
机器学习中各种树模型总结
来自于点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
作者:ChrisCao@知乎
https://zhuanlan.zhihu.com/p/75468124编辑:好奇心log
一. 决策树
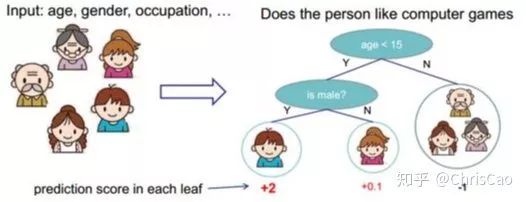
1.ID3算法:以信息增益为准则来选择最优划分属性
 信息熵越小,数据集
信息熵越小,数据集  的纯度越大
的纯度越大 上建立决策树,数据有
上建立决策树,数据有  个类别:
个类别:
 表示第K类样本的总数占数据集D样本总数的比例。
表示第K类样本的总数占数据集D样本总数的比例。2.C4.5基于信息增益率准则 选择最有分割属性的算法
 ,
, 
3.CART:以基尼系数为准则选择最优划分属性,可用于分类和回归
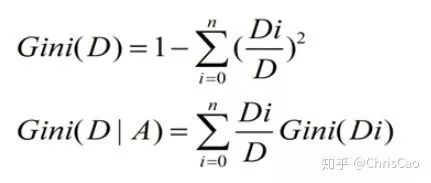
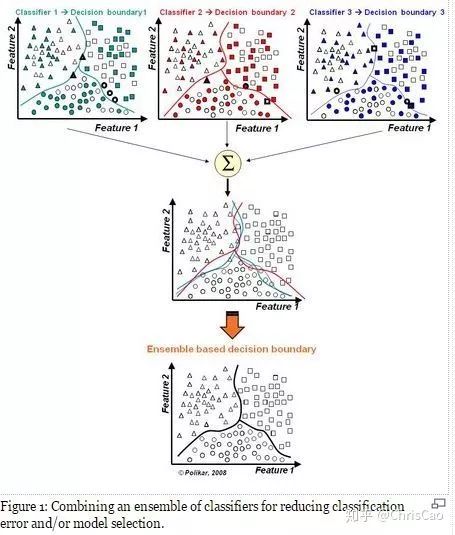
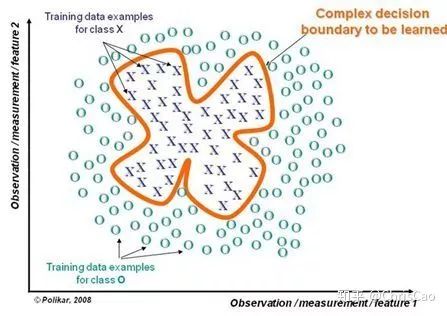
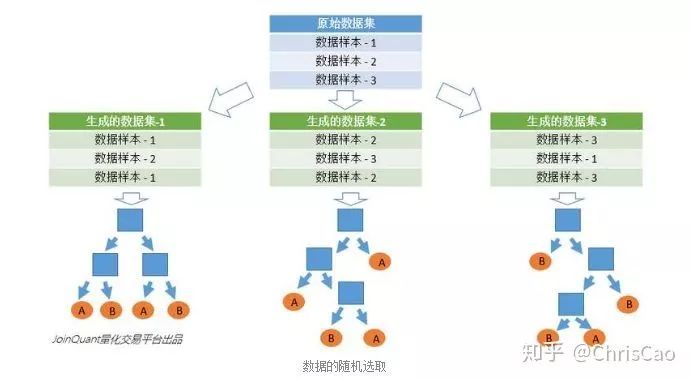
二.随机森林
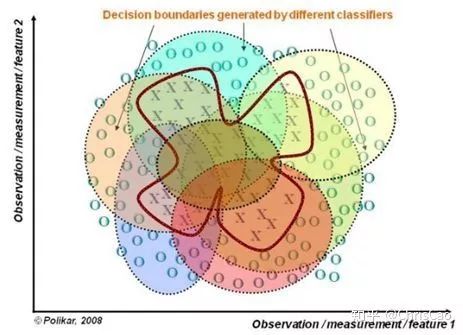
1.构建组合分类器的好处:
三、GBDT和XGBoost
1.在讲GBDT和XGBoost之前先补充Bagging和Boosting的知识。
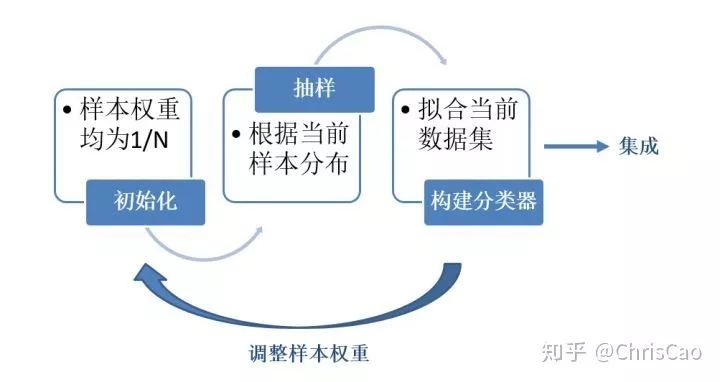
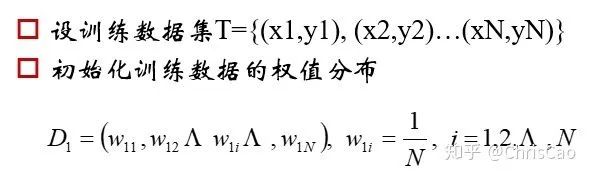

 计算的是当前数据下,模型的分类误差率,模型的系数值是基于分类误差率的
计算的是当前数据下,模型的分类误差率,模型的系数值是基于分类误差率的

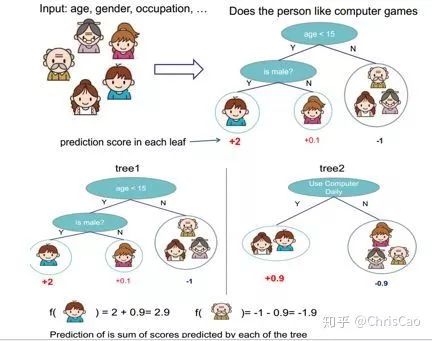
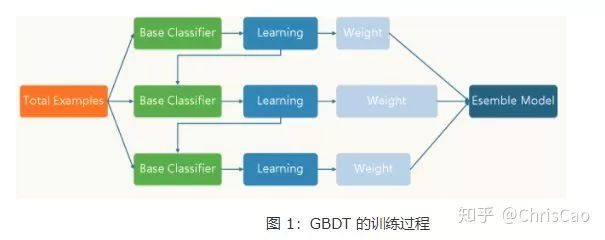
2.GBDT

3.XGBoost


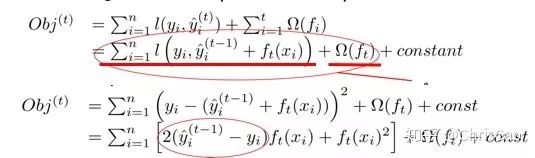
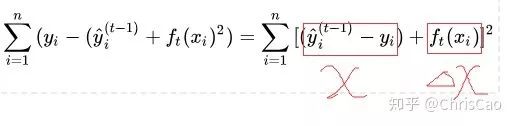

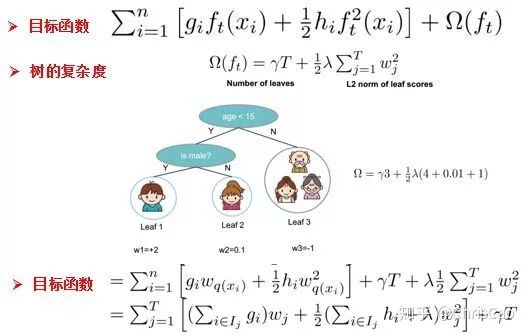
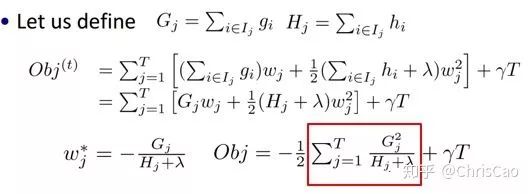

point的候选,遍历所有的候选分裂点来找到最佳分裂点。
评论