
近期必读的六篇 EMNLP 2020【知识图谱】相关论文和代码

新智元报道
新智元报道
来源:专知
编辑:SF
【新智元导读】六篇论文涵盖知识图谱表示、常识、任务型对话、多语种知识库补全、开放式KG表示、社会常识推理等。
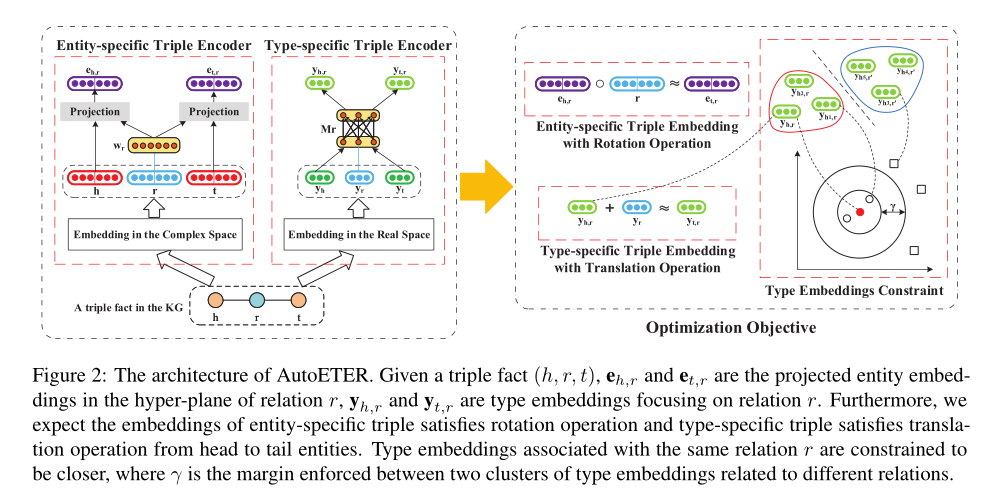
1. AutoETER: Automated Entity Type Representation for Knowledge Graph Embedding
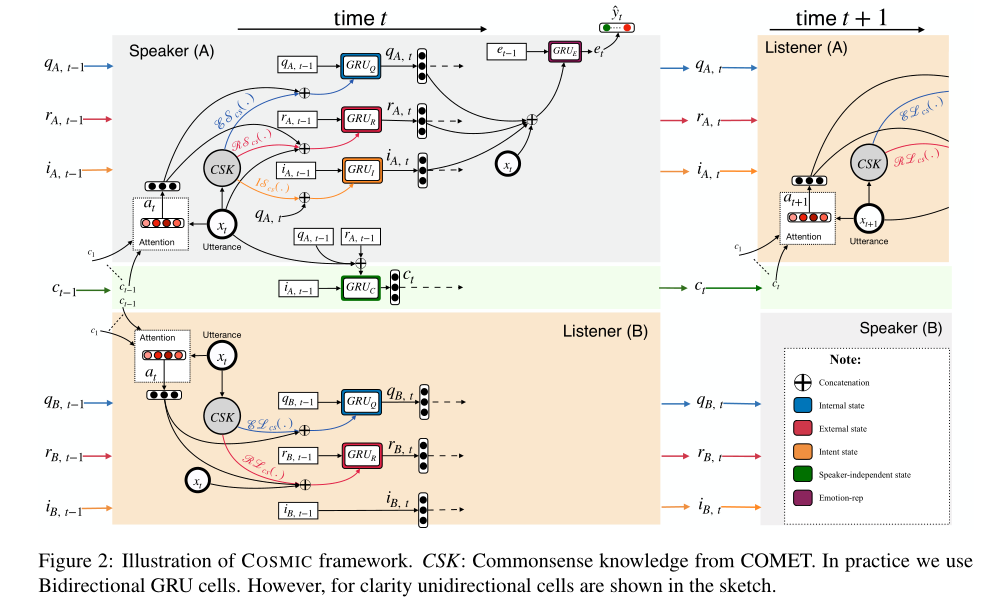
2. COSMIC: COmmonSense knowledge for eMotion Identification in Conversations
3. Learning Knowledge Bases with Parameters for Task-Oriented Dialogue Systems

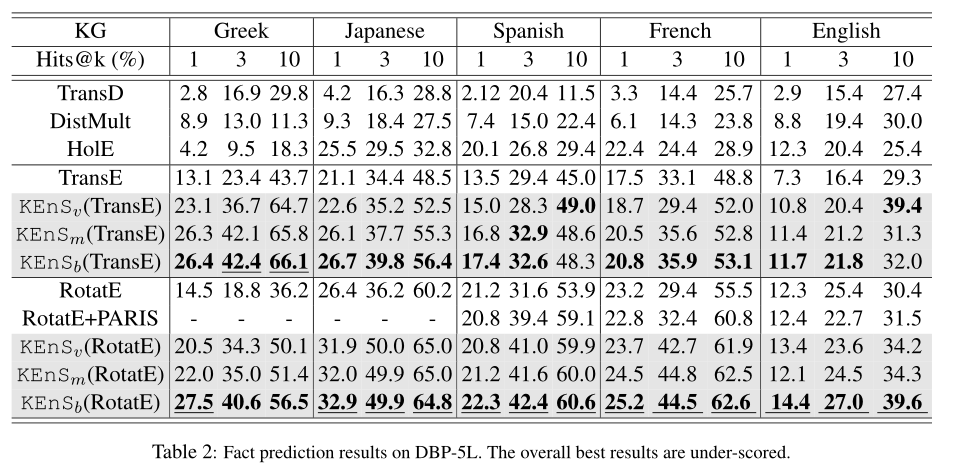
5. Out-of-Sample Representation Learning for Knowledge Graphs

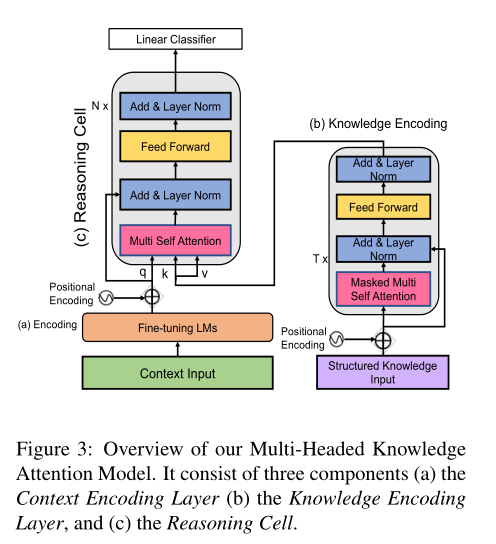
6. Social Commonsense Reasoning with Multi-Head Knowledge Attention


评论