
3D目标检测/点云/遥感数据集汇总
点击左上方蓝字关注我们

数据集:
1. 点云分类(罗蒙诺索夫莫斯科国立大学) 2. Semantic3D 3. Robotic 3D Scan Repository 4. KITTI 5. Beyond PASCAL: A Benchmark for 3D Object Detection in the Wild 6. Oakland 3-D Point Cloud Dataset(奥克兰 ) 8.武大遥感数据 9 . DOTA数据集(images) 10. DIOR 11.LEVIR 12. NWPU VHR-10 13. INRIA aerial image dataset 14. 悉尼城市建筑 15. isprs点云数据 16. 中科院自动化所数据集 17. ILSVRC 18. ImageNet 19. SUN database 20. SUN-RGBD数据集 21. ModelNet 22. NYU Depth V2 dataset 23. DTU dataset 24. 普林斯度视觉和机器人实验室数据集
1. 点云分类(罗蒙诺索夫莫斯科国立大学)
 Legend: red — ground, black — building, navy — car, green — tree, cyan — low-vegetation.
Legend: red — ground, black — building, navy — car, green — tree, cyan — low-vegetation.
链接:点云分类:https://graphics.cs.msu.ru/en/node/922
2. Semantic3D
大规模点云分类基准,它提供了一个带有大标签的自然场景的3D点云数据集,总计超过40亿个点,8个类别标签。并且还涵盖了多种多样的城市场景。
该数据集是一个大型户外数据集,使用地面激光扫描仪获得,总共包含 40亿个点。数据集包含了各种城市和乡村场景,如农场,市政厅,运动场,城堡和广场。该数据集包含 15 个训练数据集和 15 个测试数据集,另外还包括 4 个缩减了的测试数据集。数据集中的点都含有 RGB 和强度信息,并被标记为 8 个语义类别。


8个类别标签的分类基准,即 1:人造地形;2:自然地形;3:高植被;4:低植被;5:建筑物;6:硬景观;7:扫描人工制品,8:汽车 。附加标签 0:未标记点,标记没有地面真值的点
链接:Semantic3D:http://www.semantic3d.net/
3. Robotic 3D Scan Repository
包含大量的Riegl和Velodyne雷达数据,可能更适合slam研究
Authors Johannes Schauer, Andreas Nüchter from the University of Würzburg, Germany
Date 2016-10-27
Location Würzburg marketplace (geo:49.79445,9.92928)
Scanner Riegl VZ-400
#scans 6
#points 86585411
Datatype X,Y,Z (lefthanded) and reflectance in uosr format
Download wue_city.tar.xz
MD5 9b38cad10038ee4f3abbdd7b8431fa27
Filesize 1187 MiB (5117 MiB unpacked)
README README.wue_city


Robotic 3D Scan Repository:http://kos.informatik.uni-osnabrueck.de/3Dscans/
4. KITTI
这个数据集来自德国卡尔斯鲁厄理工学院的一个项目,其中包含了利用KIT的无人车平台采集的大量城市环境的点云数据集(KITTI),这个数据集不仅有雷达、图像、GPS、INS的数据,而且有经过人工标记的分割跟踪结果,可以用来客观的评价大范围三维建模和精细分类的效果和性能。
3D对象检测基准由7481个训练图像和7518个测试图像以及相应的点云组成,包括总共80256个带标签的对象,单声道和立体相机数据,包括校准、测程法等等。

链接:http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
5. Beyond PASCAL: A Benchmark for 3D Object Detection in the Wild
PASCAL3D +数据集,它是用于3D对象检测和姿态估计的新颖且具有挑战性的数据集。PASCAL3D +通过3D注释增强了PASCAL VOC 2012 [12]的12个刚性类别。此外,从ImageNet 为每个类别添加了更多图像。与现有的3D数据集相比,PASCAL3D +图像具有更大的可变性,并且每个类别平均有3,000多个对象实例。该数据集将为研究3D检测和姿态估计提供丰富的测试平台,并将有助于显着推动这一领域的研究。在新的数据集上提供了DPM 的变化结果,用于在不同情况下进行对象检测和视点估计。
物体检测和姿态估计的基准(10个类别,每个类别有10个对象实例)
链接:https://cvgl.stanford.edu/projects/pascal3d.html
6. Oakland 3-D Point Cloud Dataset(奥克兰 )
这个数据库的采集地点是在美国卡耐基梅隆大学周围,数据采集使用Navlab11,配备侧视SICK LMS激光扫描仪,用于推扫。其中包含了完整数据集、测试集、训练集和验证集。
链接:http://www.cs.cmu.edu/~vmr/datasets/oakland_3d/cvpr09/doc/


7. Generic 3D Representation via Pose Estimation and Matching
该数据集涵盖纽约,芝加哥,华盛顿,拉斯维加斯,佛罗伦萨,阿姆斯特丹,旧金山和巴黎的市中心和周边地区。包含这些城市的3D模型以及街景图像和元数据,这些模型已进行地理注册并手动生成。
链接:http://3drepresentation.stanford.edu/

8.武大遥感数据
WHU-RS19 Dataset 是一个遥感影像数据集,其包含 19 个类别的场景影像共计 1005 张,其中每个类别有 50 张。WHU-RS19是从谷歌卫星影像上获取19类遥感影像,可用于场景分类和检索。
该数据集由武汉大学于 2011 年发布,相关论文有《Satellite Image Classification via Two-layer Sparse Coding with Biased Image Representation》。
建议的基准数据集包括 115 次扫描,共收集了 17.4 亿多个 3D 点,这些点来自 11 个不同的环境(即地铁站、高速铁路站台、山区、森林、公园、校园、住宅、河岸、文物建筑、地下挖掘和隧道),这里仅取文物与住宅点云。

链接:https://download.csdn.net/download/cp_oldy/10666758(我没下载,不知可用否)
暂无有效链接,需要可向武大申请使用
9 . DOTA数据集(images)
数据集是遥感图像,DOTA1.5是在DOTA基础上扩增的数据集
DOTA数据集包含2806张航空图像,尺寸大约为4kx4k,包含15个类别共计188282个实例。其标注方式为四点确定的任意形状和方向的四边形(区别于传统的对边平行bbox)
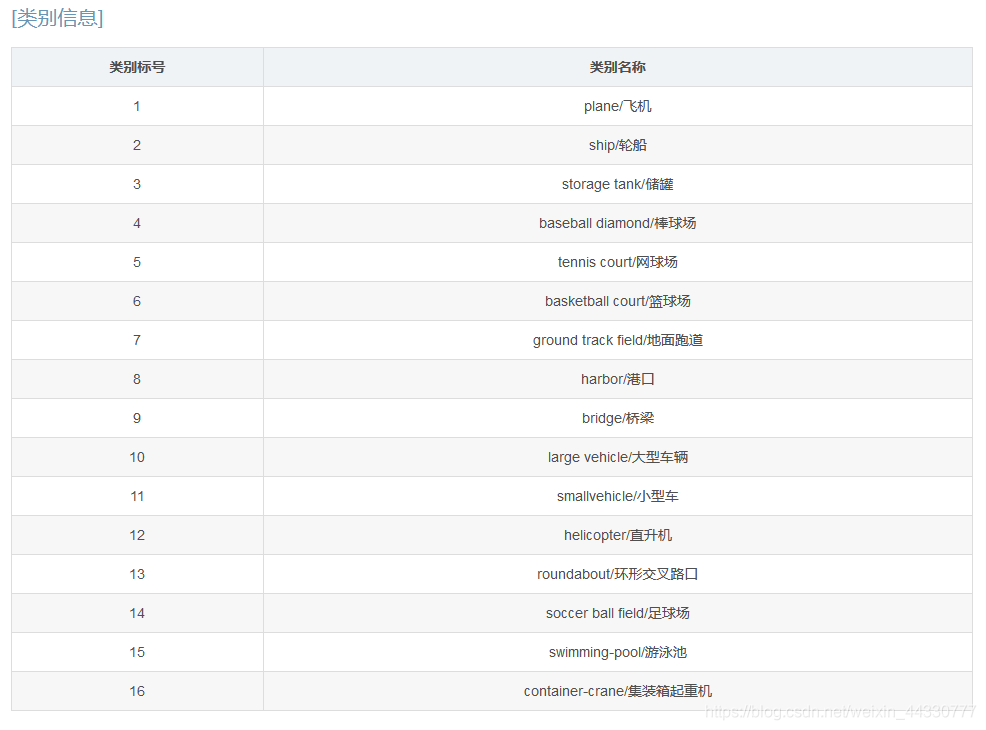
标注格式:
在数据集中,每个实例的位置由四边形边界框注释,可以表示为“x 1,y 1,x 2,y 2,x 3,y 3,x 4,y 4”,其中(xi,yi)表示图像中定向边界框顶点的位置。顶点按顺时针顺序排列。以下是采用的注释方法的可视化。黄点代表起点。它指的是:(a)飞机的左上角,(b)大型车辆钻石的左上角,(c)扇形棒球的中心。

链接:https://download.csdn.net/download/qq_40238334/12240956?utm_medium=distribute.pc_relevant.none-task-download-BlogCommendFromMachineLearnPai2-2.pc_relevant_is_cache&depth_1-utm_source=distribute.pc_relevant.none-task-download-BlogCommendFromMachineLearnPai2-2.pc_relevant_is_cache
10. DIOR
“DIOR”是一个用于光学遥感图像目标检测的大规模基准数据集。数据集包含23463个图像和192472个实例,涵盖20个对象类。这20个对象类是飞机、机场、棒球场、篮球场、桥梁、烟囱、水坝、高速公路服务区、高速公路收费站、港口、高尔夫球场、地面田径场、天桥、船舶、体育场、储罐、网球场、火车站、车辆和风磨。
链接:http://www.escience.cn/people/gongcheng/DIOR.html
11.LEVIR
LEVIR数据集由大量 800 × 600 像素和0.2m〜1.0m /像素的高分辨率Google Earth图像和超过22k的图像组成。LEVIR数据集涵盖了人类居住环境的大多数类型地面特征,例如城市,乡村,山区和海洋。数据集中未考虑冰川,沙漠和戈壁等极端陆地环境。数据集中有3种目标类型:飞机,轮船(包括近海轮船和向海轮船)和油罐。所有图像总共标记了11k个独立边界框,包括4,724架飞机,3,025艘船和3,279个油罐。每个图像的平均目标数量为0.5。
链接:http://levir.buaa.edu.cn/Code.htm
12. NWPU VHR-10
西北工业大学标注的航天遥感目标检测数据集,共有800张图像,其中包含目标的650张,背景图像150张,目标包括:飞机、舰船、油罐、棒球场、网球场、篮球场、田径场、港口、桥梁、车辆10个类别。开放下载,大概73M.
链接:https://pan.baidu.com/s/1hqwzXeG#list/path=/
13. INRIA aerial image dataset
Inria是法国国家信息与自动化研究所简称,该机构拥有大量数据库,其中此数据库是一个城市建筑物检测的数据库,标记只有building, not building两种,且是像素级别,用于语义分割。训练集和数据集采集自不同的城市遥感图像。
链接:https://project.inria.fr/aerialimagelabeling/
14. 悉尼城市建筑
这个数据集包含用Velodyne HDL-64E LIDAR扫描的各种常见城市道路对象,收集于澳大利亚悉尼CBD。含有631个单独的扫描物体,包括车辆、行人、广告标志和树木等。可以用来测试匹配和分类算法。
Sydney Urban Objects Dataset 下面是数据格式: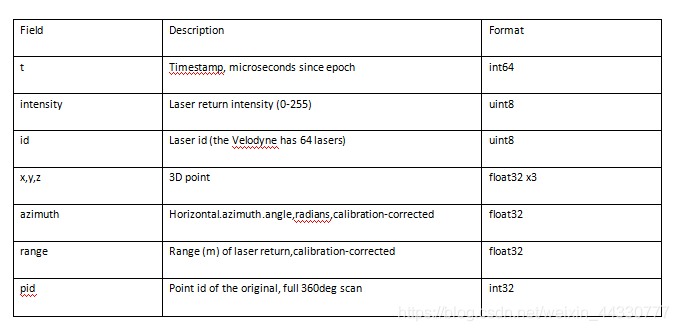
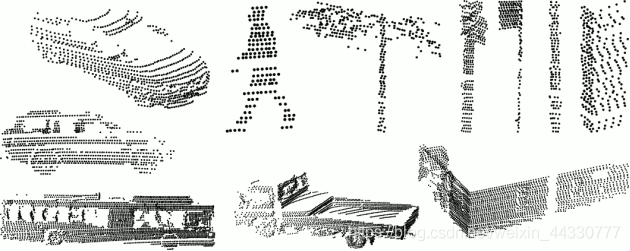
链接:http://www.acfr.usyd.edu.au/papers/SydneyUrbanObjectsDataset.shtml
15. isprs点云数据
ISPRS官方提供了航空、无人机、倾斜影像数据进行密集匹配和三维重建,以下给出相应的数据获取地址。
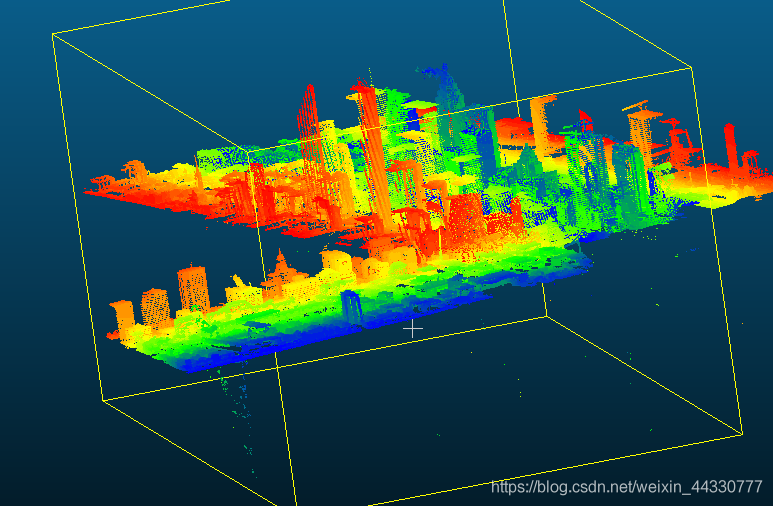
航空数据
一共提供了两组航空实验数据,一组是高楼林立的加拿大Toronto地区,另一组是半农村地区的德国Vaihingen地区。两组数据的航向重叠度为60%,旁向重叠度为30%。
链接:https://www2.isprs.org/commissions/comm2/wg4/benchmark/detection-and-reconstruction/
无人机数据
链接:https://www2.isprs.org/commissions/comm1/icwg-1-2/benchmark_main/
倾斜数据
链接:https://www2.isprs.org/commissions/comm1/icwg-1-2/benchmark_main/
16. 中科院自动化所数据集
国内的中科院自动化研究所提供了多组近景三维重建的数据集。


链接:http://vision.ia.ac.cn/zh/data/index.html
17. ILSVRC
ImageNet Large Scale Visual Recognition Challenge
链接:https://image-net.org/challenges/LSVRC/2014/
18. ImageNet
ImageNet相关信息如下:
1)Total number of non-empty synsets: 21841
2)Total number of images: 14,197,122
3)Number of images with bounding box annotations: 1,034,908
4)Number of synsets with SIFT features: 1000
5)Number of images with SIFT features: 1.2 million
链接:https://image-net.org/download
19. SUN database
131067 Images 908 Scene categories 313884 Segmented objects 4479 Object categories
有10,000张RGB-D图片,有58,657个3D包围框和146,617 个2d包围框,是NYU Depth V2 dataset的超集,多了3D bounding boxes和room layouts的标注。

链接:http://sun.cs.princeton.edu/
20. SUN-RGBD数据集
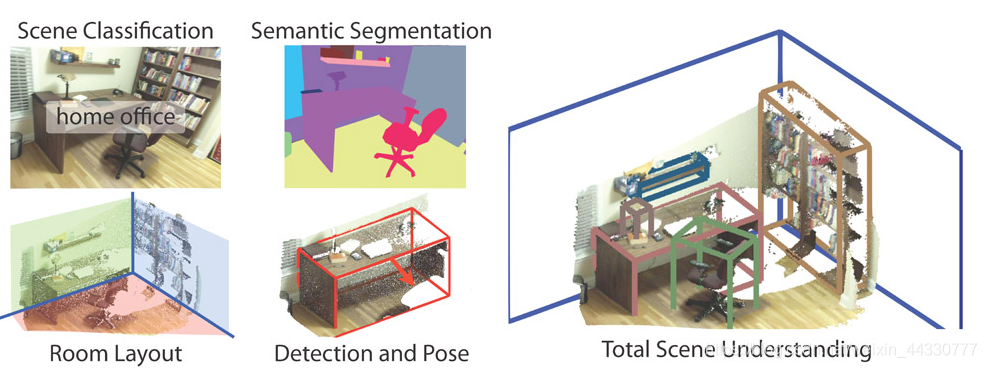
SUN-RGBD数据集由四种不同的传感器获取,分别为kinect1,kinect2,xction,
SUNRGBD V1包含10335张RGBD图片,19个类的对象。这些图片来自数据集NYU depth v2(既NYUDv2),B3DO,SUN3D,使用SUNRGBD此数据集的时候不要忘了引用其包含的数据集的相关论文文献。
链接:http://rgbd.cs.princeton.edu/
21. ModelNet
ModelNet总共有662中目标分类,127915个CAD,以及十类标记过方向朝向的数据。
其中包含了三个子集:
ModelNet10为十个标记朝向的子集数据; ModelNet40为40个类别的三维模型; Aligned40:40类标记的三维模型;
数据格式:.OFF
数据特点:结构简单,不适合做点云数据集,模型结构更多通过边来体现
链接:http://modelnet.cs.princeton.edu/
22. NYU Depth V2 dataset
关于RGBD 图像场景理解的数据库
提供1449张深度图片和他们的密集2d点类标注
链接:https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
23. DTU dataset
关于3D场景的数据集,有124个场景,每场景有49/64个位置的RGB图像和结构光标注
链接:http://roboimagedata.compute.dtu.dk/?page_id=36
24. 普林斯度视觉和机器人实验室数据集

这一实验室提供17个三维视觉的数据集,除了上面提到的ShapeNet和SUN3D外,还有:
SUN RGB-D数据集,包含了室内场景分类、语义分割、房间布置和物体朝向等标注,其中有 10,000 张RGB-D 图像, 标注包含 146,617 2D 个多边形和 58,657 3D 个框。
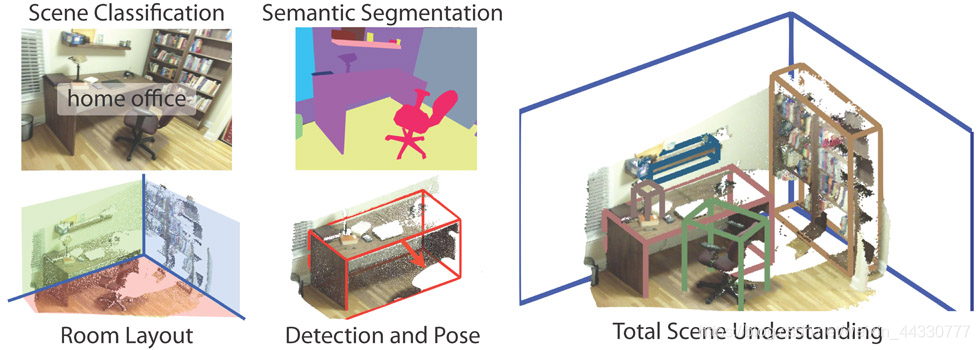
SUN GC数据集包含了45k个手工创造的三维室内场景,包含了深度信息和每个物体的语义标签。

此外还有Matterport3D室内rgbd数据集
这是一个大型RGB-D数据集,包含来自90个建筑规模场景的194,400个RGB-D图像的10,800个全景。批注提供了表面重建,相机姿势以及2D和3D语义分割。整个建筑物的精确全局对齐和全面,多样的全景视图集可实现各种有监督和自我监督的计算机视觉任务,包括关键点匹配,视图重叠预测,根据颜色进行的正常预测,语义分割和场景分类。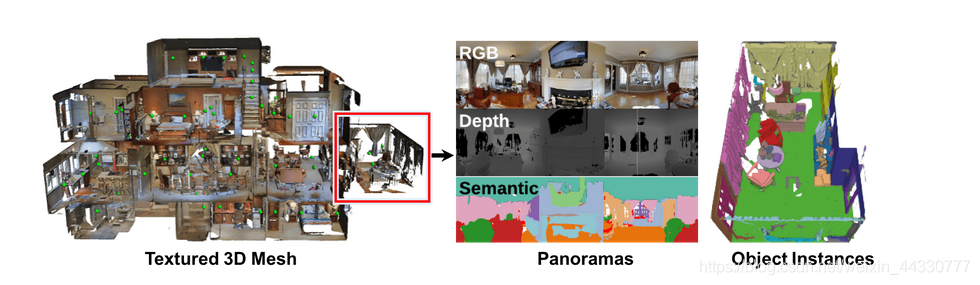
链接:https://niessner.github.io/Matterport/
链接:http://3dvision.princeton.edu/datasets.html
END
整理不易,点赞鼓励一下吧↓