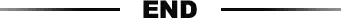什么是列存储,特点及场景在哪?

01、概述
02、什么是列存储?
03、在数据写入上的对比
04、在数据读取上的对比
06、优缺点
07、列存储的适用场景
08、最后总结如下
01、概述
02、什么是列存储?
列式存储(column-based)是相对于传统关系型数据库的行式存储(Row-basedstorage)来说的。简单来说两者的区别就是如何组织表:
Ø Row-based storage storesatable in a sequence of rows.
03、在数据写入上的对比
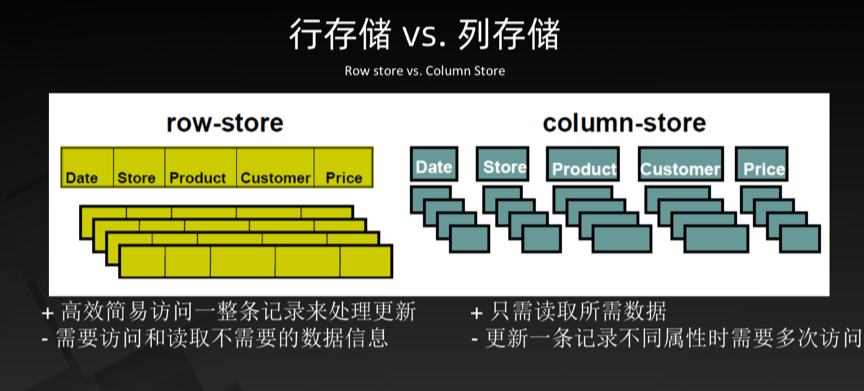
1)行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。
2)列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多(意味着磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms) ,再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
3)还有数据修改,这实际也是一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。
04、在数据读取上的对比
1)数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。
2)列存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
3) 两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。
4)从数据的压缩以及更性能的读取来对比
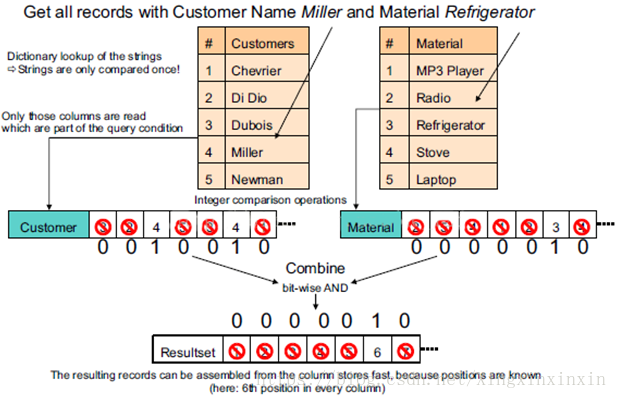
06、优缺点
显而易见,两种存储格式都有各自的优缺点:
1)行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。
2)列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
两种存储格式各自的特性都决定了它们的使用场景。
07、列存储的适用场景
1)一般来说,一个OLAP类型的查询可能需要访问几百万甚至几十亿个数据行,且该查询往往只关心少数几个数据列。例如,查询今年销量最高的前20个商品,这个查询只关心三个数据列:时间(date)、商品(item)以及销售量(sales amount)。商品的其他数据列,例如商品URL、商品描述、商品所属店铺,等等,对这个查询都是没有意义的。
而列式数据库只需要读取存储着“时间、商品、销量”的数据列,而行式数据库需要读取所有的数据列。因此,列式数据库大大地提高了OLAP大数据量查询的效率
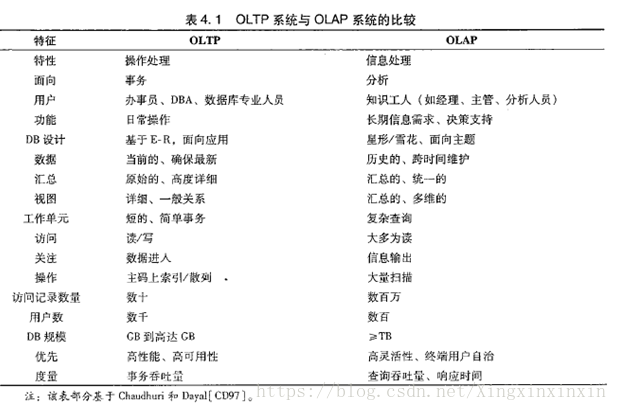
OLTP OnLine TransactionProcessor 在线联机事务处理系统(比如Mysql,Oracle等产品)
OLAP OnLine AnalaysierProcessor 在线联机分析处理系统(比如Hive Hbase等)
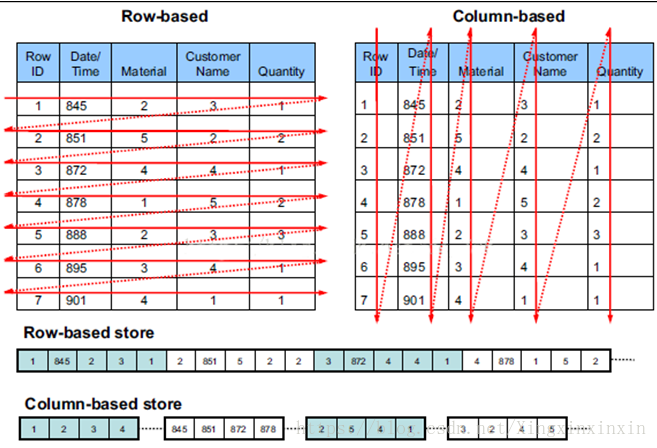
2)很多列式数据库还支持列族(column group,Bigtable系统中称为locality group),即将多个经常一起访问的数据列的各个值存放在一起。如果读取的数据列属于相同的列族,列式数据库可以从相同的地方一次性读取多个数据列的值,避免了多个数据列的合并。列族是一种行列混合存储模式,这种模式能够同时满足OLTP和OLAP的查询需求。
3)此外,由于同一个数据列的数据重复度很高,因此,列式数据库压缩时有很大的优势。
例如,Google Bigtable列式数据库对网页库压缩可以达到15倍以上的压缩率。另外,可以针对列式存储做专门的索引优化。比如,性别列只有两个值,“男”和“女”,可以对这一列建立位图索引:
如下图所示
“男”对应的位图为100101,表示第1、4、6行值为“男”
“女”对应的位图为011010,表示第2、3、5行值为“女”
如果需要查找男性或者女性的个数,只需要统计相应的位图中1出现的次数即可。另外,建立位图索引后0和1的重复度高,可以采用专门的编码方式对其进行压缩。
当然,如果每次查询涉及的数据量较小或者大部分查询都需要整行的数据,列式数据库并不适用。
08、最后总结如下
①数据是按行存储的。
②没有索引的查询使用大量I/O。比如一般的数据库表都会建立索引,通过索引加快查询效率。
③建立索引和物化视图需要花费大量的时间和资源。
④面对查询需求,数据库必须被大量膨胀才能满足需求。
列式数据库的特性如下:
①数据按列存储,即每一列单独存放。
②数据即索引。
③只访问查询涉及的列,可以大量降低系统I/O。
④每一列由一个线程来处理,即查询的并发处理性能高。
⑤数据类型一致,数据特征相似,可以高效压缩。比如有增量压缩、前缀压缩算法都是基于列存储的类型定制的,所以可以大幅度提高压缩比,有利于存储和网络输出数据带宽的消耗。
文章来源:
blog.csdn.nept/Xingxinxinxin/article/details/80939277