对象中排除的点。
+Rect:绘制一个包含对象的矩形。Segment Anything 将自动分割对象。
清除:清除所有自动分段标记。
完成对象(f):当完成当前标记后,我们可以及时按下快捷键f,输入标签名称并保存对象。
注意事项
X-AnyLabeling在第一次运行任何模型时,需要从服务器下载模型。因此,可能需要一段时间,这具体取决于本地的网络速度。
第一次 AI 推理也需要时间。请耐心等待。
后台任务正在运行以缓存 Segment Anything 模型的“编码器”。因此,在接下来的图像中自动分割工作需要时间会缩短,无须担心。
集成方式
Segment Anything Model 分为两部分:一个很heavy的编码器和一个lightweight解码器。编码器从输入图像中提取图像嵌入。基于嵌入和输入提示(点、框、掩码),解码器生成输出掩码。解码器可以在单掩码或多掩码模式下运行。
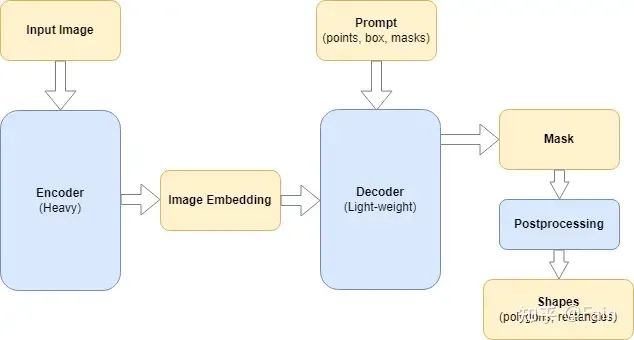
在演示中,Meta 在服务器中运行编码器,而解码器可以在用户的浏览器中实时运行,如此一来用户便可以在其中输入点和框并立即接收输出。在本项目中,我们还为每个图像只运行一次编码器。之后,根据用户提示的变化(点、框),运行解码器以生成输出掩码。项目添加了后处理步骤来查找轮廓并生成用于标记的形状(多边形、矩形等)。
文本 OCR 标签
文本 OCR 标签是许多标注项目中的一项常见任务,但遗憾的是在 Labelme 和 LabelImg 中仍然没有得到很好的支持。AnyLabeling 中完美支持了这一项新功能。
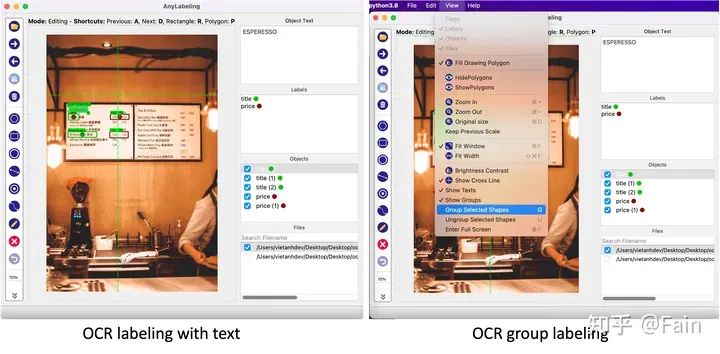
第一个版本支持以下标签工具:
图像文本标签
用户可以切换到编辑模式并更新图像的文本——可以是图像名称或图像描述。
文本检测标签
当用户创建新对象并切换到编辑模式时,可以更新对象的文本。
文本分组
想象一下,当使用 KIE(键信息提取)时,需要将文本分组到不同的字段中,包含标题和值。在这种情况下,你可以使用文本分组功能。当创建一个新对象时,我们同样可以通过选择它们并按G将其与其他对象组合在一起。分组的对象将用相同的颜色标记。当然,也可以按快捷键U取消组合。
注:标注的文本和分组信息将与其他标注保存在同一个 JSON 文件中。文本将保存在text对象的字段中,组信息将保存在字段中group_id。
检测分类模型
这一块相比比较简单。我们主要讲解下如何加载自定义模型,这将使你能够使用自己的模型进行自动标记。如果你有一个已根据自己的数据训练过的自定义模型并希望将其用于自动标记,这将非常有用。此外,还可以创建一个标签 - 训练循环来逐步改进私有模型。通常来说,笔者建议在项目初期阶段可以基于 SAM 利用点或矩阵提示快速完成数据标注,等后期达到一定数据量训练完一个初版模型后再基于检测或检测+分类模型进行一键自动标注。
阅读原文进入github了解详细