
Python爬取自如北京2.3万条租房信息,发现快租不起房子了
回复“书籍”即可获赠Python从入门到进阶共10本电子书
努力不是为了租房子,是为了有房子!希望大家都能有属于自己的房子~
06
1.概述
2.数据采集-爬虫
2.1.房屋信息解析
2.2.房屋价格解析
3.数据处理-清洗
3.1.房屋名称数据清洗
3.2.房间信息数据清洗
3.3.位置信息数据清洗
3.4.选取需要用于分析的字段
4.房源相关数据统计与可视化
4.1.房源分布(map)
4.2.各地区房源数
4.3.各区房源数占比
4.4.租房类型分布
4.5.地铁站附近房源数据
4.6.租金前10名地铁站圈
4.7.各区合租类平均租金箱线图
4.8.各区整租类平均租金箱线图
5.房间相关数据统计与可视化
5.1.合租类房间大小直方图
5.2.整租类房间大小直方图
5.3.合租类房间租金直方图
5.4.整租类房间租金直方图
5.5.房源距离地铁站距离直方图
5.6.平米租金与距离地铁站距离回归图
5.7.各区卧室朝向与平米租金热力图
5.8.户型分布
1.概述
北上广深作为打工人最多的超一线城市,大部分都是租房生活着。自如作为目前第三方租房平台,应该算是该行业的龙头。但是最近蛋壳的暴雷,我们不得不更加警觉。那么自如都有多少open状态的房源呢,这些房源都是什么样的呢?这里我们爬取了自如北上广深四个城市共4.6万房源信息,单拿北京的数据来做详细介绍吧!
自如北京合租房源分布
2.数据采集-爬虫
自如的租房信息每个筛选结果最多展示50页,约1500个左右。考虑到很多地区的租房数量超过1500个,我们可以通过增加筛选的方式进行遍历获取全部租房信息。
以北京为例,由于自如大本营在北京,我们发现北京有租房信息2.3万条以上,因此这里采用的是地区-房价区间 2个筛选项进行选择,其中筛选项为自定义以500为颗粒度。
在爬虫过程中,我们会发现频繁的请求数据会被封IP,同时自如的租房价格信息是图片位置决定的,需要进行特殊的处理。
自如爬虫注意事项:
①需要采用IP代理,避免封IP后无法请求数据
②需要识别图片中数字及定位,从而获取具体的租金数据
由于爬虫部分的处理其实比较麻烦,考虑篇幅有限,这里仅做核心部分讲解,我们在后续再做专题介绍。
2.1.房屋信息解析
打开自如官网,F12到开发者模式,直接查看网页源码即可找到需要的房屋信息数据。本次我是采用的re正则表达式进行数据解析,当然大家也可以通过别的方式比如xpah或bs4等等进行解析。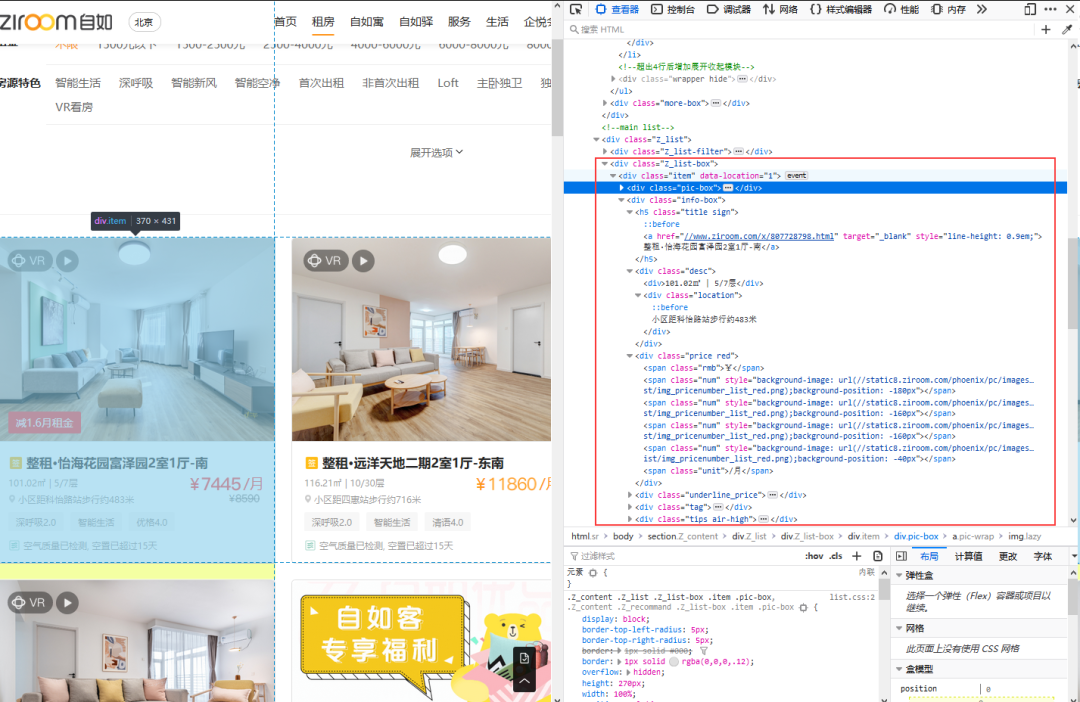
# 获取具体房屋信息
houseId = re.findall('x/(.*?).html"target="_blank">', item)[0]
title = re.findall('target="_blank">(.*?)',item)[0] # 房屋信息 朝向-小区-户型-卧次
large = re.findall('(.*?)', item)[0] # 房屋 面积-楼层
location = re.findall('(.*?) 2.2.房屋价格解析
对于刚才这个截图里7445元租金信息其实不是直接用的数字展示,而是有一个backgroundHtml和background-position决定。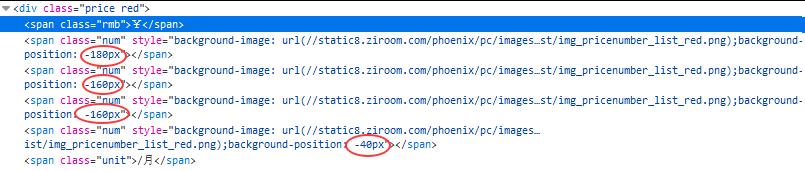 我们打开backgroundHtml链接发现是一个含10个个位数数字的透明png图如下:
我们打开backgroundHtml链接发现是一个含10个个位数数字的透明png图如下: 而价格里出现的四个 -188px、-160px、-160px和-40px对应上面的数字位置,通过关系我们可以匹配到。
而价格里出现的四个 -188px、-160px、-160px和-40px对应上面的数字位置,通过关系我们可以匹配到。
backgroundHtml = re.findall('url\((.*?)\)', item)
priceList = re.findall('background-position:(.*?)px">', item)# 房价数字图片地址
image = requests.get('http:' + backgroundHtml[0]).content
# 保存价格用图片到本地
f = open('.\price.png', 'wb')
f.write(image)
f.close()
# 调用函数(见下面函数定义)获取价格数字字符串
text = get_pricetext()
# 获取价格
price = ''
for i in priceList:
num = int(float(i) / -20) #对于不同情况中有折扣的是20,无折扣的是21.4
price = price + text[num]如何获取价格用图片中的数字及顺序呢,需要用到pytesseract进行图片数字识别,以及用Image给原始透明图片加白底。
# 由于数字图是png无法被识别,所以我们需要进行背景加白
def get_pricetext():
# 给透明图片加白色背景
im = Image.open('.\price.png')
x,y = im.size
try:
p = Image.new('RGBA', im.size, (255,255,255))
p.paste(im, (0, 0, x, y), im)
p.save('.\price.png')
except:
pass
# 获取图片中数字字符串
text = pytesseract.image_to_string(Image.open(".\price.png"),
config='--psm 10 --oem 3 -c tessedit_char_whitelist=1234567890',
lang='eng')
text = re.sub('\s','',text)
return text
3.数据处理-清洗
在爬取数据的过程中,发现既定的数据解析方式总是出现一些问题,随着对异常数据的查看,发现同一个数据指标下的数据格式并不唯一化,因此需要不断的修正解析方法。
为了更方便爬取原数据,在爬虫过程中采取了较为通用的格式,等数据采集下来之后再进行统一化的清洗处理。以下是采集后的数据预览: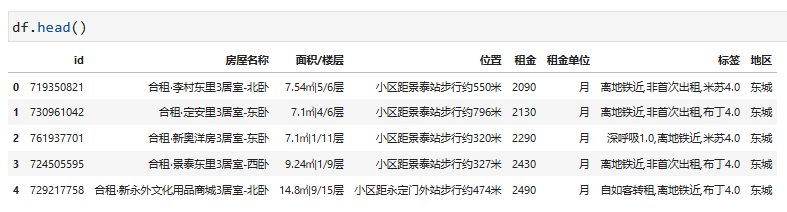 查看以上数据,其实房屋名称、面积/楼层及位置信息可以继续进行细化成更小的元数据供后续分析使用,对此我们来一一处理。
查看以上数据,其实房屋名称、面积/楼层及位置信息可以继续进行细化成更小的元数据供后续分析使用,对此我们来一一处理。
3.1.房屋名称数据清洗
对于我们来说,“合租·李村东里3居室-北卧”其实包含了类型、小区、户型和卧室朝向等信息,需要进行分拆。
# 房屋信息解析
# s = '合租·李村东里3居室-北卧'
# s = '合租·强佑·府学上院4居室-北卧'
# s = '整租·铁二区1室1厅-北'
# s = '整租·厂甸11号院1室1厅-东'
s = '整租·牛街182室1厅-西'
re.split(r'(.*?)·(.*)(\d居*室.*)-(.*)',s)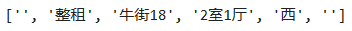 通过以上正则表达式的方式,我们可以采用apply进行处理:
通过以上正则表达式的方式,我们可以采用apply进行处理:
df['类型'] = df['房屋名称'].apply(lambda x : re.split(r'(.*?)·(.*)(\d居*室.*)-(.*)',x)[1])
df['小区'] = df['房屋名称'].apply(lambda x : re.split(r'(.*?)·(.*)(\d居*室.*)-(.*)',x)[2])
df['户型'] = df['房屋名称'].apply(lambda x : re.split(r'(.*?)·(.*)(\d居*室.*)-(.*)',x)[3])
df['卧室朝向'] = df['房屋名称'].apply(lambda x : re.split(r'(.*?)·(.*)(\d居*室.*)-(.*)',x)[4])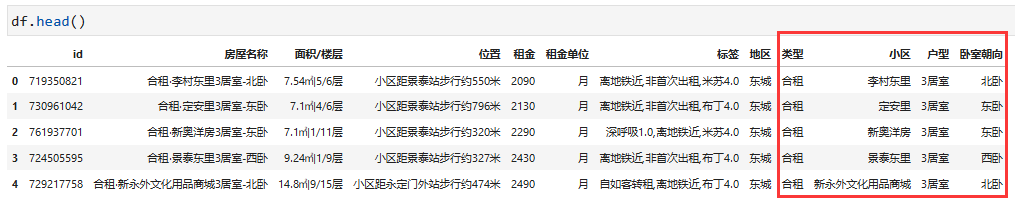
3.2.房间信息数据清洗
我们看到关于房间大小、楼层等信息是在一个字段中,也是需要进行分拆的。
# 房间信息解析
# 我们在数据处理中发现存在异常数据(楼层如 7层 或 -1/5层)
s = '87.26㎡|11/29层'
re.split(r'(.*?)㎡\|(-?\d+)\/?(.*?)层',s)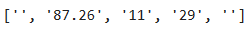 同样采用正则的方式,用apply方法处理:
同样采用正则的方式,用apply方法处理:
df['房间大小'] = df['面积/楼层'].apply(lambda x : re.split(r'(.*?)㎡\|(-?\d+)\/?(.*?)层',x)[1])
df['房间楼层'] = df['面积/楼层'].apply(lambda x : re.split(r'(.*?)㎡\|(-?\d+)\/?(.*?)层',x)[2])
df['房间楼房层数'] = df['面积/楼层'].apply(lambda x : re.split(r'(.*?)㎡\|(-?\d+)\/?(.*?)层',x)[3])
3.3.位置信息数据清洗
在位置信息中记录的是 小区距离地铁站的距离,我们需要的元数据是 地铁站和距离数字,同样也需要进行分拆。
这里需要注意的是,在该列数据中,有部分数据是不含 此类信息的,需要进行特殊处理(这其实就是爬虫过程中解析判断遗留的情况)。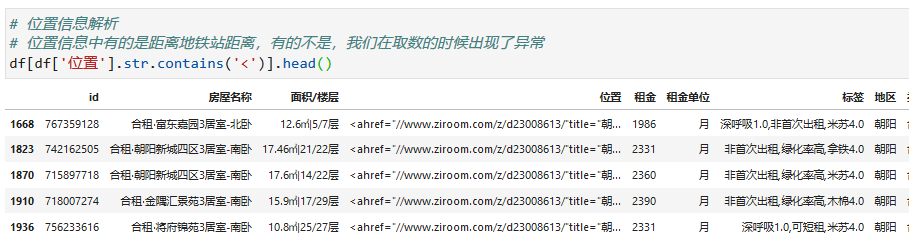 在这里我是用的比较特定的处理逻辑,先取异常数据中的地址信息,然后判断字符长度进行清洗处理。
在这里我是用的比较特定的处理逻辑,先取异常数据中的地址信息,然后判断字符长度进行清洗处理。
# 替换非地铁信息位置
df['位置'] = df['位置'].apply(lambda x: re.sub('<(.*?)>','',x))
# 获取最近地铁站
def getMetro(x):
if len(x) >= 9:
return re.split(r'小区距(.*?)步行约(\d+?)米',x)[1]
else:
return ''
# 获取距离地铁站的距离
def getDistance(x):
if len(x) >= 9:
return re.split(r'小区距(.*?)步行约(\d+?)米',x)[2]
else:
return ''
df['附近地铁站'] = df['位置'].apply(getMetro)
df['距离地铁站距离'] = df['位置'].apply(getDistance) 到这里,基本元数据都已经解析获得。
到这里,基本元数据都已经解析获得。
3.4.选取需要用于分析的字段
原数据经过清洗处理后,有较多字段是我们后续用不上的,这里可以选择需要的字段即可。此外,我们后续需要新增一个字段“price”是指平均每平米每月的租金,在这里简单处理一下即可获得。
data = df[['id', '房屋名称', '租金', '租金单位', '标签', '地区', '类型', '小区', '户型',
'卧室朝向', '房间大小', '房间楼层', '房间楼房层数', '附近地铁站', '距离地铁站距离']]
# 计算 租金 元/月/平米,取小数点后2位
data.loc[data['租金单位']=='月', 'price'] = round(data['租金']/data['房间大小'].astype(float),2)
data.loc[data['租金单位']=='天', 'price'] = round(30*data['租金']/data['房间大小'].astype(float),2)
4.房源相关数据统计与可视化
先简单看看 数据源,一共23,574个房源。 本节我们使用pyecharts进行可视化绘制。
本节我们使用pyecharts进行可视化绘制。
# 引入需要用到的库
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
from pyecharts.charts import *4.1.房源分布(map)
自如北京的房源基本都分布在中心城区及次中心区,像延庆、怀柔、密云和平谷等郊区便没有任何房源数据。
# 统计各地区房源数
beijing = data.groupby('地区',as_index=False)['id'].count().sort_values('id',ascending=False).reset_index(drop=True)
beijing.loc[~beijing['地区'].str.endswith('区'),'地区']=beijing['地区']+'区'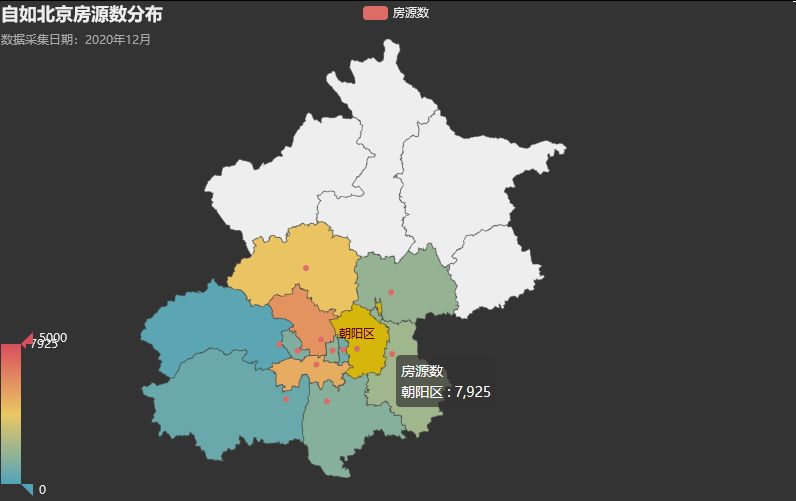
绘图代码:
# 绘制地图(区)
c = (
Map(init_opts=opts.InitOpts(theme='dark', width='800px'))
.add("房源数", [list(z) for z in zip(beijing['地区'].to_list(), beijing['id'].to_list())], "北京", label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="自如北京房源数分布",
subtitle='数据采集日期:2020年12月'),
visualmap_opts=opts.VisualMapOpts(max_=5000)
)
)
# c.render('map_beijing.html')
c.render_notebook()4.2.各地区房源数
自如北京租房房源数最多的朝阳区高达7,925,远超过其他地区。其次是海淀区、丰台区和昌平区,基本都在2000+。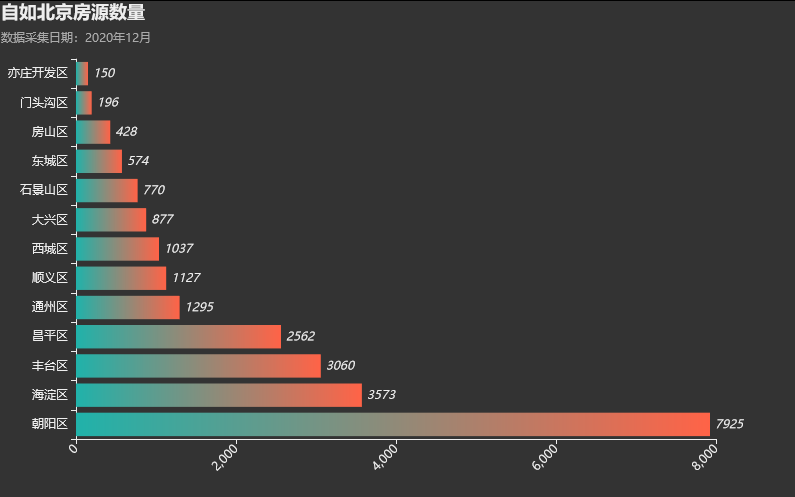 绘图代码:
绘图代码:
# 绘制柱状图
bar = (Bar(init_opts=opts.InitOpts(theme='dark', width='800px'))
.add_xaxis(beijing['地区'].to_list())
.add_yaxis("", beijing['id'].to_list())
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='right',
font_style='italic'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(1, 0, 0, 0,
[{
offset: 0,
color: 'rgb(255,99,71)'
}, {
offset: 1,
color: 'rgb(32,178,170)'
}])"""))
)
.set_global_opts(
title_opts=opts.TitleOpts(title="自如北京房源数量",
subtitle='数据采集日期:2020年12月'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)),
legend_opts=opts.LegendOpts(is_show=True))
.reversal_axis()
)
bar.render_notebook()
4.3.各区房源数占比
朝阳区和海淀区基本是大部分公司聚集地,自如在其的房源数占比也接近自如北京全部的一半!!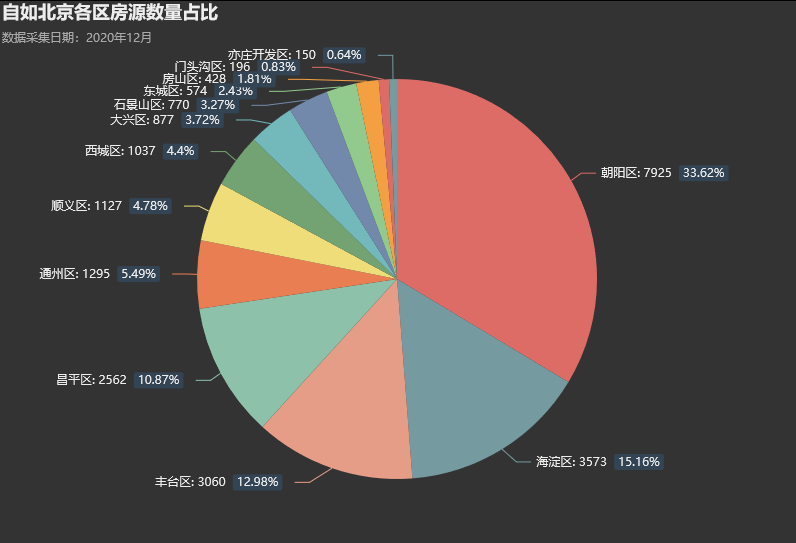 绘图代码:
绘图代码:
# 富文本
rich_text = {
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"b": {"fontSize": 12, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
}
location = beijing['地区'].to_list()
num = beijing['id'].to_list()
pie = (Pie(init_opts=opts.InitOpts(theme='dark', width='800px',
height='560px',
))
.add('房源数', [list(z) for z in zip(location, num)],
radius=200, #设置饼图半径
label_opts=opts.LabelOpts(position='outsiede',
formatter="{b|{b}: }{c} {per|{d}%} ",
rich=rich_text))
.set_global_opts(legend_opts=opts.LegendOpts(is_show=False),
title_opts=opts.TitleOpts(title="自如北京各区房源数量占比",
subtitle='数据采集日期:2020年12月'),)
)
pie.render_notebook()4.4.租房类型分布
自如的租房主要分为三类:合租、整租和豪宅(我这里去掉了自如寓)。不得不说,朝阳的房子真多,而且 豪宅这种只在东城区和朝阳才有!!
# 租房类型分布统计
houseType = data.pivot_table(values='id',index='地区',columns='类型',aggfunc='count').fillna('')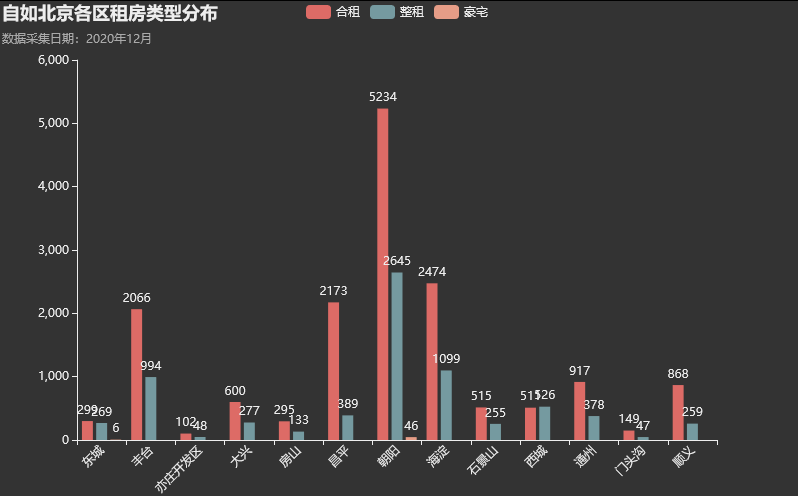 绘图代码:
绘图代码:
# 绘制租房类型分布
bar = (
Bar(init_opts=opts.InitOpts(theme='dark', width='800px'))
.add_xaxis(houseType.index.to_list())
.add_yaxis('合租', houseType['合租'].to_list())
.add_yaxis('整租', houseType['整租'].to_list())
.add_yaxis('豪宅', houseType['豪宅'].to_list())
.set_global_opts(legend_opts=opts.LegendOpts(is_show=True),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)),
title_opts=opts.TitleOpts(title="自如北京各区租房类型分布",
subtitle='数据采集日期:2020年12月'),
)
)
bar.render_notebook()豪宅是啥样的 比如下面这个:
比如下面这个:
!! 海晟名苑(北区)
本月均价:103659元/平米
所在板块:东城 东直门外
总户数:352户
绿化率:50%(绿化率高)
停车位:暂无数据
物业类型:公寓
竣工时间:2015年

4.5.地铁站附近房源数据
对于打工人来说,好的房源是靠近地铁站的,那么那些地铁站附近房源最多呢?
metro = data.groupby(['地区','附近地铁站'],as_index=False)['id'].count().sort_values(['地区','id'],ascending=False).reset_index(drop=True)
metro = metro[metro['附近地铁站']!='']这里我们仅展示 朝阳、海淀、丰台和昌平区:朝阳的十里堡、立水桥南,海淀的永泰庄、农大南路,丰台的角门东,昌平的回龙观东大街、天通苑南站、龙泽、霍营等等都是很热门的。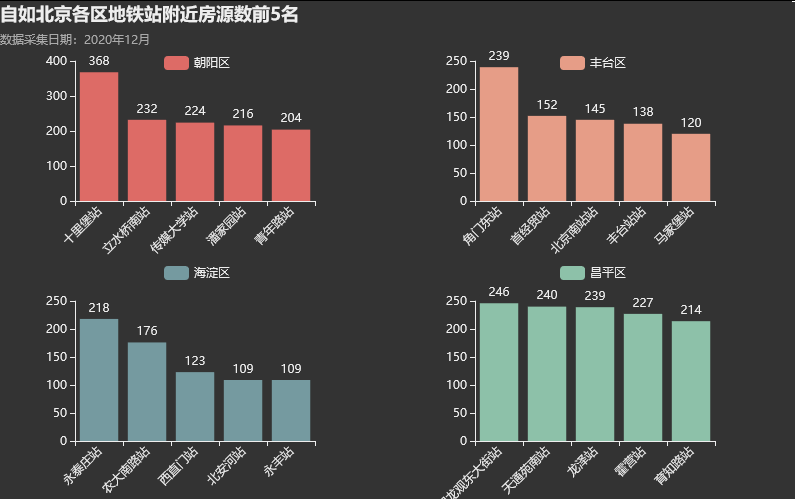 绘图代码:
绘图代码:
# 绘制组合图
bar1 = (Bar()
.add_xaxis(metro[metro['地区']=='朝阳'].head()['附近地铁站'].to_list())
.add_yaxis('朝阳区', metro[metro['地区']=='朝阳'].head()['id'].to_list())
.set_global_opts(legend_opts=opts.LegendOpts(is_show=True, pos_right="70%",pos_top="10%"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)),
title_opts=opts.TitleOpts(title="自如北京各区地铁站附近房源数前5名",
subtitle='数据采集日期:2020年12月'))
)
bar2 = (Bar()
.add_xaxis(metro[metro['地区']=='海淀'].head()['附近地铁站'].to_list())
.add_yaxis('海淀区', metro[metro['地区']=='海淀'].head()['id'].to_list())
.set_global_opts(legend_opts=opts.LegendOpts(is_show=True, pos_right="70%",pos_top="52%"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)))
)
bar3 = (Bar()
.add_xaxis(metro[metro['地区']=='丰台'].head()['附近地铁站'].to_list())
.add_yaxis('丰台区', metro[metro['地区']=='丰台'].head()['id'].to_list())
.set_global_opts(legend_opts=opts.LegendOpts(is_show=True, pos_left="70%", pos_top="10%"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)))
)
bar4 = (Bar()
.add_xaxis(metro[metro['地区']=='昌平'].head()['附近地铁站'].to_list())
.add_yaxis('昌平区', metro[metro['地区']=='昌平'].head()['id'].to_list())
.set_global_opts(legend_opts=opts.LegendOpts(is_show=True, pos_left="70%",pos_top="52%"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)))
)
grid = (Grid(init_opts=opts.InitOpts(theme='dark', width='800px',))
.add(bar1,grid_opts=opts.GridOpts(pos_bottom="60%", pos_right="60%"))
.add(bar2,grid_opts=opts.GridOpts(pos_top="60%",pos_right="60%"))
.add(bar3,grid_opts=opts.GridOpts(pos_bottom="60%", pos_left="60%"))
.add(bar4,grid_opts=opts.GridOpts(pos_top="60%",pos_left="60%"))
)
grid.render_notebook()4.6.租金前10名地铁站圈
平均租金前10的地铁站圈,平均每平米每月租金都高达320元,相当于10平米的单间均价每月3200以上!!
metroPrice = data.groupby('附近地铁站',as_index=False)['price'].mean().sort_values('price',ascending=False).reset_index(drop=True)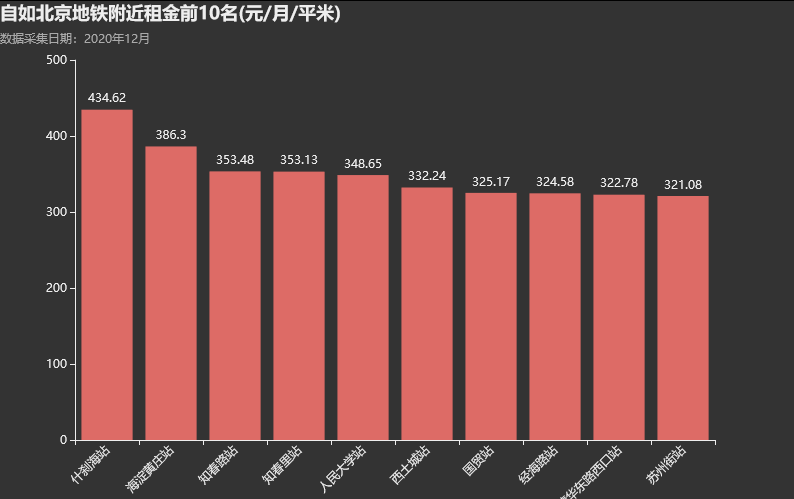 绘图代码:
绘图代码:
# 绘制柱状图
bar = (
Bar(init_opts=opts.InitOpts(theme='dark', width='800px'))
.add_xaxis(metroPrice.head(10)['附近地铁站'].to_list())
.add_yaxis('', metroPrice.head(10)['price'].round(2).to_list())
.set_series_opts(label_opts=opts.LabelOpts(formatter='{c}'))
.set_global_opts(legend_opts=opts.LegendOpts(is_show=True),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)),
title_opts=opts.TitleOpts(title="自如北京地铁附近租金前10名(元/月/平米)",
subtitle='数据采集日期:2020年12月'),
)
)
bar.render_notebook()4.7.各区合租类平均租金箱线图
东城、西城和海淀区在合租类租房平均在300左右,大部分其实都是超过300(即10平米月租金3000+)。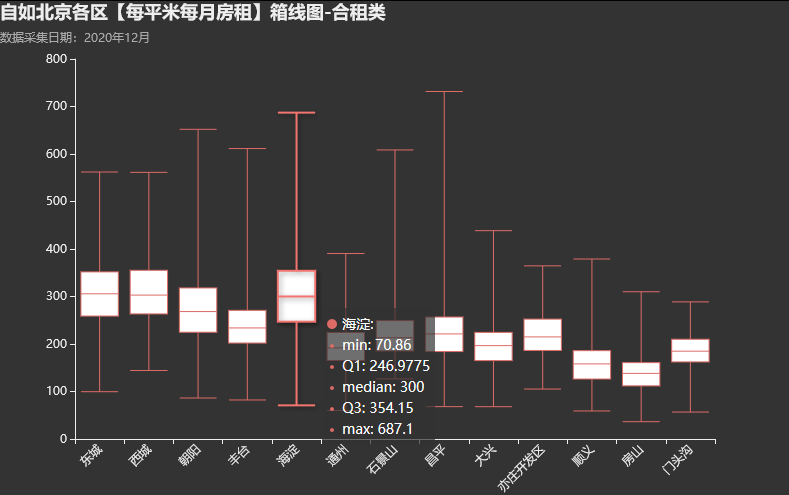 绘图代码:
绘图代码:
# 箱线图
# 合租类
x_data = list(data['地区'].unique())
y_data = [data[(data['地区']==x)&(data['类型']=='合租')]['price'].to_list() for x in x_data]
Box = (Boxplot(init_opts=opts.InitOpts(theme='dark', width='800px'))
.set_global_opts(legend_opts=opts.LegendOpts(is_show=True),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)),
title_opts=opts.TitleOpts(title="自如北京各区【每平米每月房租】箱线图-合租类",
subtitle='数据采集日期:2020年12月'),
)
)
Box.add_xaxis(x_data)
Box.add_yaxis("", Box.prepare_data(y_data))
Box.render_notebook()4.8.各区整租类平均租金箱线图
整租类平均租金低于合租类,约为合租类的一半,毕竟一般都带有客厅或者厨房之类,整体空间较大。
比如,我们常见的合租单间可能是12平米,价格在3600左右,但是对于整租50平左右的可能要价在7000左右。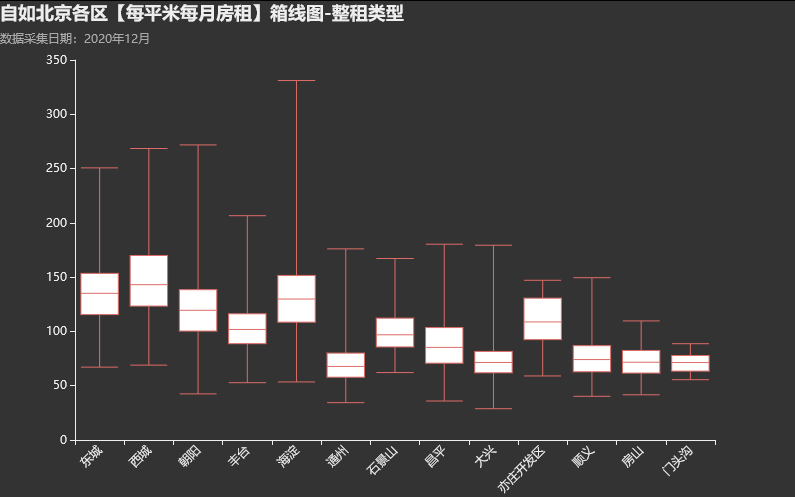
5.房间相关数据统计与可视化
就房间本身而言,价格、大小、楼层、卧室朝向以及距离地铁站距离等等都是我们在选择的时候会考虑的点。
简单做相关关联散点图,发现其实房间大小越大均价越低,其他方面似乎并没有太明显的关系。本节会涉及到seaborn绘图库的使用。
# 引入相关绘图库
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['Microsoft YaHei'] #设置全局默认字体 为 幼圆
plt.rcParams['axes.unicode_minus'] = False # 解决中文字体下负号显示问题
import seaborn as sns
sns.set_style("darkgrid",{"font.family":['Microsoft YaHei', 'SimHei']}) #seaborn绘图的字体设置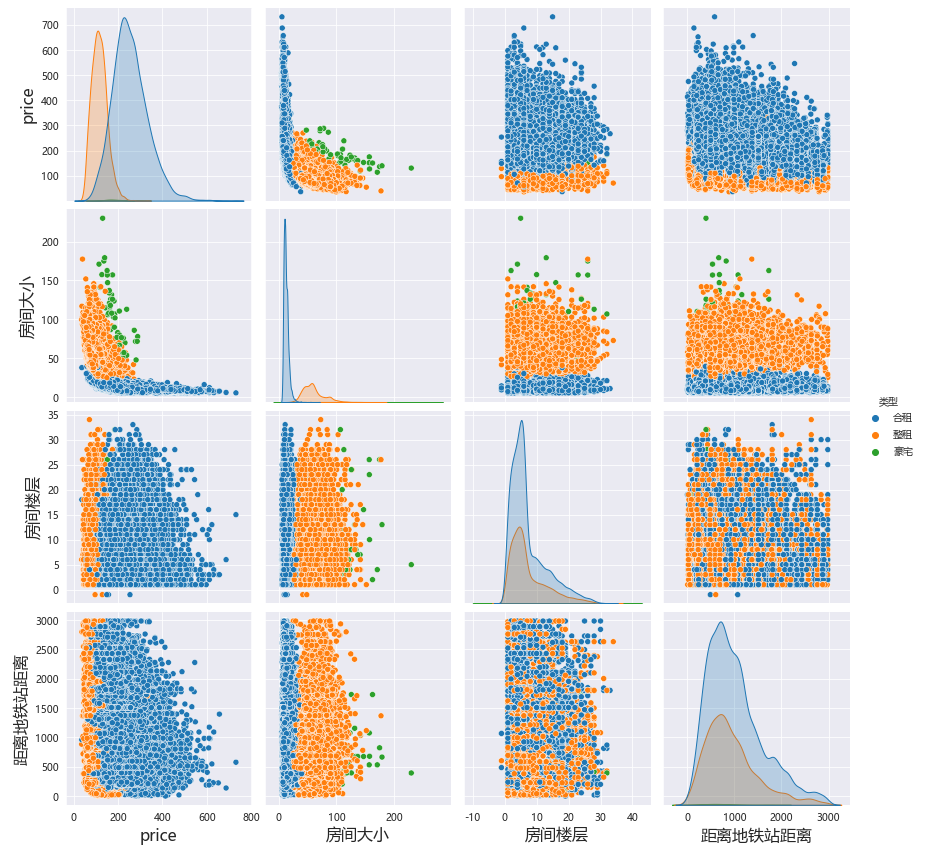 绘图代码:
绘图代码:
plt.rcParams["axes.labelsize"] = 16 # 设置全局轴标签字典大小
# 由于部分房源未标注距离地铁站距离,这里我们只选有此数据的
score = data[data['距离地铁站距离']!=''][['price','房间大小','房间楼层','距离地铁站距离','类型']]
score['距离地铁站距离'] = score['距离地铁站距离'].astype('int')
# 散点图矩阵
sns.pairplot(score, hue='类型',height=3)
5.1.合租类房间大小直方图
大部分的合租类房间大小在10平米上下,这便是绝大多数租房客们的现状,一张床、一个书桌再带上一个稍微大点的衣柜就基本满了。
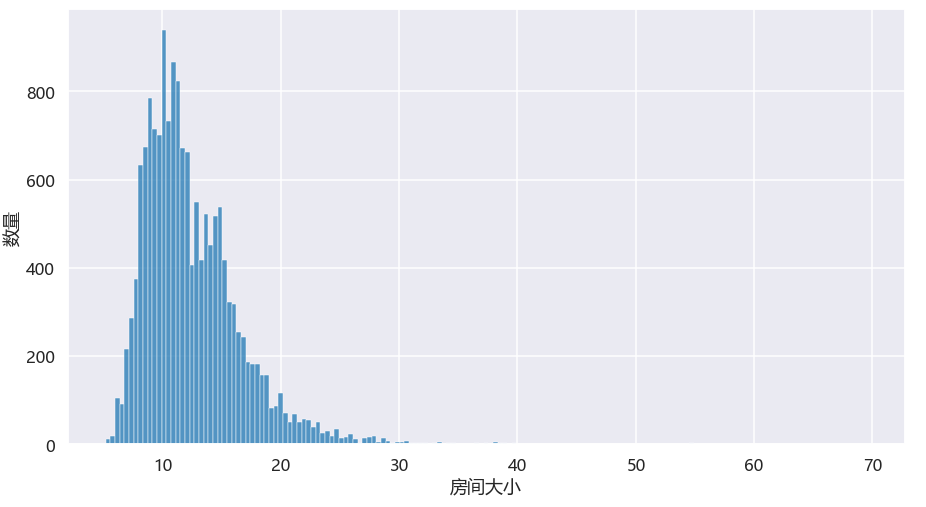
绘图代码:
plt.figure(figsize=(15,8))
sns.set_context("talk")
sns.histplot(data[data['类型']=='合租'].房间大小).set(ylabel='数量')
5.2.整租类房间大小直方图
大部分的整租类房间大小在40-60平米之间,这类房间一般都是一室一厅,大一点的会带厨房,对于个人来说是非常理想的居住环境,但是租金一般都在7000左右,属实有点高了。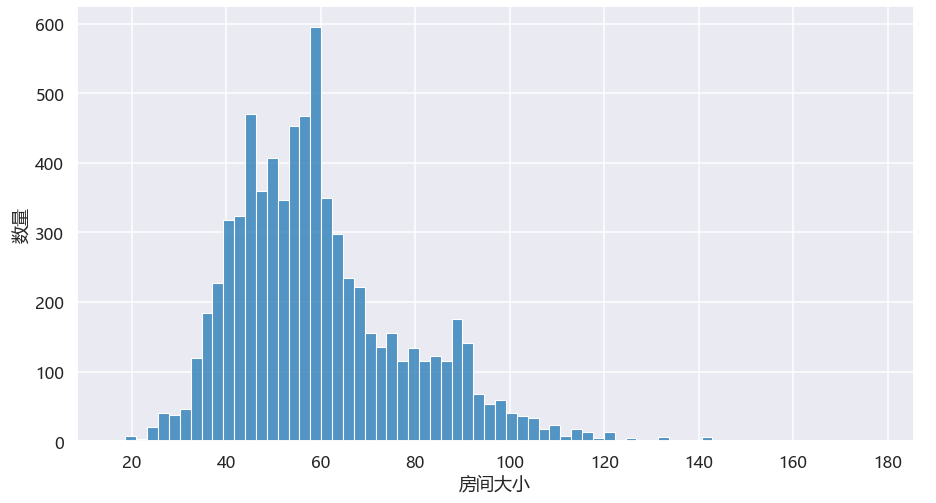
5.3.合租类房间租金直方图
图中有部分是在最左侧,这部分是日租的房子。我们看北京整体,合租类单间大部分落在2000-4000之间。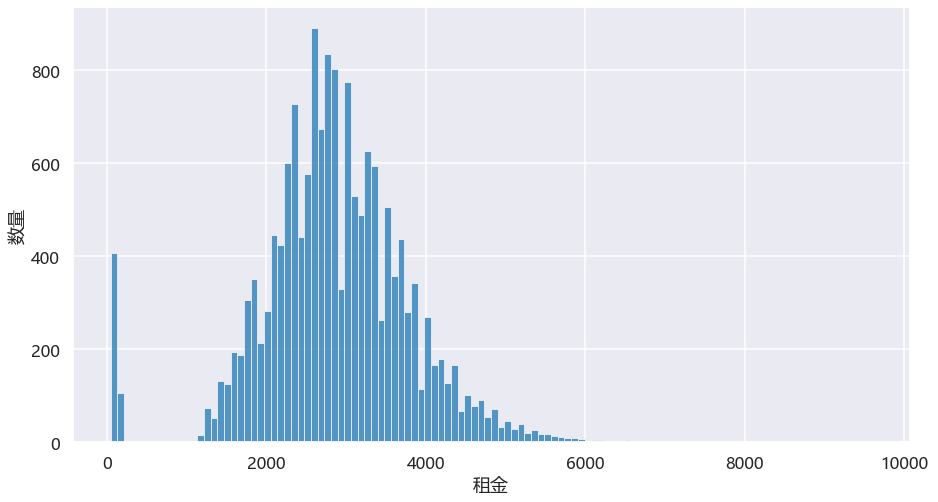 再看看海淀区,大部分落在3000上下
再看看海淀区,大部分落在3000上下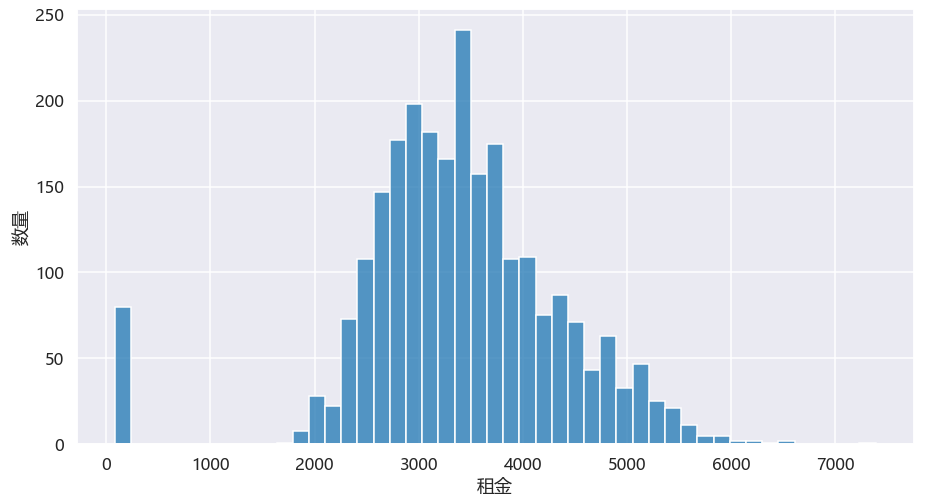
5.4.整租类房间租金直方图
图中有部分是在最左侧,这部分是日租的房子。我们看北京整体,合租类单间大部分落在5000-7500之间。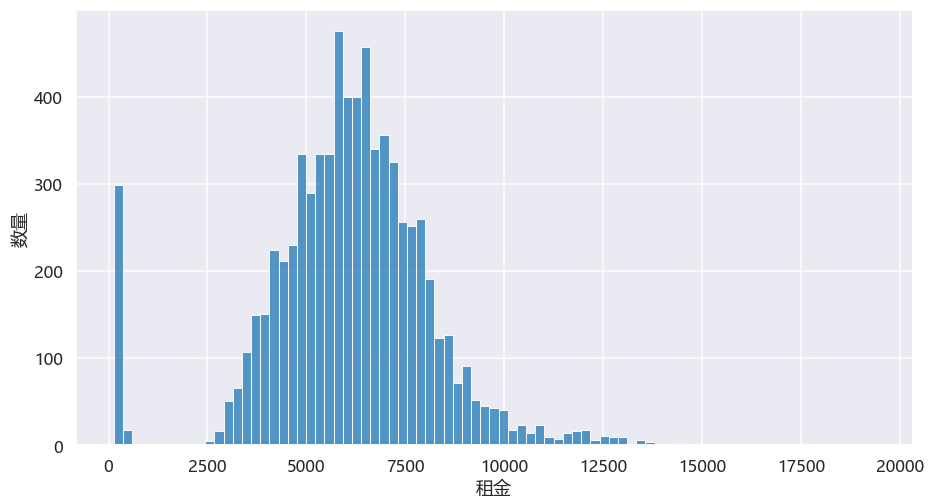 再看看海淀区,基本上都落在5000+以上,以7000左右居多。
再看看海淀区,基本上都落在5000+以上,以7000左右居多。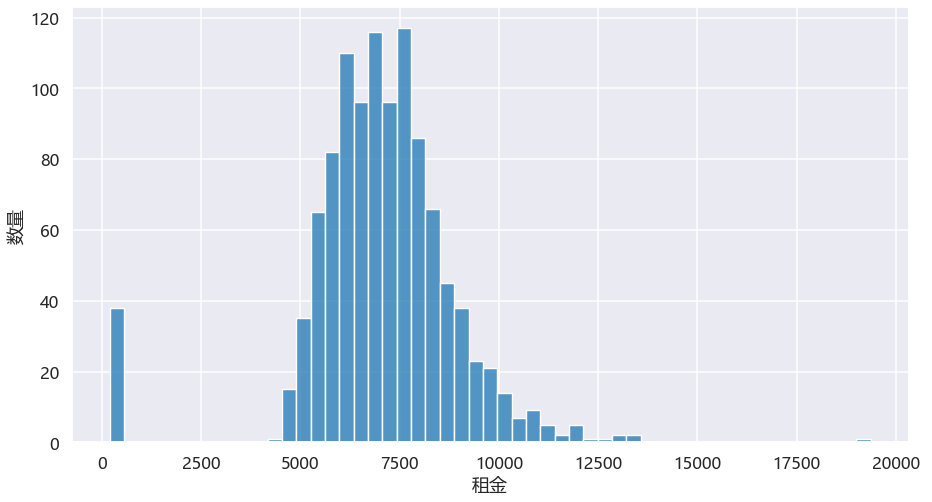
5.5.房源距离地铁站距离直方图
其实大部分的房源距离最近地铁站步行距离较近,1000米以内。绝大多数的房源距离最近地铁站直线距离在1.5公里,感觉步行到地铁站也就15分钟以内。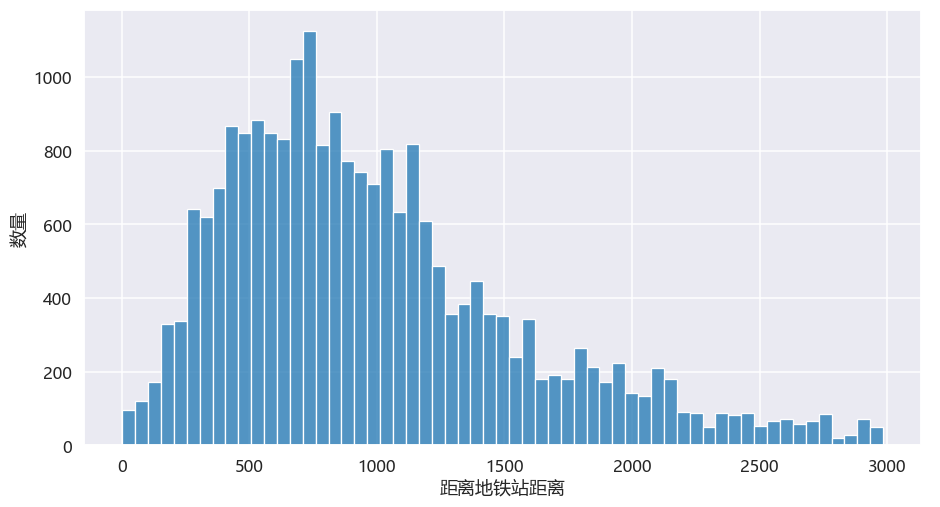
5.6.平米租金与距离地铁站距离回归图
简单做回归关系图,大致呈现距离地铁站越近其平均平米房租越低。不过,大家可以试着做归一化处理后再来看,可能会更明显,这里不做展开,大家留作作业吧!
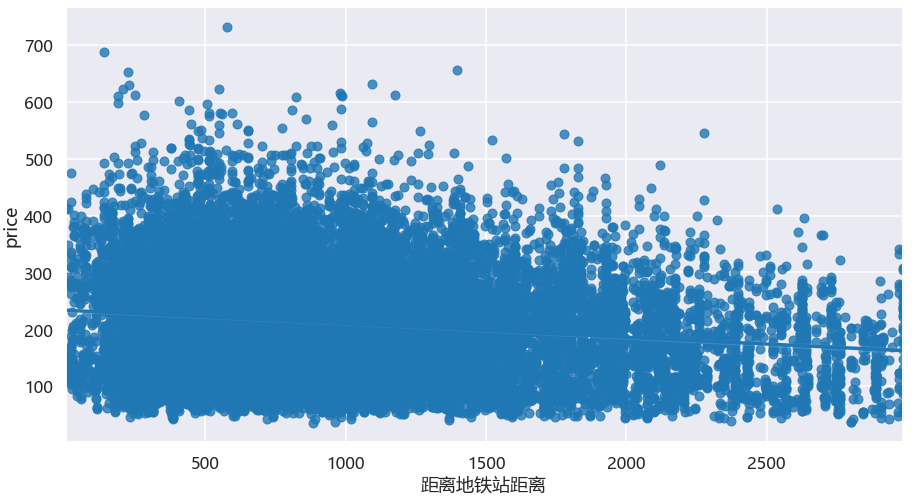
5.7.各区卧室朝向与平米租金热力图
我们观察卧室朝向和平均平米租金热力图,怎么感觉北卧和东北卧的价格更高呀,反正我住的是北卧!!
# 数据统计
data_table = data[data['类型']=='合租'].pivot_table(values='price',index='卧室朝向',columns='地区',aggfunc='mean')
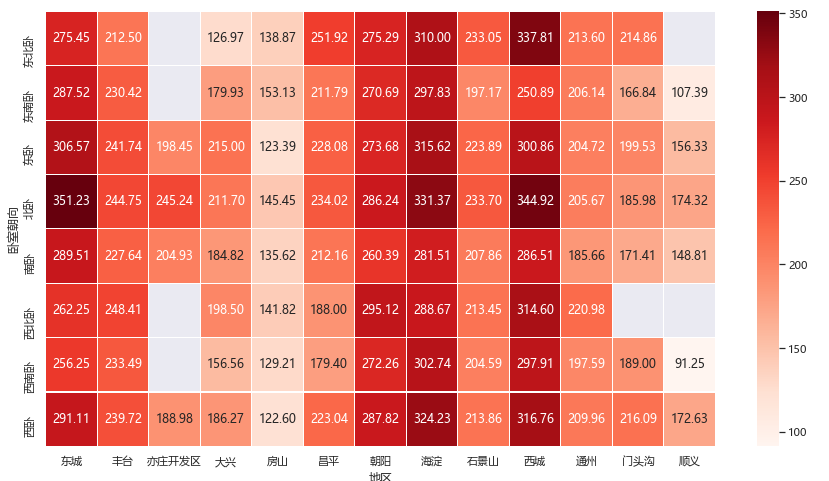 绘图代码:
绘图代码:
# 卧室朝向价格热力图
plt.figure(figsize=(15,8))
# sns.set_context("talk")
sns.set_context("notebook")
sns.heatmap( data_table, cmap='Reds', annot=True, fmt='0.2f', linewidths=0.2)
5.8.户型分布
合租房以3居室为主,其次是4居室和2居室;整租房以一室一厅和二室一厅为主,其他户型较少。
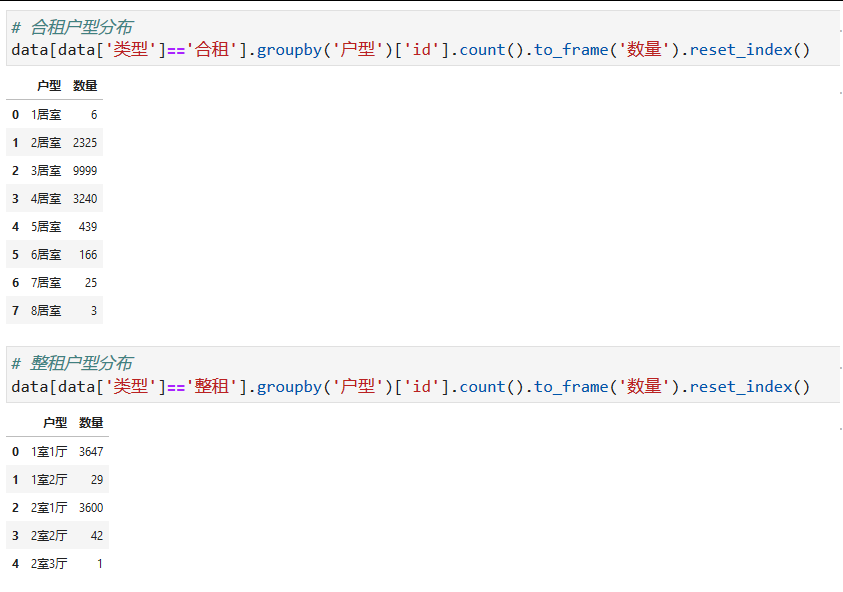
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~