文摘菌记得小时候看《哈利·波特》小说的时候,最难记住的就是那些音译的名字,又长又多,最后只能关注那几个主要人物,跟着主要剧情一路过去,当个爽文看完了。
这就导致一些边缘人物根本没关注到,也错过了J·K·罗琳埋下的许多小伏笔。
比如卢娜与韦斯莱其实是邻居关系,这个在《火焰杯》中众人出发去世界杯时有伏笔,但是很少有人第一遍看的时候能注意到。
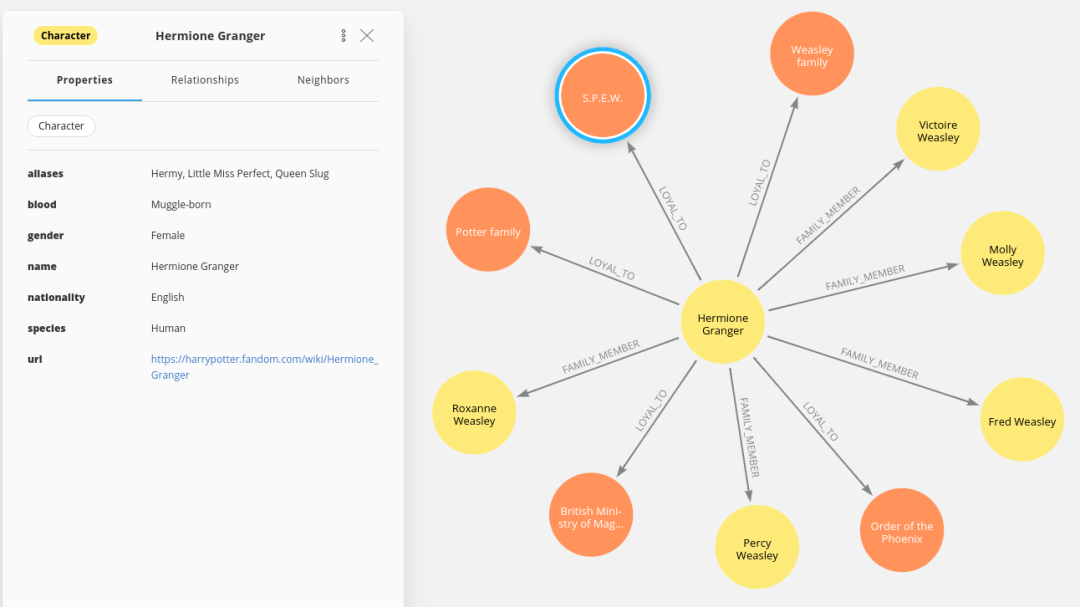
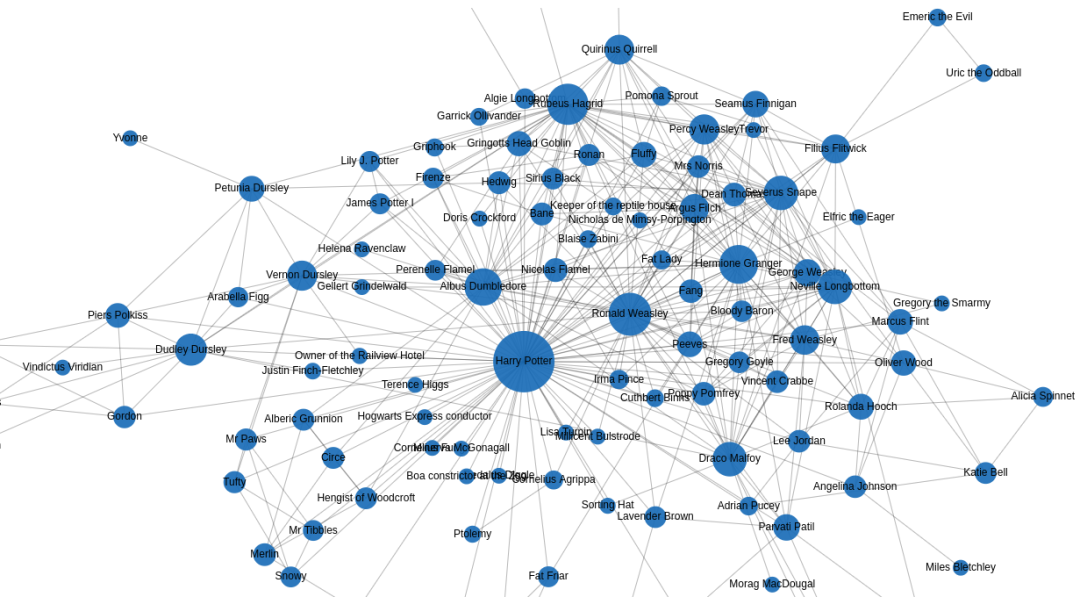
大概是为了从一开始就厘清人物关系,Medium上一位博主Tomaz Bratanic开发了一个小项目,用Selenium结合SpaCy来创建一个Neo4j哈利·波特人物图谱,把《哈利·波特》第一部中所有的人物都纳入一张网络中,人物关系一目了然。
从图谱中我们似乎可以看到,三人小分队中,哈利和赫敏的直接连接很少,这两人出现时基本罗恩都在,而罗恩和赫敏二人却连接很多,这让人不禁联想,难道从第一部开始,J·K·罗琳就安排好了罗恩和赫敏的姻缘了?
八卦的事情我们先放在一边,还是先来看看Tomaz Bratanic是如何制作这一图谱的。
总体来说,整个过程被分为了5步:
作者将整个过程记录了一个Google Colab notebook,方便大家动手试试,链接如下:https://github.com/tomasonjo/blogs/blob/master/harry_potter/HarryPotterNLP.ipynb
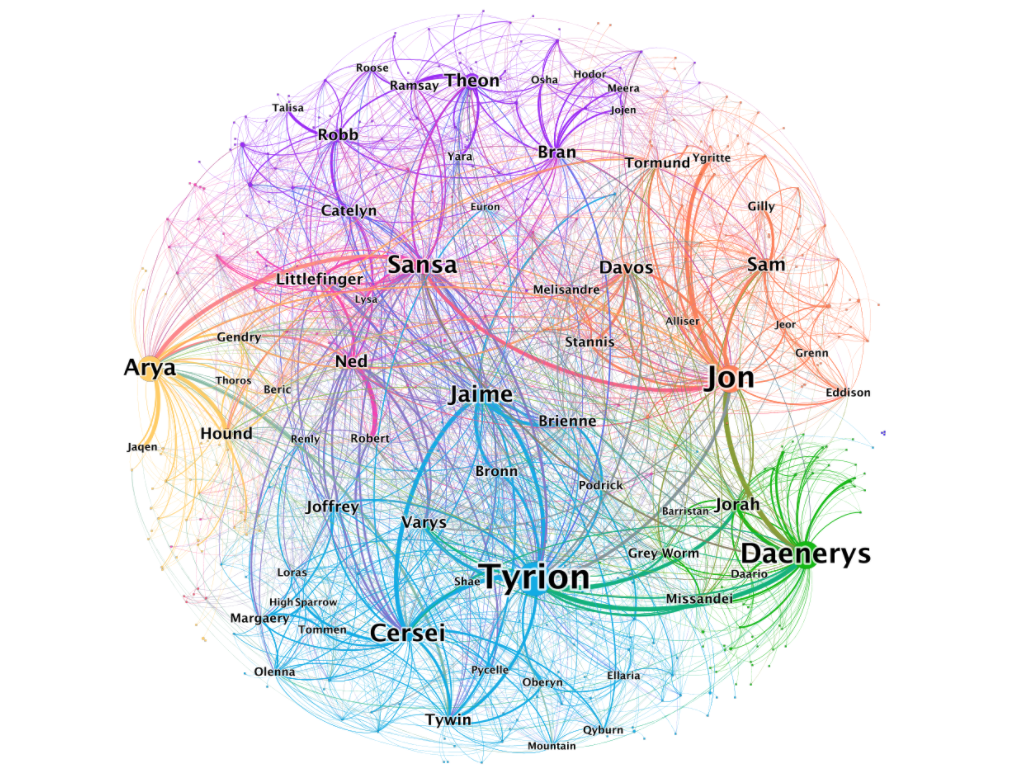
“哈利波特迷”网站页面包含了第一本书中的人物列表,其中还包括了各个人物最初出现在哪一章,这可以帮助进一步消除字符的歧义,因此第一步就是去爬取“哈利波特迷”网站数据。作者选择使用Selenium进行Web页面抓取,然后形成一个字符列表,其中包含人物最先出现的章节的信息,此外,每个角色都有一个网页,上面有关于角色的详细介绍。例如,从赫敏·格兰杰的页面你可以观察到一个结构化的表格,其中包含了更多的信息,作者使用别名部分的实体提取然后添加其他字符细节,如家族和血型来丰富最后的人物图谱。由于文本中人物往往散布于文本的不同位置,其中涉及到的人物通常可以有多种不同的表达方式,例如某个语义关系中的实体可能是以代词形式(比如he和she)出现的,为了更准确且没有遗漏地从文本中抽取相关信息,必须要对文章中的指代现象进行消解。在寻找合适的指代消解(Co-reference Resolution)模型时,作者考虑了NeuralCoref和AllenNLP,这两个模型都能提供指代消解功能。但是在试用AllenNLP模型输入整个章节时,作者的内存不够,把一个章节分割成一个句子列表又运行得非常慢,所以作者最后还是使用了NeuralCoref,NeuralCoref很轻松地处理了整个章节,并且工作得更快。作者一开始试了几个不同的命名实体识别(Named Entity Recognition,NER)模型,SpaCy、HuggingFace、Flair,甚至是 Stanford NLP。但是这些模型都不能很好地满足我的要求。因此,作者决定使用SpaCy基于规则的模式匹配特性,而不是自己训练模型。根据第一步从网站上搜集的数据,现在已经知道我们需要在寻找哪些角色,下面只需要找到一种方法,在文本中尽可能完美地匹配他们。首先必须为每个字符定义文本模式。这需要添加全名作为我们正在寻找的模式,然后我们使用空格将名称分开,并创建一个模式,将这个,名字中的每个单词分开。举个例子,如果我们定义了matcher模式,我们最终会得到3个不同的文本模式来表示给定的字符:当然,还会有许多特例,比如“天狼星布莱克”(Sirius Black),为了不将所有“黑色”(Black)和人物搞混,作者定义只有当“布莱克”是标题格式的,才会假设“小天狼星布莱克”被引用。另外,还需要考虑当只提到姓时,如何匹配到正确的人,比如这句话,“Weasley, get over here!”,这里面的Weasley可能指向罗恩的任何一个兄弟姐妹,这时必须为实体消歧提出一个通用的解决方案。解决了实体识别问题,其实就已经完成了整个工作中最难的部分。推断角色之间的关系则非常简单,首先,需要定义相互作用的距离阈值或两个字符之间的关系。作者将距离阈值定义为14,也就是说,如果两个字符在14个单词的距离内共同出现,那么我们假设它们一定是相互作用的。此外,作者还合并了一些实体以避免扭曲结果,比如“哈利今天过得很愉快。他下午去找邓布利多谈话了。”如果简单分析这句话,会让“哈利”和“邓布利多”发生两次互动,因此需要按照引用单个实体的相同字符的顺序合并实体,来解决重复统计的问题。提取了字符之间的交互网络后,剩下的唯一工作就是将结果存储到图形数据库中。导入查询非常简单,因为这里处理的是单向网络,如果使用的 是作者准备的Colab Notebook,那么创建一个免费的Neo4j Sandbox 或者免费的Aura数据库实例来存储结果将是最简单的。最后,可视化结果,我们就能得到最终的人物关系图谱。灵感来自《权利的游戏》人物图谱,下一步要分析哈利·波特宇宙在文章中,作者表示,这一项目的灵感来源于此前Andrew Beveridge建立的《权利的游戏》人物图谱。相比于《哈利·波特》,《权力的游戏》拥有更多的人物和剧情,生成的网络也更加复杂。除了对整个1-8季进行分析,Andrew Beveridge还对每一季做了人物图谱分析,看看每一季中谁和谁是盟友,谁跟谁又是敌人。感兴趣的读者可以查看项目链接:https://networkofthrones.wordpress.com/相比而言,Tomaz Bratanic的《哈利·波特》人物图谱项目更容易上手,读者可以用第二部或第三部尝试这种方法,唯一需要稍微调整的是实体消除歧义过程。https://github.com/tomasonjo/blogs/blob/master/harry_potter/HarryPotterNLP.ipynbTomaz Bratanic表示,下一步他将着手整个哈利·波特宇宙的分析,将《神奇动物在哪里》的部分也囊括进去,感兴趣的小伙伴可以持续关注。https://medium.com/neo4j/turn-a-harry-potter-book-into-a-knowledge-graph-ffc1c45afcc8https://networkofthrones.wordpress.com/https://harrypotter.fandom.com/wiki/Main_Page