
CVPR 2020 | CenterMask : Anchor-Free 实时实例分割(长文详解)
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

1. Mask R-CNN升级,backbone、FPN和head都改进了
2. ROIAlign越看越迷了,得跑跑实验了
CVPR 2020,原文链接:
https://arxiv.org/abs/1911.06667
基于PyTorch,Detectron2,原文开源链接:
https://github.com/youngwanLEE/CenterMask
We propose a simple yet efficient anchor-free instance
segmentation, called CenterMask, that adds a novel spatial
attention-guided mask (SAG-Mask) branch to anchor-free one stage object
detector (FCOS) in the same vein with Mask R-CNN. Plugged into the FCOS
object detector, the SAG-Mask branch predicts a segmentation mask on
each detected box with the spatial attention map that helps to focus on
informative pixels and suppress noise.
我们提出了一个简单而有效的anchor-free实例分割方法,称为CenterMask,在Mask
R-CNN基础上使用了FCOS和SAG-Mask。插入FCOS对象检测器后,SAG-Mask分支可以使用空间注意力特征图来预测每个检测框上的分割蒙版,该图有助于将注意力集中在内容丰富的像素上并抑制噪声。
We also present an improved backbone networks, VoVNetV2,
with two effective strategies: (1) residual connection for alleviating
the optimization problem of larger VoVNet and (2) effective
Squeeze-Excitation (eSE) dealing with the channel information loss
problem of original SE. With SAG-Mask and VoVNetV2, we deign CenterMask
and CenterMask-Lite that are targeted each to large and small models,
respectively.
我们还提出了一种改进的backbone网络VoVNetV2,它具有两种有效的策略:(1)残差连接能缓解较大VoVNet的优化问题;(2)处理原始SE的信道信息丢失问题的eSE。借助SAG-Mask和VoVNetV2,我们分别设计了分别针对大型和小型模型的CenterMask和CenterMask-Lite。
Using the same ResNet-101-FPN backbone, CenterMask achieves 38.3%,
surpassing all previous state-of-the-art methods while at a much faster
speed. CenterMask-Lite also outperforms the state-of-the-art by large
margins at over 35fps on Titan Xp. We hope that CenterMask and VoVNetV2
can serve as a solid baseline of real-time instance segmentation and
backbone network for various vision tasks, respectively.
使用相同的ResNet-101-FPN
backbone,CenterMask可以达到38.3%,以更快的速度超越了所有以前的最新方法。CenterMask-Lite在Titan
Xp上也以超过35
fps的速度大幅领先于最新技术。我们希望CenterMask和VoVNetV2可以分别作为用于各种视觉任务的实时实例分割和backbone网络的坚实基准。
最近,实例分割已取得了超越对象检测的巨大进步。最具代表性的方法Mask R-CNN扩展到对象检测(例如Faster
R-CNN),已成为COCO基准测试的主导,因为可以通过检测对象然后预测每个盒子上的像素来轻松解决实例分割问题。但是,即使有许多改进Mask
R-CNN的工作,但考虑到实例分割速度的工作却很少。尽管由于YOLACT的并行结构和极其轻巧的组装过程,它是第一个实时的one-stage实例分割,但是与Mask
R-CNN的准确性差距仍然很大。因此,我们旨在通过提高准确性和速度来弥合差距。
Mask R-CNN基于two-stage对象检测器(例如,Faster
R-CNN),该对象首先生成框候选,然后预测框的位置和分类,而YOLACT建立在直接检测框的one-stage检测器(RetinaNet)上,没有候选步骤。然而,这些物体检测器严重依赖于预定义anchor,该预定义anchor对超参数(例如,输入大小、纵横比、比例等)和不同的数据集敏感。此外,由于它们密集地放置锚框以提高召回率,因此过多的anchor
box会导致正/负样本的不平衡以及较高的计算/内存成本。为了解决anchor
box的这些缺点,近来,许多工作倾向于通过使用角/中心点从anchor变成anchor-free,与基于anchor的检测器相比,这导致了更高的计算效率和更好的性能。
因此,我们设计了一个简单但有效的anchor-free,one-stage实例分割,称为CenterMask,在Mask
R-CNN基础上使用了FCOS和SAG-Mask。插入FCOS对象检测器后,我们的空间注意力引导蒙版(SAG-Mask)分支将使用FCOS检测器中的预测框来预测每个关注区域(RoI)上的分割蒙版。SAG-Mask中的空间注意模块(SAM)帮助遮罩分支将注意力集中在有意义的像素上,并抑制无关紧要的像素。
在提取每个RoI上的特征以进行掩码预测时,应考虑RoI比例来分配每个RoI池化。Mask
R-CNN提出了一个新的赋值函数,称为RoIAlign,它不考虑输入比例。因此,我们设计了一种具有比例尺的RoI分配函数,该函数考虑了输入比例,更加合适。我们还提出了一种基于VoVNet的更有效的骨干网VoVNetV2,由于其One-shot
Aggregation(OSA),它比ResNet和DenseNet具有更好的性能和更快的速度。在下图底部)中,我们发现将OSA模块堆叠在VoVNet中会使性能下降(例如VoVNetV1-99)。我们将此现象视为ResNet的动机,因为梯度的反向传播受到干扰。因此,我们将残差连接添加到每个OSA模块中以简化优化,这使VoVNet更深,从而提高了性能。
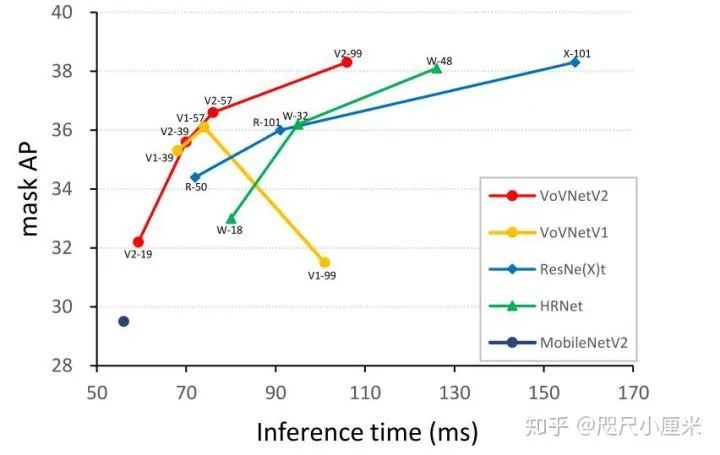
在Squeeze-Excitation(SE)通道注意模块中,发现全连接的层会减小通道大小,从而减少计算负担并意外地导致通道信息丢失。因此,我们将SE模块重新设计为eSE,用一个保持信道尺寸的FC层替换了两个FC层,从而防止了信息丢失,进而提高了性能。通过残差连接和eSE模块,我们建议使用各种规模的VoVNetV2。从轻量级VoVNetV2-19、基本VoVNetV2-39/57和大型模型VoVNetV2-99,它们对应于MobileNet-V2、ResNet-50/101和HRNet-W18/32和ResNeXt-32x8d。
借助SAG-Mask和VoVNetV2,我们设计了CenterMask和CenterMask-Lite,分别针对大型和小型模型。大量实验证明了CenterMask、CenterMask-Lite和VoVNetV2的有效性。使用相同的ResNet-101骨干,CenterMask在COCO实例和检测任务上的性能优于以前所有的最新单个模型,但速度要快得多。带有VoVNetV2-39
bakcbone的CenterMask-Lite还实现了33.4%的mask AP / 38.0%的box AP,在Titan
Xp上以超过35fps的速度分别以2.6/7.0 AP的增益实现了最新的实时实例分割YOLACT。
3.1 FCOS
与FCN一样,FCOS是按像素预测方式进行的anchor-free和proposal-free的对象检测。诸如Faster
R-CNN、YOLO和RetinaNet之类的最先进的物体检测器都使用预定义anchor的概念,该anchor需要进行复杂的参数调整和与训练中的IoU相关的复杂计算。如果没有anchor,则FCOS会直接预测4D向量以及特征图级别上每个空间位置处的类标签。如之前架构图所示,4D向量嵌入从边界框的四个侧面到位置(例如,左,右,顶部和底部)的相对偏移。另外,FCOS引入了centerness分支以预测像素到其相应边界框中心的偏离,从而提高了检测性能。避免了anchor的复杂计算,FCOS降低了内存/计算成本,但性能也优于基于anchor的对象检测器。由于FCOS的效率和良好的性能,我们设计了基于FCOS对象检测器的CenterMask。
3.2 架构
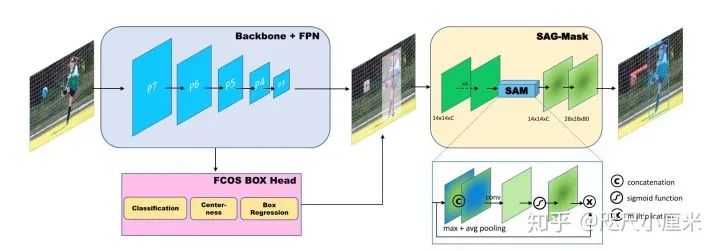
下图显示了CenterMask的总体架构。CenterMask由三部分组成:(1)用于特征提取的主干,(2)FCOS检测head和(3)遮罩head。遮罩对象的过程包括以下步骤:从FCOS盒头检测对象,然后以像素为单位预测裁剪区域内部的分割遮罩。
3.3 Adaptive RoI Assignment Function
在FCOS中预测了对象候选后,CenterMask使用与Mask
R-CNN相同的预测框区域来预测分割蒙版。由于RoI是根据特征金字塔网络(FPN)中不同级别的特征图预测的,因此提取特征的RoI
Align应相对于RoI比例以不同的特征图比例进行分配。具体而言,必须将大规模RoI分配给更高的特征级别,反之亦然。基于Mask
R-CNN的two-stage检测器使用FPN中的公式1来确定要分配的特征图( )。
)。 其中,
其中,  ,
, 
是每个ROI的宽度和高度。然而,式(1)不适合基于one-stage检测器的CenterMask,主要有2个原因。第一是式(1)微调自two-stage检测器,相较于one-stage检测器使用了不同的特征级别。具体地说,two-stage检测器使用了P2-P5(4-32),而ome-stage使用了P3-P7(8-128),在低分辨率上有更大的感受野。除此之外,公式1中的经典的ImageNet预训练大小224是硬编码的,并不适应特征尺度的变化。对于RoI的面积为  ,当输入尺寸为
,当输入尺寸为  且特征P4相对于输入尺寸而言面积较小时,将RoI分配给相对较高的示例,从而减少了小物体AP。
且特征P4相对于输入尺寸而言面积较小时,将RoI分配给相对较高的示例,从而减少了小物体AP。
因此,我们将公式2定义为适用于基于CenterMask的one-stage检测器的新RoI分配函数。

其中,  是backbone中特征图最后一个层次,例如7。
是backbone中特征图最后一个层次,例如7。 是输入图像和ROI的面积。式(2)能够自适应地分配ROI pooling,根据input/ROI的面积之比来缩放。如果 k 小于最小的层次,比如3, k将会被裁剪到最小的层次。具体地说,如果RoI的面积大于输入区域的一半,则将RoI分配给最高特征级别(例如P7)。相反,虽然式(1)用
是输入图像和ROI的面积。式(2)能够自适应地分配ROI pooling,根据input/ROI的面积之比来缩放。如果 k 小于最小的层次,比如3, k将会被裁剪到最小的层次。具体地说,如果RoI的面积大于输入区域的一半,则将RoI分配给最高特征级别(例如P7)。相反,虽然式(1)用  将P4分配给RoI,但式(2)确定了Kmax-5级别,这可能是RoI区域的最小特征级别,比输入大小小约20倍。我们发现,提出的RoI分配方法比式(1)改善了小对象AP,因为它的自适应和可识别比例的分配策略。从消融研究中,我们将 Kmax 设置为P5,将 Kmin 设置为P3。
将P4分配给RoI,但式(2)确定了Kmax-5级别,这可能是RoI区域的最小特征级别,比输入大小小约20倍。我们发现,提出的RoI分配方法比式(1)改善了小对象AP,因为它的自适应和可识别比例的分配策略。从消融研究中,我们将 Kmax 设置为P5,将 Kmin 设置为P3。
3.4 Spatial Attention-Guided Mask
近来,注意力方法已被广泛地应用于物体检测,因为它有助于关注重要特征,同时也抑制不必要的特征。特别是,通道注意力在跨通道的特征图上强调“要注意什么”,而空间注意力则关注“何处”是信息丰富的区域。受空间注意力机制的启发,我们采用空间注意力模块来指导mask
head对有意义的像素进行突出,并抑制无用的像素。
head对有意义的像素进行突出,并抑制无用的像素。
因此,我们设计了一个空间注意力导向蒙版模块(SAG-Mask),如之前架构图所示。一旦RoI Align以14×14的分辨率提取了预测RoI内的特征,这些特征将依次馈入四个卷积层和空间注意力模块(SAM)。总的过程是输入为 ,按照通道进行平均值和最大值池化,输出
,按照通道进行平均值和最大值池化,输出 。拼接后进行一个3*3卷积,然后经过sigmoid函数和原输入相乘。然后使用2*2的转置卷积进行上采样2倍,最后用1*1来预测具体mask的类别。
。拼接后进行一个3*3卷积,然后经过sigmoid函数和原输入相乘。然后使用2*2的转置卷积进行上采样2倍,最后用1*1来预测具体mask的类别。
3.5 VoVNetV2 backbone
3.5 VoVNetV2 backbone
在本节中,我们提出了更有效的骨干网络VoVNetV2,以进一步提高CenterMask的性能。VoVNetV2是从VoVNet改进而来的,方法是在VoVNet中添加残差连接和提出的eSE注意力模块。VoVNet是一种计算和节能的backbone网络,由于One-Shot
Aggregation(OSA)模块,可以有效地呈现多样化的特征表示。
Aggregation(OSA)模块,可以有效地呈现多样化的特征表示。
如(a)所示,OSA模块由连续的卷积层组成,并立即聚合后续的特征图,可以有效捕获各种感受野,并且在准确性和速度方面均优于DenseNet和ResNet。
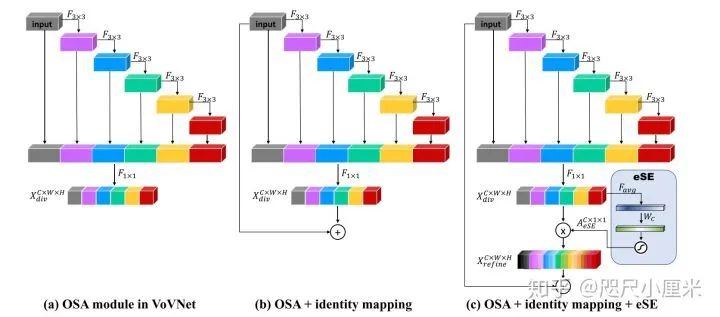
残差连接:即使具有有效且多样化的特征表示,VoVNet在优化方面仍存在局限性。随着OSA模块在VoVNet中堆叠(例如更深),我们观察到更深模型的准确性已饱和或降级。具体来说示了VoVNetV1-99的准确性低于VoVNetV1-57的准确性。基于ResNet的动机,我们推测由于转换函数(例如卷积)的增加,堆叠OSA模块会使梯度的反向传播逐渐变得困难。因此,如(b)所示,我们还将恒等映射添加到OSA模块。正确地,输入路径连接到OSA模块的末端,该OSA模块能够像ResNet这样在每个阶段以端到端的方式反向传播每个OSA模块的梯度。恒等映射提高了VoVNet的性能,也使VoVNet可以扩展其深度,例如VoVNet-99。
Effective Squeeze-Excitation (eSE):为了进一步提高VoVNet的性能,我们还提出了一个通道注意力模块,即Effective
Squeeze-Excitation
(eSE),可以更有效地改善原始SE。SE是CNN架构中采用的一种代表性的通道注意力方法,用于对特征图通道之间的相互依赖性进行显式建模,以增强其表示能力。SE模块通过全局平均值池化压缩空间相关性,以学习特定于通道的描述符,然后使用两个全连接(FC)层以及Sigmoid型函数来重新缩放输入特征图,以仅突出显示有用的通道。
但是,假设SE模块具有局限性:由于尺寸减小而导致信道信息丢失。一般为了避免高模型复杂性负担,SE模块的两个FC层需要减小通道尺寸。具体来说,虽然第一个FC层使用缩小率r将输入特征通道C缩小到C/r,但第二FC层将缩小的通道扩展到原始通道大小C。结果,这种通道降维会导致通道信息丢失。
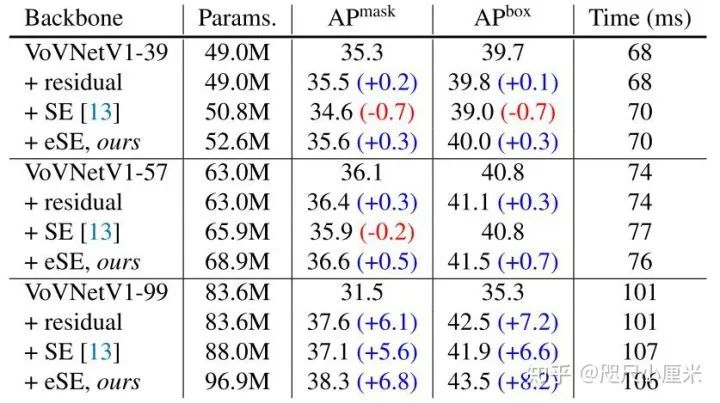
因此,我们提出的eSE仅使用具有C通道的一个FC层,而不使用不降低通道尺寸的两个FC,从而保留通道信息,从而提高性能,如题过程如(c)。(两层FC变一层而已)
3.6 Implementation details
由于CenterMask基于FCOS对象检测器构建,因此我们遵循FCOS的超参数,但正分数阈值0.03而不是0.05,因为FCOS在初始训练时间内不能很好地生成正RoI样本。在检测步骤中使用具有256个通道的FPN级别3至7时,在mask步骤中使用P3〜P7。我们还使用了mask评分功能,该功能会根据“Mask
R-CNN”中的预测遮罩质量(例如,mask IoU)重新校准分类得分。
CenterMask-Lite:为了实现实时处理,我们尝试使用所提出的CenterMask-Lite。我们缩小了三个部分的大小:backbone,box
head和mask
head。在骨干网络中,首先,我们将FPN的通道C从256减少到128,这可以减少FPN中3×3卷积的输出,还可以减少box和mask的输入尺寸。然后,我们用更轻量的VoVNetV2-19代替骨干网络,该网络在每个阶段具有4个OSA模块,每个模块由3个卷积层组成,而不是VoVNetv2-39/57中的5个。在box
head中,每个分类和box分支上有四个具有256个通道的3×3卷积层,其中centerness分支与box分支共享。我们将128个通道的卷积层数从4个减少到2个。最后,在mask
head中,我们还将特征提取器和mask计分部分中的卷积层和通道数分别从(4,256)减少到(2,128)。

除非另有说明,否则将调整输入图像的大小,使其沿较短的一面具有800像素,而其较长的一面则小于或等于1333。我们使用随机梯度下降(SGD)进行90K迭代(〜12
epochs)训练CenterMask,最小批量为16张图像,初始学习率为0.01,在60K和80K迭代中分别降低了10倍。我们分别使用0.0001的权重衰减和0.9的动量。所有骨干模型均由ImageNet预先训练的权重初始化。
推理:在测试时,FCOS检测部分会产生50个高分检测框,然后mask分支使用它们来预测每个RoI上的分段mask。CenterMask/CenterMask-Lite对较短的一侧分别使用800/600像素来调整比例。
我们评估CenterMask在COCO基准上的有效性。所有模型都在train2017上进行了训练,val2017用于消融研究。最终结果报告在test-dev上,用于与最新技术进行比较。
4.1 Ablation study

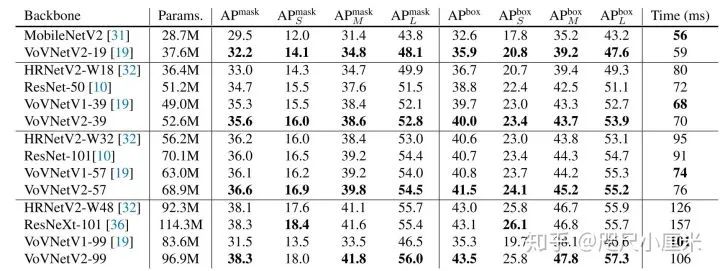
4.2 Comparison with state-of-the-arts methods
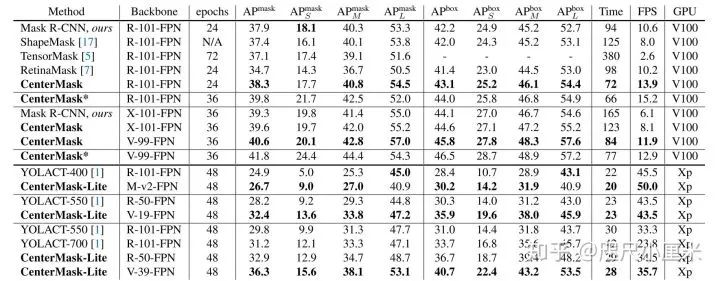
在上表中,我们观察到使用相同的ResNet-101主干,Mask
R-CNN在小对象上显示出比CenterMask更好的性能。我们推测,与CenterMask(P3)相比,Mask
R-CNN使用更大的特征图(P2),其中Mask分支可以提取比P3特征图更精细的对象空间布局。我们注意到像Mask
R-CNN的技术一样,仍有改进one-stage实例分割性能的空间。
我们提出了一种实时的anchor-free的one-stage实例分割和更有效的骨干网络。通过在anchor-free的one-stage实例检测中添加空间注意力引导的遮罩分支,CenterMask以实时速度实现了最先进的性能。新提出的VoVNetV2骨干网从轻量级模型到大型模型,都使CenterMask在速度和准确性方面达到了均衡的性能。我们希望CenterMask将作为实时实例分割的基准。我们还相信,我们提出的VoVNetV2可以用作各种视觉任务的强大而高效的骨干网络。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!