
Python玩爬虫,爬取安居客租房数据
前言
最近我打算在西安市长安区租个房子,于是打开安居客官网进行浏览,点击了航天一小区域结果搜索出了一堆房源信息,为了综合比较找出更加适合我的选择,我敲了个代码将租赁数据批量爬取了下来。对于如何翻页爬取数据这个难题,我苦思冥想了一早上,突然想起蚂蚁老师的《零基础学Python简单爬虫》中教过我如何翻页爬取他的博客。我赶快去网易云课堂上回顾了一下知识点,很快就解决了难题!
1.导入python库
import requests
import parsel
import csv
2.编写请求头
首先打开安居客网站的主页,然后点击选择西安市长安区租房,再点击我感兴趣的航天一小区域。按F12进入开发者模式,用开发者工具搜索“航天城 航天一小一中 航天城二期主卧 神州六路 领包入住”,搜索出数据包后获取cookie、referer和user-agent,编写请求头可以在请求数据时防止被反爬。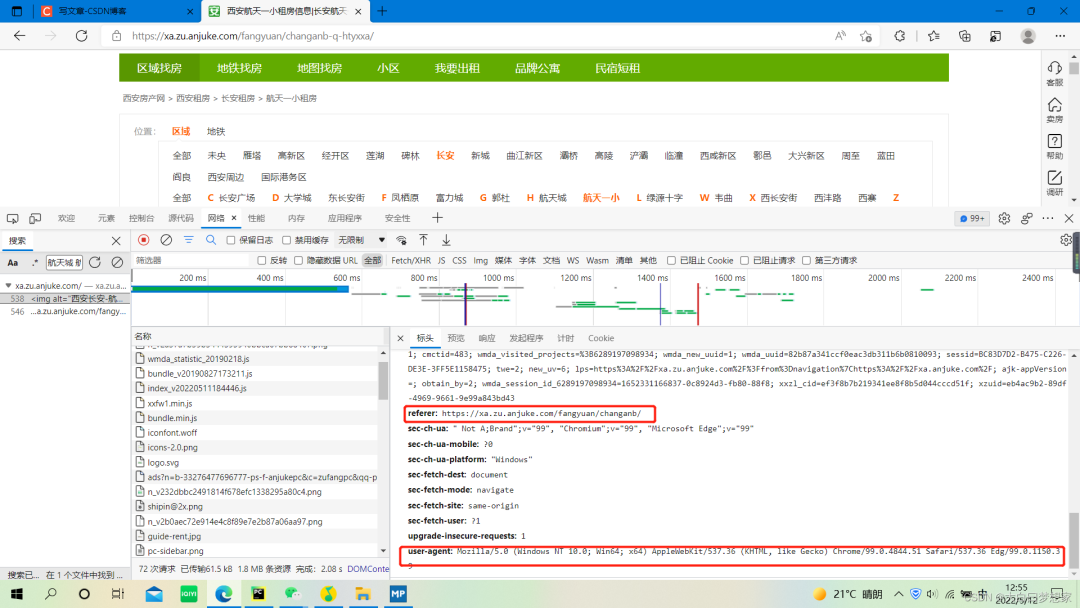
headers = {
"cookie":"SECKEY_ABVK=TgvSiy4m0B6i5M/GnutrL4MCQAxmauku4aF+LqjfcV8%3D; BMAP_SECKEY=E59uL36Kjw3iB4ZVJ1TzktcDRrwsPacuhFPlFvVySikxHflBOrAIKvnT_TWYzT5URefDsASa2VWCiaIX9be4V3Lnrh_Nos62tZXNwvoSq4VTzasiJ1egkq-odC5S4rdqxoaD8o2T1GJGf2QcMzz9qmHUmR4U12vFef9JGFoyWvQ; aQQ_ajkguid=480A83B5-6C24-CA9A-70C4-SX0705130713; isp=true; id58=e87rkGDik4M4TQ8rCOH9Ag==; 58tj_uuid=646ff6e2-1cdd-40ea-a598-19787fe938e3; als=0; _gid=GA1.2.1430887075.1652243486; _ga=GA1.2.365181464.1652243486; ajk-appVersion=; ctid=31; fzq_h=66195fd3068b1f875345633f8c10fa4a_1652243654423_6c16e54157d8446097cc7e59ed9481e0_2102187861; cmctid=483; wmda_visited_projects=%3B6289197098934; wmda_new_uuid=1; wmda_uuid=82b87a341ccf0eac3db311b6b0810093; sessid=89F34445-4127-728C-6A4A-B58CD71D8F23; twe=2; init_refer=https%253A%252F%252Fcn.bing.com%252F; new_uv=5; lps=https%3A%2F%2Fxa.zu.anjuke.com%2F%3Ffrom%3Dnavigation%7Chttps%3A%2F%2Fxa.anjuke.com%2F; wmda_session_id_6289197098934=1652272846315-4adb7df7-8ce6-9b96; obtain_by=2; new_session=0; xxzl_cid=ef3f8b7b219341ee8f8b5d044cccd51f; xzuid=eb4ac9b2-89df-4969-9661-9e99a843bd43",
"referer":"https://xa.zu.anjuke.com/fangyuan/changanb/",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39",
}
3.创建csv文件
创建好CSV文件后,我们可以用下面的方式添加表头
f = open('安居客租房数据.csv',mode='a',encoding='utf-8',newline='')
csv_writer = csv.DictWriter(f,fieldnames=['标题','房子类型','楼层','价格','小区','地址','详情'])
csv_writer.writeheader() #写入表头
4.解析数据、翻页爬取
大家可以用选择工具,点击需要爬取的数据,找到数据的源代码,然后右键点击“复制selector”,这样不用非常熟悉CSS语法也可以轻松的解析数据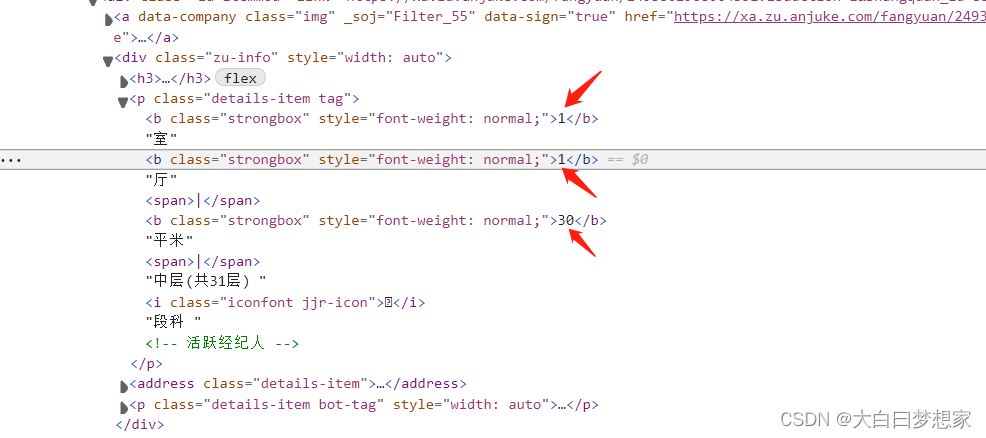
for page in range(1,3): #数据只有两页,用for循环进行翻页爬取
url = f'https://xa.zu.anjuke.com/fangyuan/changanb-q-htyxxa/p{page}/'
r = requests.get(url = url,headers = headers)
selector = parsel.Selector(r.text)
zu_infos = selector.css('.zu-itemmod') #用CSS选择器,提取每页所有房子数据的信息
for info in zu_infos:
try:
title = info.css('.strongbox::text').get() #解析出标题
house_num = info.css('div.zu-info > p.details-item.tag > b::text').getall() #提取出所有b标签的文本数据,即户型数值
p = info.css('div.zu-info > p::text').getall() #提取出所有p标签的文本数据,变量p是个列表
p = p[1:5] #去掉无用信息
height = p[-1].strip(' ') #提取出房子所在的楼层
house_unit = p[:3] #提取户型单位
house_type = [house_num[i] + house_unit[i] for i in range(len(house_num))] #将户型数字与户型单位进行字符串拼接
house_type = ' '.join(house_type) #列表中各个字符串元素用空格连接
price = info.css('div.zu-side > p > strong > b::text').get() + '元/月' #解析出房源的价格
community = info.css('div.zu-info > address > a::text').get() #提取小区名称
address = info.css('div.zu-info > address::text').getall()[1].strip('\xa0\xa0\n ') #提取房子所在地址
detail = info.css('div.zu-info > p.details-item.bot-tag > span::text').getall() #提取:租赁方式、朝向、有无电梯、附近有哪条地铁
detail = ' '.join(detail) #列表中各个字符串元素用空格连接
print(title,house_type,height,price,community,address,detail)
dit = {
'标题': title,
'房子类型':house_type,
'楼层':height,
'价格': price,
'小区': community,
'地址': address,
'详情': detail,
}
csv_writer.writerow(dit) #写入csv
except:
pass
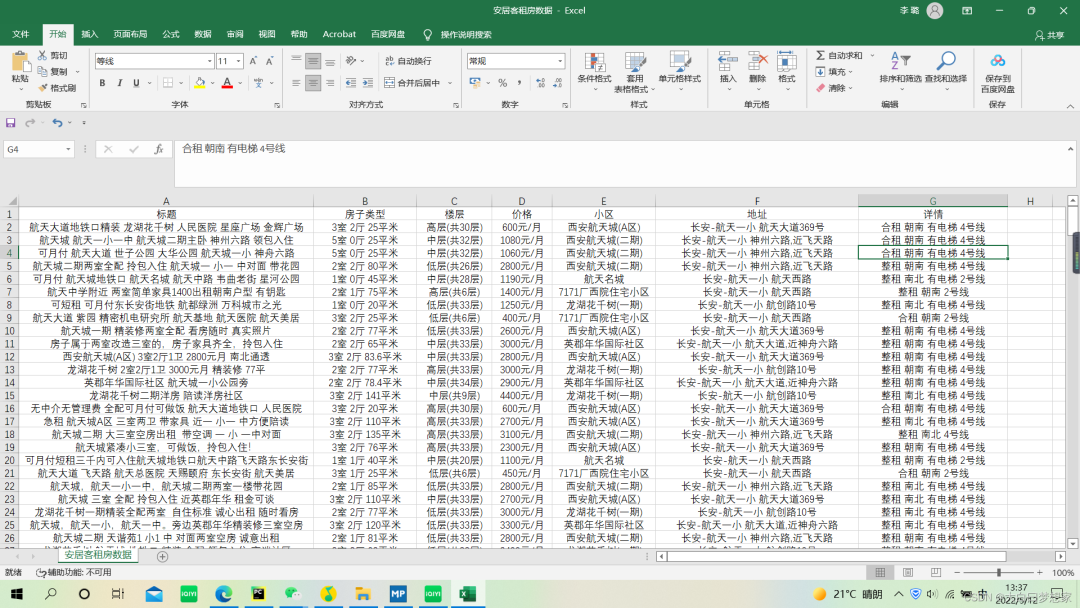 得到所有数据后有时候Excel直接打开会乱码,大家可以先用记事本打开,然后另存为时编码格式改为“ANSI”编码,最后再用Excel打开就好了。现在我可以在Excel里慢慢查看这些房源是否满足自己的要求,希望我能安全、省心,用最低的交易成本租到满意的房子,希望大家也能有所收获!
得到所有数据后有时候Excel直接打开会乱码,大家可以先用记事本打开,然后另存为时编码格式改为“ANSI”编码,最后再用Excel打开就好了。现在我可以在Excel里慢慢查看这些房源是否满足自己的要求,希望我能安全、省心,用最低的交易成本租到满意的房子,希望大家也能有所收获!
最后,推荐蚂蚁老师的视频课程,购买课程提供答疑服务、付费群聊
评论