
TDSQL-A自研列存储及优化原理大揭秘
在“国产数据库硬核技术沙龙-TDSQL-A技术揭秘”系列分享中,5位腾讯云技术大咖分别从整体技术架构、列式存储及相关执行优化、集群数据交互总线、Fragment执行框架/查询分片策略/子查询框架以及向量化执行引擎等多个方面对TDSQL-A进行了深入解读。错过直播的小伙伴有福啦,今天带来本次系列分享中腾讯云数据库高级工程师伍鑫老师主题为“TDSQL-A列存储设计原理及执行优化详解”的文字版。
TDSQL-A是腾讯首款分布式分析型数据库,采用全并行无共享架构,适应于海量OLAP关联分析查询场景,能够支持2000台物理服务器以上的集群规模,存储容量能达到单数据库实例百P级。其中,TDSQL-A还具有自研列式存储引擎,能支持行列混合存储,对分析模型下的查询语句性能做到了极致优化。
在开始之前,我们先来了解下TDSQL-A的整体架构,它分为这几个模块:
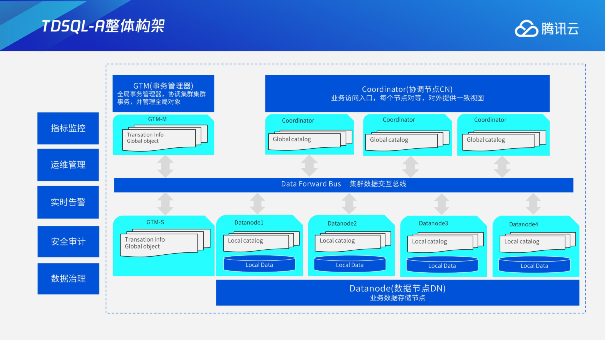
第一是上层的GTM事务管理器,它主要是负责全局事务的管理,协调机群的事务,同时管理集群的全体对象。右上角是协调节点,它是业务访问入口。协调节点模块是水平对等的,也就是说业务连接到任何一个协调节点上,都能够获得到一致的数据库视图。
第二是下方的数据节点。数据节点也是实际存储数据的节点,每个数据节点只会存储数据的分片,而数据节点之间加在一起会形成一个完整的数据视图。
而数据节点和协调节点之间是集群的数据交互总线。集群交互总线的目的是把集群内部节点连接在一起,从而完成整个查询交互。
最后,左侧描述的是数据库内核的运维管控系统。通过运维管理、实时监控、实时告警、安全审计和数据治理等功能,可以进行自动化的运维,减少运维人员和用户使用的成本。
我们今天主要分享两个方面,一个是TDSQL-A自研列存储,另外一个是基于自研列存储的优化器相关优化。现在先来看看TDSQL-A的自研列存储。
说到列存储,相信大家都比较熟悉。列存储对具体的查询模型或者访问模型本身是有特殊优化的。传统情况下,数据库更多的是偏向事务型的场景,在每次数据写入的时候,都会把整行写到存储上面,一次磁盘IO可以访问所有列。这种场景在面对互联网这种大数据量分析的情况下,可能有些列在计算的时候并不需要访问,这会带来IO访问上的瓶颈,同时在后续优化上,也不方便针对特定的计算场景去进行优化。因此列存储也就应运而生了。
每列单独存储,多个列逻辑组成一行,一次磁盘IO只包含一列数据,这一列的数据可能是一行中的一列,或者是执行中的一个数据,同时在这种编排格式下,更方便去做数据压缩,因为相同列的数据类型有更高的一致性和匹配度,所以可能会面向很多极致的压缩的场景,也更适合OLAP的计算场景。

TDSQL-A同时支持行存储和列存储建表,行表和列表之间可以进行互相操作,行列表之间支持混合查询,根据用户的场景去设定不同的行表和列表的定义方式,同时在混合查询的时候也严格保证事务一致性,从而让客户可以比较放心地去定义自己的行表和列表。
2.1 TDSQL-A自研列存储整体设计
这部分主要是介绍我们针对列存储所做的优化。TDSQL-A在设计列存储之前就已经去充分调研过客户相关的需求,下面这张图就把我们的整个能力完整地呈现了出来。
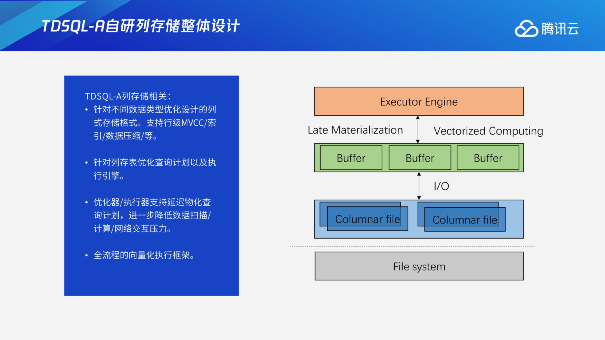
通过比较好的列存储格式的文件编排,可以达到更好的插入或者读取的性能。上层通过Buffer进行高速的加速,以及延迟物化以及向量化执行,对整个引擎做到了针对性的极致优化;通过完整的设计,可以比较好的去优化查询计划以及执行引擎,从而达到一个比较好的执行效果。
2.2 TDSQL-A列存储模型介绍
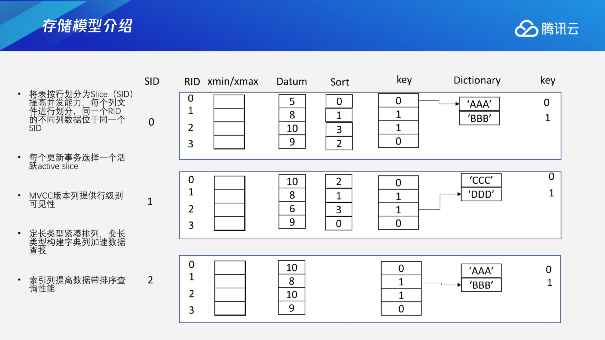
TDSQL-A中列存储首先会分为多个Slice文件,不同的文件可以分配不同的并发访问的数据变更请求,每一个Slice文件标号为SID,SID里面会包含多个Row的信息,每一个列会有一个单独的自己的文件存储,我们可以通过RID来去寻找对应不同行的列的数据。我们可以简单理解为SID和RID是一个标识,通过它们可以去支持索引查询或者后面讲到的延迟物化里面通过ID扫描到相应的数据来进行一个补缺。
我们在存储格式上还设计了版本列,即通过xmin、xmax的相关记录来去支持事务的判断。针对不同类型的数据,我们又有一些相应的优化机制,定长类型紧凑排列,变长类型构建字典列,来加速数据查找。
同时针对一些排序相关的查询,我们在存储上面也进行了优化。比如说由索引列来进行高效的排序,或者是xmin、xmax相关的计算加速或优化,从而在存储层面提供支持。
2.3 TDSQL-A基于自研列存储的三大优势
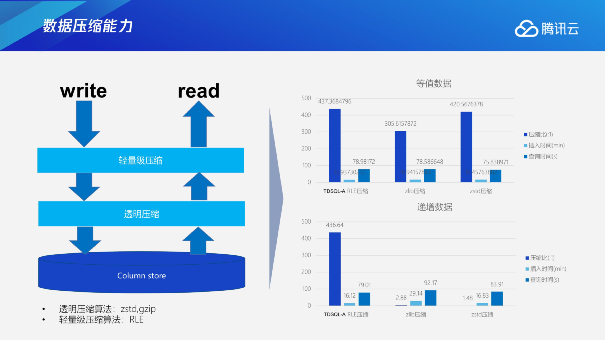
针对一些有特定特征的场景, TDSQL-A可以用轻量级压缩算法来做一个更高效的压缩,对于通用的一些场景,通过透明压缩算法也可以达到一个比较好的整体压缩效果。在例图里可以看到,根据等值数据、递增数据可能会达到上百倍的压缩效果。
高效计算能力也是TDSQL-A的一大特性。实际上我们设计了比较丰富的功能来支持TDSQL-A的计算优化,主要分为这几个方向:
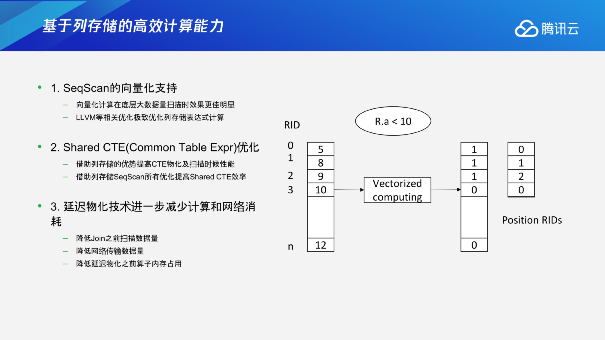
第一点是SeqScan的向量化支持。在底层扫描数据的时候,实际数据量越大,向量化带来的效果和优化的空间也是越大,向量化对上层的复杂计算提供了支持;
第二点是Shared CTE。简单来说,之前的版本可能需要把数据拉到CN做,在TDSQL-A中,我们也做了相应的支持,可以分布式的在DN上去计算CTE。Shared CTE算子会在计算时把数据进行物化。我们在Shared CTE物化时针对性地去借鉴了列存的数据格式编排,包括上面的提到的向量化的计算,以及其他的一些优化,可以更好地借助列存版本在设计上的优势,或者计算上的优势来去提高整个场景的计算性能;
第三点是延迟物化进一步减少计算和网络消耗。我们会针对列存做更多的极致优化来提升查询性能,提供更大规模数据上的实时查询效果。
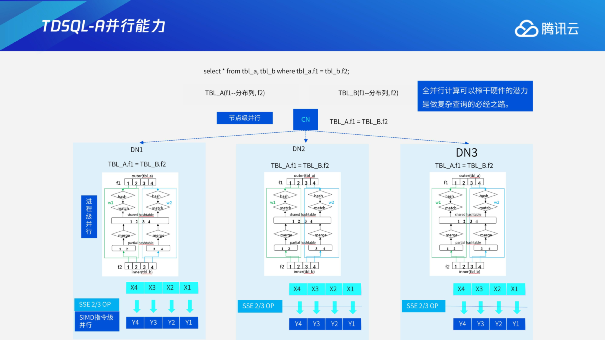
TDSQL-A的并行能力,实际上分为节点级并行、进程级并行以及指令级并行,进程级并行后面我会介绍一下具体优化性里面怎么去进行一个优化,针对并行、延迟物化去进行一个统一的规划。
上一部分介绍了很多列存储以及相关的查询优化方法,这部分我们主要去详细展开延迟物化相关的介绍。
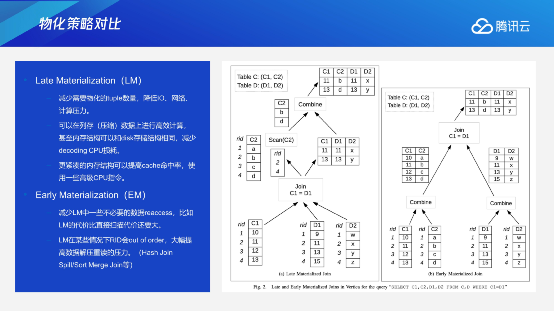
我们讲延迟物化,但实际上并不是所有的延迟物化都快,我们需要去寻找最优的策略和方案,为客户自动调整到去用延迟物化还是提前物化。下面先介绍两种物化策略的区别。
3.1 提前物化 VS延迟物化
简单的场景的时候,采用提前物化,提前把C1、C2或者D1、D2列全部都扫描出来,去组装成tuple进行内部计算,这个时候它的好处是数据只访问一次。但如果join的选择率比较低的话,我们就会浪费掉很多早期的网络交互。如果采用延迟物化,且join的选择率非常低,C2列我可以进行一个延迟物化,在join结束之后我才去把它的数据进行一个补全,这种情况下我可能减少了很多不必要的扫描和网络交互。
但是对于这两种场景,join的选择率以及整个不同列的宽度或者数据列在重新扫描时遇到乱序等场景,都会影响到我们选择不同策略的规划,并非简单的一定会选择延迟物化或者选择提前物化。
这里面延迟物化会减少物化的tuple数量,降低IO、网络、计算压力;同时在基于列存储的访问上,可以借助计算上面的增强技术来去降低CPU的消耗;延迟物化还有一个好处就是在扫描数据相对较少的情况下,需要cache的数据量是更少的,像这时候也会变相地提高整个计算的cache命中率,减少cpu的消耗。
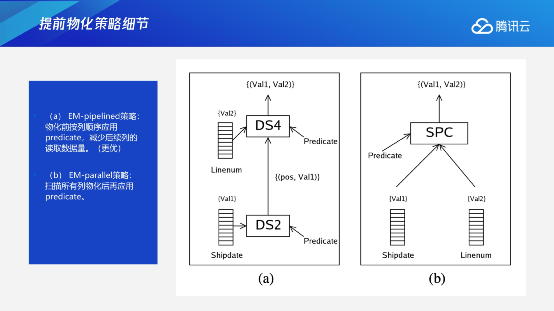
提前物化的好处是减少LM中不必要的数据reaccess(需要频繁的多次访问相同的数据块从而导致更高的访问)。所以提前物化在选择率比较高的时候,或者本身join中间会有数据乱序的情况下,可能提前物化的效果会更好。提前物化里面还有更细致的结构化。有两种方式,一种是先对A列进行prediate计算,这时候它可能已经过滤了很多数据,再去进行第二列的prediate计算。但这种情况下,只能对列存储来去做相应的优化;相应地就是右边这种在早期扫的时候不管Predicate,先去把A、B两列扫描出来,然后再去进行Predicate,这样扫描的数据量还是会比较多,这个也是一个细致的优化,可以通过这样的方式去减少更多的列存储的数据扫描量。
3.2 不同场景应用不同物化策略
这里我们介绍下TDSQL-A优化器是如何针对不同场景对物化策略进行选择。
比较早期的数据库或者是九十年代以前更多的是选择一个Rule-based Optimizer(RBO)。简单讲就是通过静态的规则去对逻辑查询计划进行优化,像提前下推,都是通过强制的规则去进行计算的。这里的好处就是我可以比较简单地实现,或在早期理论比较简单的情况下,通过这样的方式来达到比较好的呈现效果。但是它在面对更复杂的查询、算子、优化等这些场景时,可能中间会有互斥,或者很难去进行最终的优化。这种情况下Cost Based Optimizer就应运而生,后面会整体介绍通过整个不同paths的代价评估来进行整体的估算,实际上像比较新的或者现在的数据库整合都会互相去达到比较好的优势的借鉴。

我们在join Reordering的时候,到底是怎么基于cost来进行推算的呢?举个例子,比如说我们有三张表,在join优化器里面它会选择动态规划的一个算法,最开始会把同一个jointree所有join参与的表打散成base relation,这个时候基于base relation去进行不同层级的计算。第一层我们就会选择这三张表其中两张表来做一个计算,生成相应的一个path,这条红线就是生成某一个level的查询方法的一个路径,对于每个path会有相应的代价叫cost。第二层基于刚才第一层生成表的选择情况,再去补全第三张表,这种情况下相对于是一个动态规划,中间的一个转移函数主要是通过不同path中间去选择一个Cheapest cost,通过这种方式来完成整个查询计划的便利,选择出代价最低的计划,这里面是一个简单铺垫。
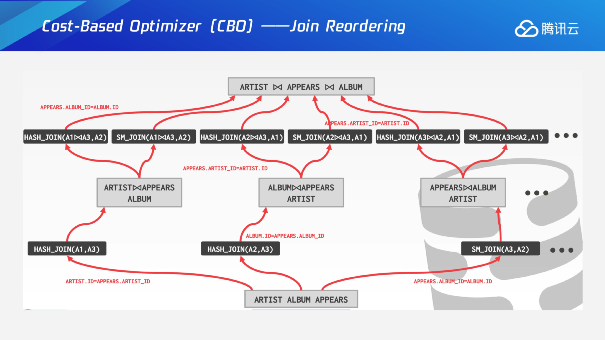
考虑到并行的情况下,这个问题就会变的更复杂一些,同时需要规划一个并行的path,或者是一个非并行的path,在每一个转移函数的时候需要去考虑,在有并行paths的情况下,是否需要在当前这一层把这个并行path加一个gather节点,来变成一个串行的path。实际上串行只能跟串行比,并行的数据还没有整理完毕,这种情况下每一层都会去考虑所有的串行的path里面再去加上gather的并行path,这样整体的cost一对比,然后统一来选择并行还是串行,这也是并行优化里面比较重要的一部分。
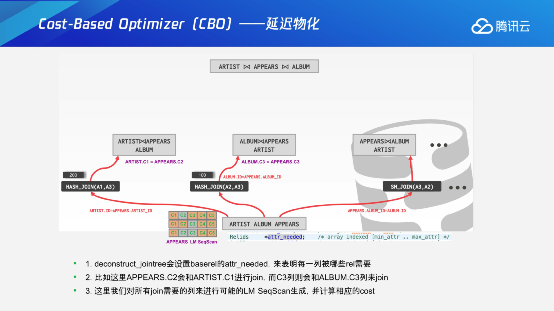
如果再考虑到延迟物化的话,这个问题就会变的更加复杂,就是说我们在拆分成base relation的时候,通过query tree 可以知道join的时候哪些列是不需要的。比如这个表有100列,中间的join可能只用了10列,可以只生成这10列的缺失状态的path,实际上生成对应的path还是可以满足当前第一层场景的。如果我发现join需要第三、第四列需要补全的时候,会在join之前把这两列通过延迟物化算子把它补全进来,这样保证每一层在计算的时候需要的数据是补全进来的。另外在转移函数的时候,也需要去考虑正常的path怎么去跟延迟物化的path进行一个对比,需要去把延迟物化的path补全,将相应的列补全的情况下才能去跟正常的paths进行一个对比。这种情况下是完整的转移函数,这个时候就会比较好的体现出选择一个什么样的paths,最后生成物理的相应计划。

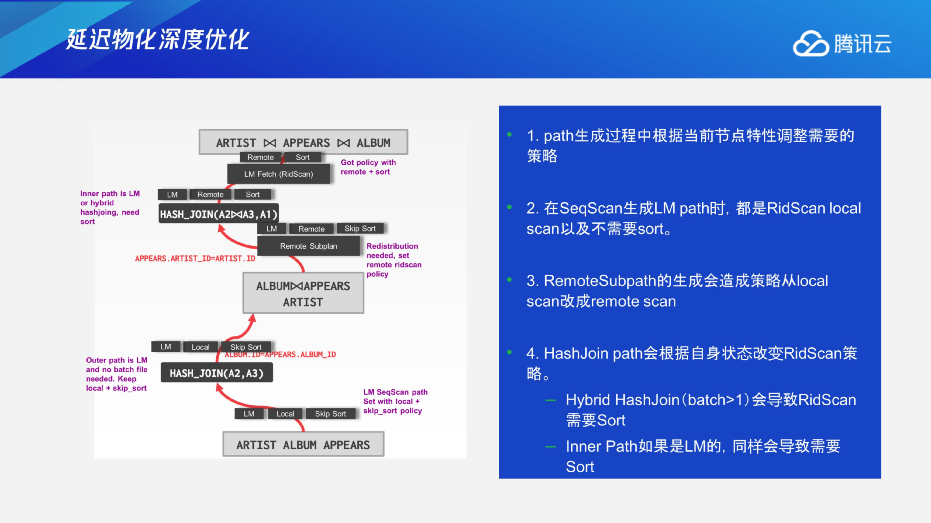
实际上的应用场景会更加复杂,像具体的SeqScan Cost的计算,怎么考虑到延迟物化来做一个调整呢?实际上,宽度是有动态的调整,根据不同的情况去进行一个计算。像RidScan Cost在去进行一个列的补全的时候,需要根据这个列之前传给我的RID,基于具体计划的情况去进行考虑。这种情况下其实就需要考虑Rid是不是sort的,去扫描的时候,会不会有很多的re-access,这种情况下会导致RidScan Cost比较复杂。第三点拼装的时候LM Fetch需要考虑当前是不是通过Remote Scan,或者本节点的local scan。不同的cost的计算也是不一样的,包括第四点Remote Subpath Cost计算会大量的降低网络带宽的情况,这个要考虑到少扫了80%的列的宽度,实际上对网络层也是有很大影响的,这都是要统一地去计算。
这些都会对整个优化器的决策去进行一个调整,最开始生成base paths的时候,实际上我是不知道我到底需不需要去remote或者需不需要去sort,这个时候都会标成local或者skip sort,另外一点就是在几种情况下可能会导致产生变化,比如说remoteSubpath,因为我收的顺序可能是乱序的,RD已经乱了,后面再去进行RD Stand的时候,通过代价来去评估它是不是可以这样走,或者如果要这样走,我是不是要在物理算子上进行一个排序,以及Hashjoin的时候都会有相应的一些影响。比如说最简单的ARTIST外表应该是顺序,但是它有join的时候,读上来顺序也是乱的。像Inner Path更是如此,Hash table 实际上会对整个顺序进行改变,这些都会对延迟物化有很深层的影响,导致优化器里面会有不同的决策、选择。
3.3 延迟物化推动通信效率提升
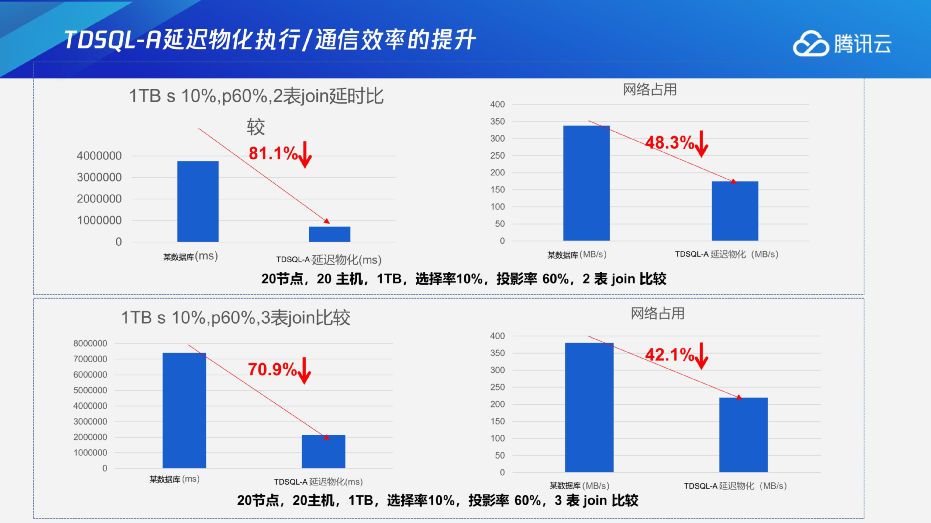
通过这些比较严谨的思考和优化器的调整,我们更多的参数回归和调整,我们也达到了比较好的效果。比如说,1TB的数据如果了选择率相对比较低,10%的情况下P60%,2表JOIN可能会有一个时间上81.1%的提升,消耗时间的下降以及网络占用带宽的下降;如果是多表的话,会有更好的一个效果。
- End -
更多精彩

↓↓神秘惊喜点这儿