
深度学习中的轻量级网络架构总结与代码实现

来源:深度学习技术前沿 本文约2400字,建议阅读5分钟 本次介绍了深度学习中轻量级网络架构总结与代码的实现。
导读
Github地址:
https://github.com/murufeng/awesome_lightweight_networks
安装使用
pip install light_cnns
项目目录

MobileNets系列
MobileNetV1
论文地址:
https://arxiv.org/abs/1704.04861
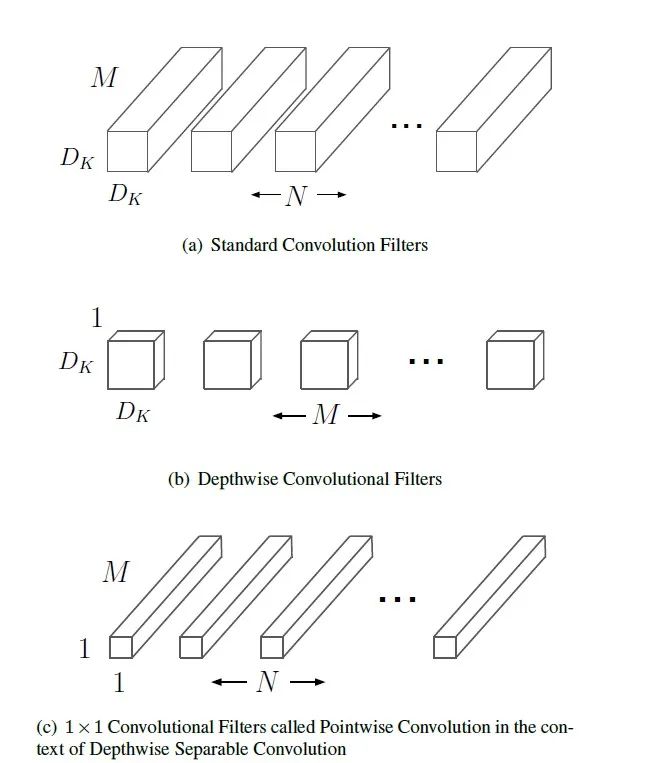
代码实现
import torch
from light_cnns import mbv1
model = mbv1()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())
MobileNetv2
论文地址:
https://arxiv.org/abs/1704.04861
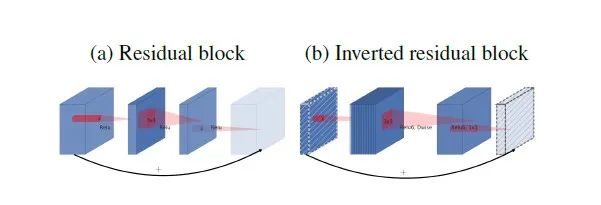
增强了梯度的传播,显著减少推理期间所需的内存占用。 使用 RELU6(最高输出为 6)激活函数,使得模型在低精度计算下具有更强的鲁棒性。 在经过projection layer转换到低维空间后,将第二个pointwise convolution后的 ReLU6改成Linear结构,保留了特征多样性,增强网络的表达能力(Linear Bottleneck)
网络模型结构如下:
代码实现
import torch
from light_cnns import mbv2
model = mbv2()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())
MobileNetv3
论文地址:
https://arxiv.org/abs/1905.02244
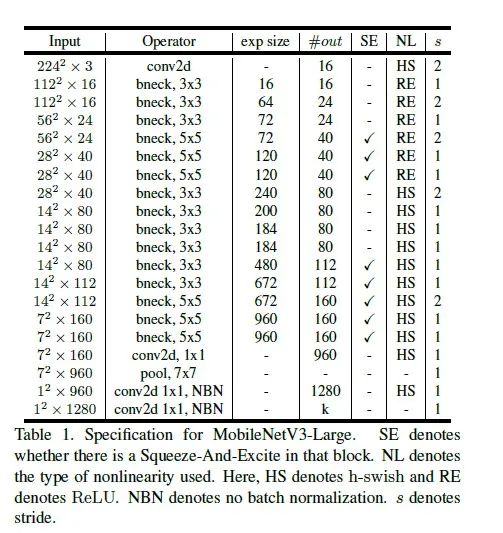
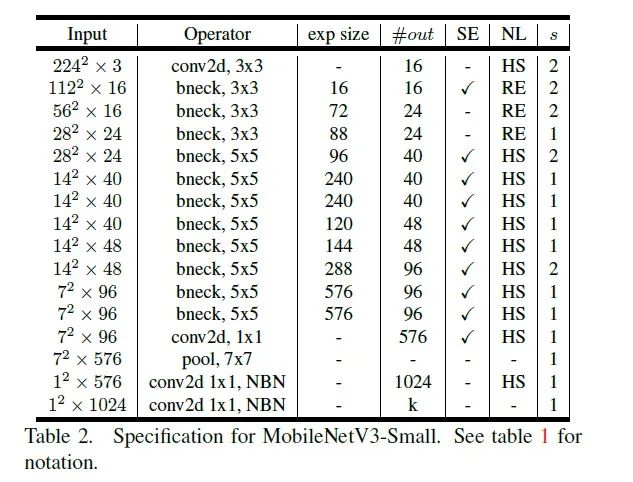
网络的架构基于NAS实现的MnasNet(效果比MobileNetV2好) 论文推出两个版本:Large 和 Small,分别适用于不同的场景; 继承了MobileNetV1的深度可分离卷积 继承了MobileNetV2的具有线性瓶颈的倒残差结构 引入基于squeeze and excitation结构的轻量级注意力模型(SE) 使用了一种新的激活函数h-swish(x) 网络结构搜索中,结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt 算法获得卷积核和通道的最佳数量 修改了MobileNetV2网络后端输出head部分;
具体网络结构如下:
代码实现
import torch
from light_cnns import mbv3_small
#from light_cnns import mbv3_large
model_small = mbv3_small()
#model_large = mbv3_large()
model_small.eval()
print(model_small)
input = torch.randn(1, 3, 224, 224)
y = model_small(input)
print(y.size())
MobileNext
Rethinking Bottleneck Structure for Efficient Mobile Network Design
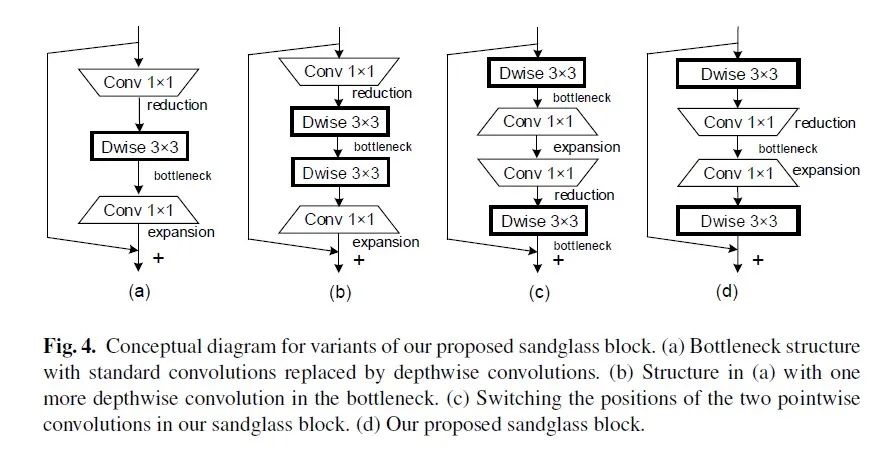
针对MobileNetV2的核心模块逆残差模块存在的问题进行了深度分析,提出了一种新颖的SandGlass模块,它可以轻易的嵌入到现有网络架构中并提升模型性能。Sandglass Block可以保证更多的信息从bottom层传递给top层,进而有助于梯度回传;执行了两次深度卷积以编码更多的空间信息。
网络模型结构如下:
代码实现
import torch
from light_cnns import mobilenext
model = mobilenext()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())
ShuffleNet系列
ShuffleNetv1
论文地址:
https://arxiv.org/abs/1707.01083
网络模型结构如下:

代码实现
import torch
from light_cnns import shufflenetv1
model = shufflenetv1()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())
ShuffleNetv2
论文地址 :
https://arxiv.org/abs/1807.11164
网络模型结构如下:

import torch
from light_cnns import shufflenetv2
model = shufflenetv2()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())
华为诺亚轻量级网络系列
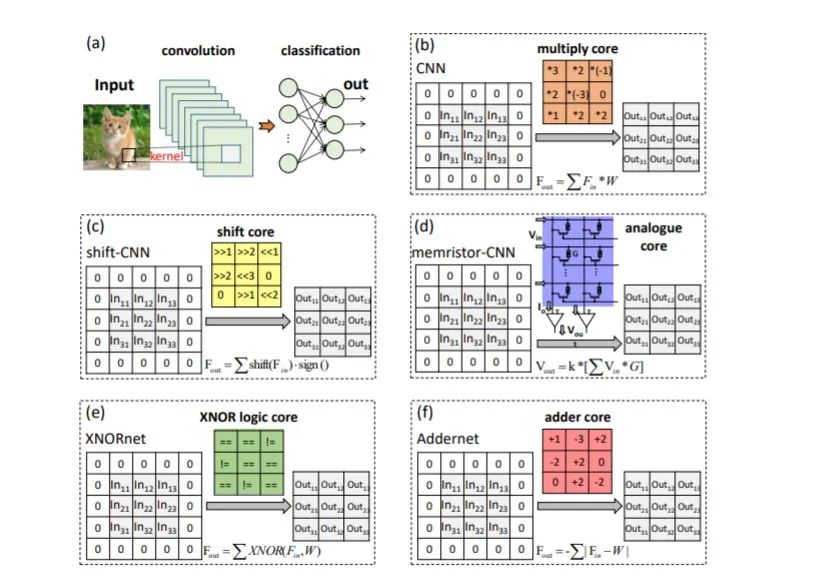
AdderNet:Do We Really Need Multiplications in Deep Learning?
网络模型结构如下:
import torch
from light_cnns import resnet20
model = resnet20()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())
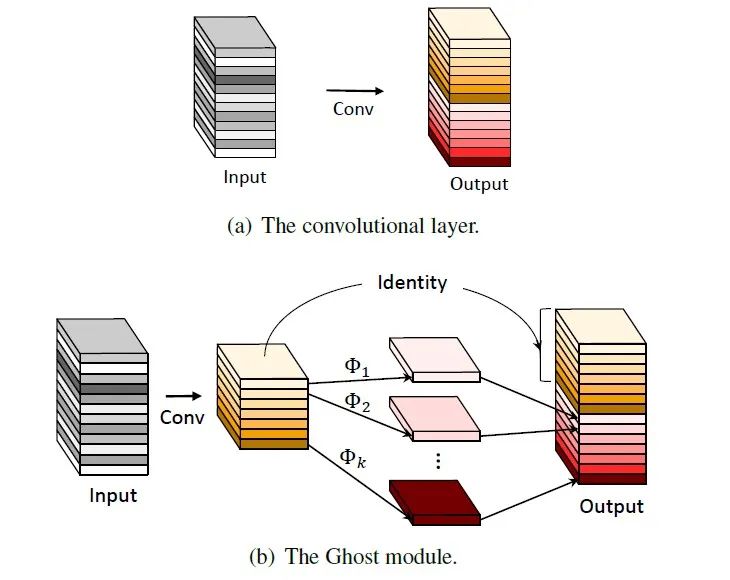
GhostNet:More Features from Cheap Operations
简介
网络模型结构如下:
代码实现
import torch
from light_cnns import ghostnet
model = ghostnet()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())
轻量级注意力网络架构
Coordinate Attention for Efficient Mobile Network Design
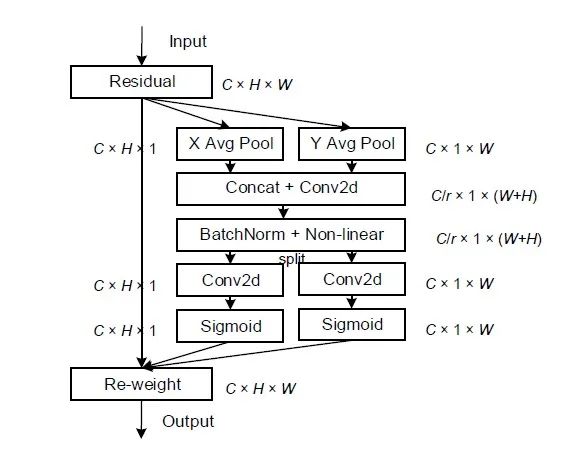
Code
import torch
from light_cnns import mbv2_ca
model = mbv2_ca()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())评论