
一文搞懂工程化协同推荐算法(一)

作者:livan
来源:数据EDTA
前言

推荐系统的重要性已经不需要过多的强调了,随处一搜索就能看到各领域的大佬告诉你推荐系统的构建方法,面试的时候不讲几个协同都不好意思说自己懂算法,各个资料都会对协同的每一个细节详细描述,但是,不知大家看完之后有没有一个感触:各个知识点都了解了,就是串不起了,而且也多少会有些疑惑,就这么简单?被全宇宙的人推崇的推荐算法就是简单的几个表的来回计算吗?那平时我们应用的机器学习的各种算法都去哪里了?
1、协同推荐算法数理表达
市面上能接触到的推荐内容主要有两类:一类是协同,多个表之间的计算推导,有一些机器学习的影子,但是明显感觉到机器学习算法是对协同的一次次补充,不是推荐的主流算法,再深究一下,很多人就开始大肆宣传深度学习的神奇之处,用深度学习进行推荐推演是多么的精准高效。一时间搞的笔者一头雾水。笔者也就这个问题咨询过一些老牌的推荐大佬,得到了各种各样的答案。深思良久,笔者将自己对推荐算法的一些理解整理出来,有不足之处欢迎大家批评指正。
1) 推荐算法本质上不是一个技术问题,而是一个用技术解决问题的解决方案。
推荐的产生是由于产品越来越多,而由于精力、手机屏幕大小的限制,客户能看到的范围有限,长尾现象越来越严重,为了方便客户获取到想要的产品,各个公司开始考虑根据用户的喜好推荐客户有倾向的产品,尽量减少马太效应,推荐系统应运而生。
2) 推荐算法不是一个算法,而是一套算法集合,其算法范围无所不包容。
推荐算法是由一系列算法组合而成,每个算法应用场景不一样,各个公司根据各自的客户特征和商品属性,挑选适合本公司使用的推荐逻辑,使用的算法也不完全一样。协同推荐算法是比较早被研发出来的推荐逻辑,因为其逻辑较为清晰、可解释性比较强、数据兼容性、可执行性和工程化比较好,所以一直被各个公司应用,后期推出的基于模型的推荐、基于深度学习的推荐也都能看到协同推荐的影子,可以说协同推荐是现在各个公司推荐系统的基础逻辑。
本文从推荐基础的角度,将各个协同推荐的逻辑串联在一起,希望能将协同推荐的基本结构描述清楚,如有不足之处请指正:
协同推荐的基本内容主要有三部分:
1) 基于用户相似的推荐:
主要是找寻兴趣喜好相似的用户,然后根据用户购买的商品将商品推荐给相似的用户。
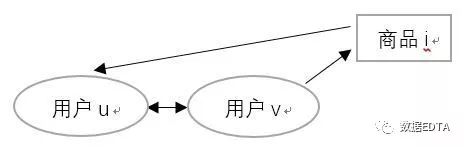
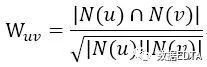
其中,用户u和用户v,令N(u)表示用户u曾经有过正面反馈的物品集合。 用户对物品的感兴趣程度:
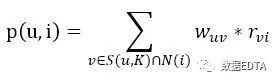
2 ) 基于物品相似的推荐:
主要是找寻相似的商品,然后根据用户购买的商品清单将相似商品推荐给用户。
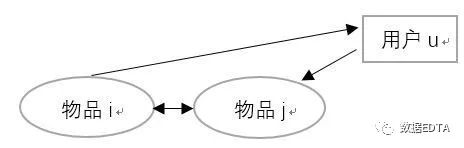
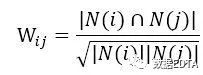
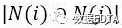 是同时喜欢物品i和j的用户数。用户对物品的喜好程度为:
是同时喜欢物品i和j的用户数。用户对物品的喜好程度为: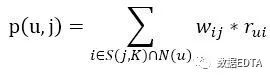
3) 基于标签的推荐:
标签系统的主要原理是通过一定的方式标记出用户和商品的标签,进而通过标签关联用户和商品。

用户对标签的喜好程度为Pre(u,t):
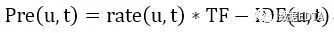
其中:
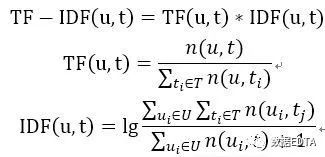
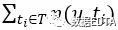 表示用户u使用所有标签标记的次数和,
表示用户u使用所有标签标记的次数和,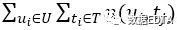 表示所有用户对所有标签的标记计数和,
表示所有用户对所有标签的标记计数和,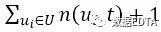 表示所有用户对标签t的标记计数和。
表示所有用户对标签t的标记计数和。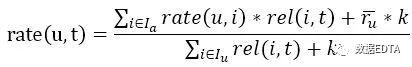
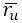 为用户u的所有评分的平均值。
为用户u的所有评分的平均值。
4) 基于上下文的推荐:
常规的基于用户协同的推荐为:
在此基础上修改计算方法为:
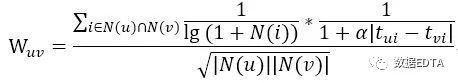
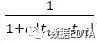 为计算用户相似度时的时间衰减函数,N(i)为对物品i产生过行为的用户个数,a为时间衰减因子,
为计算用户相似度时的时间衰减函数,N(i)为对物品i产生过行为的用户个数,a为时间衰减因子,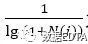 为热门惩罚函数。
为热门惩罚函数。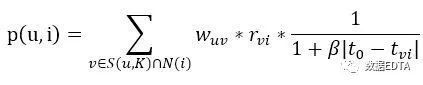
其中,
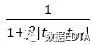 为用户对物品评分时的时间衰减函数。
为用户对物品评分时的时间衰减函数。由此可以得出新的推荐计算方式。
通过上面的描述,大家是不是对推荐算法有一个数理方面的了解呢?不知道有多少大佬看到这里,接下来我们用库表的语言再进行一次汇总描述,毕竟,我们的所有计算最终都是要落到数据仓库中的,表的形式表达是IT人员的必经之路。
◆ ◆ ◆ ◆ ◆
长按二维码关注我们
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
评论