
计算机视觉的数据增广技术大盘点!附涨点神器,已开源!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

下文所有的代码都来自PaddleClas:
GitHub 链接:
https://github.com/PaddlePaddle/PaddleClas
Gitee 链接:
https://gitee.com/paddlepaddle/PaddleClas
8大数据增广方法
首先咱们先来看看以ImageNet图像分类任务为代表的标准数据增广方法,该方法的操作过程可以分为以下几个步骤:
图像解码,也就是将图像转为Numpy格式的数据,简写为 ImageDecode。 图像随机裁剪,随机将图像的长宽均裁剪为 224 大小,简写为 RandCrop。 水平方向随机翻转,简写为 RandFlip。 图像数据的归一化,简写为 Normalize。 图像数据的重排。图像的数据格式为[H, W, C](即高度、宽度和通道数),而神经网络使用的训练数据的格式为[C, H, W],因此需要对图像数据重新排列,例如[224, 224, 3] 变为 [3, 224, 224],简写为 Transpose。 多幅图像数据组成 batch 数据,如 BatchSize 个 [3, 224, 224] 的图像数据拼组成 [batch-size, 3, 224, 224],简写为 Batch。
图像变换类:对 RandCrop 后的 224 的图像进行一些变换,包括AutoAugment和RandAugment。 图像裁剪类:对Transpose 后的 224 的图像进行一些裁剪,包括CutOut、RandErasing、HideAndSeek和GridMask。 图像混叠:对 Batch 后的数据进行混合或叠加,包括Mixup和Cutmix。

图像变换类
01
AutoAugment
论文地址:
https://arxiv.org/abs/1805.09501v1
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import ImageNetPolicy
from ppcls.data.imaug import transform
size = 224
# 图像解码
decode_op = DecodeImage()
# 图像随机裁剪
resize_op = ResizeImage(size=(size, size))
# 使用AutoAugment图像增广方法
autoaugment_op = ImageNetPolicy()
ops = [decode_op, resize_op, autoaugment_op]
# 图像路径
imgs_dir = “/imgdir/xxx.jpg”
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)

02
RandAugment
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import RandAugment
from ppcls.data.imaug import transform
size = 224
# 图像解码
decode_op = DecodeImage()
# 图像随机裁剪
resize_op = ResizeImage(size=(size, size))
# 使用RandAugment图像增广方法
randaugment_op = RandAugment()
ops = [decode_op, resize_op, randaugment_op]
# 图像路径
imgs_dir = “/imgdir/xxx.jpg”
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)

图像裁剪类
图像裁剪类主要是对Transpose 后的 224 的图像进行一些裁剪,即裁剪掉部分图像,或者也可以理解为对部分图像做遮盖,共有CutOut、RandErasing、HideAndSeek和GridMask四种方法。
03
Cutout
论文地址:
https://arxiv.org/abs/1708.04552
通过 Cutout 可以模拟真实场景中主体被部分遮挡时的分类场景。 可以促进模型充分利用图像中更多的内容来进行分类,防止网络只关注显著性的图像区域,从而发生过拟合。
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import Cutout
from ppcls.data.imaug import transform
size = 224
# 图像解码
decode_op = DecodeImage()
# 图像随机裁剪
resize_op = ResizeImage(size=(size, size))
# 使用Cutout图像增广方法
cutout_op = Cutout(n_holes=1, length=112)
ops = [decode_op, resize_op, cutout_op]
# 图像路径
imgs_dir = “/imgdir/xxx.jpg”
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)

04
RandomErasing
论文地址:
https://arxiv.org/pdf/1708.04896.pdf
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import ToCHWImage
from ppcls.data.imaug import RandomErasing
from ppcls.data.imaug import transform
size = 224
# 图像解码
decode_op = DecodeImage()
# 图像随机裁剪
resize_op = ResizeImage(size=(size, size))
# 使用RandomErasing图像增广方法
randomerasing_op = RandomErasing()
ops = [decode_op, resize_op, tochw_op, randomerasing_op]
# 图像路径
imgs_dir = “/imgdir/xxx.jpg”
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)
img = img.transpose((1, 2, 0))

05
HideAndSeek
论文地址:
https://arxiv.org/pdf/1811.02545.pdf

from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import ToCHWImage
from ppcls.data.imaug import HideAndSeek
from ppcls.data.imaug import transform
size = 224
# 图像解码
decode_op = DecodeImage()
# 图像随机裁剪
resize_op = ResizeImage(size=(size, size))
# 使用HideAndSeek图像增广方法
hide_and_seek_op = HideAndSeek()
ops = [decode_op, resize_op, tochw_op, hide_and_seek_op]
# 图像路径
imgs_dir = “/imgdir/xxx.jpg”
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)
img = img.transpose((1, 2, 0))

06
GridMask
论文地址:
https://arxiv.org/abs/2001.04086
过度删除区域可能造成目标主体大部分甚至全部被删除,或者导致上下文信息的丢失,导致增广后的数据成为噪声数据; 保留过多的区域,对目标主体及上下文基本产生不了什么影响,失去增广的意义。

设置一个概率p,从训练开始就对图片以概率p使用GridMask进行增广。 一开始设置增广概率为0,随着迭代轮数增加,对训练图片进行GridMask增广的概率逐渐增大,最后变为p。
from data.imaug import DecodeImage
from data.imaug import ResizeImage
from data.imaug import ToCHWImage
from data.imaug import GridMask
from data.imaug import transform
size = 224
# 图像解码
decode_op = DecodeImage()
# 图像随机裁剪
resize_op = ResizeImage(size=(size, size))
# 图像数据的重排
tochw_op = ToCHWImage()
# 使用GridMask图像增广方法
gridmask_op = GridMask(d1=96, d2=224, rotate=1, ratio=0.6, mode=1, prob=0.8)
ops = [decode_op, resize_op, tochw_op, gridmask_op]
# 图像路径
imgs_dir = “/imgdir/xxx.jpg”
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)
img = img.transpose((1, 2, 0))

图像混叠
前文所述的图像变换与图像裁剪都是针对单幅图像进行的操作,而图像混叠是对两幅图像进行融合,生成一幅图像,Mixup和Cutmix两种方法的主要区别为混叠的方式不太一样。
07
Mixup
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import ToCHWImage
from ppcls.data.imaug import transform
from ppcls.data.imaug import MixupOperator
size = 224
# 图像解码
decode_op = DecodeImage()
# 图像随机裁剪
resize_op = ResizeImage(size=(size, size))
# 图像数据的重排
tochw_op = ToCHWImage()
# 使用HideAndSeek图像增广方法
hide_and_seek_op = HideAndSeek()
# 使用Mixup图像增广方法
mixup_op = MixupOperator()
ops = [decode_op, resize_op, tochw_op]
imgs_dir = “/imgdir/xxx.jpg” #图像路径
batch = []
fnames = os.listdir(imgs_dir)
for idx, f in enumerate(fnames):
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)
batch.append( (img, idx) ) # fake label
new_batch = mixup_op(batch)

08
Cutmix
论文地址:
https://arxiv.org/pdf/1905.04899v2.pdf
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import ToCHWImage
from ppcls.data.imaug import transform
from ppcls.data.imaug import CutmixOperator
size = 224
# 图像解码
decode_op = DecodeImage()
# 图像随机裁剪
resize_op = ResizeImage(size=(size, size))
# 图像数据的重排
tochw_op = ToCHWImage()
# 使用HideAndSeek图像增广方法
hide_and_seek_op = HideAndSeek()
# 使用Cutmix图像增广方法
cutmix_op = CutmixOperator()
ops = [decode_op, resize_op, tochw_op]
imgs_dir = “/imgdir/xxx.jpg” #图像路径
batch = []
fnames = os.listdir(imgs_dir)
for idx, f in enumerate(fnames):
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)
batch.append( (img, idx) ) # fake label
new_batch = cutmix_op(batch)

实验
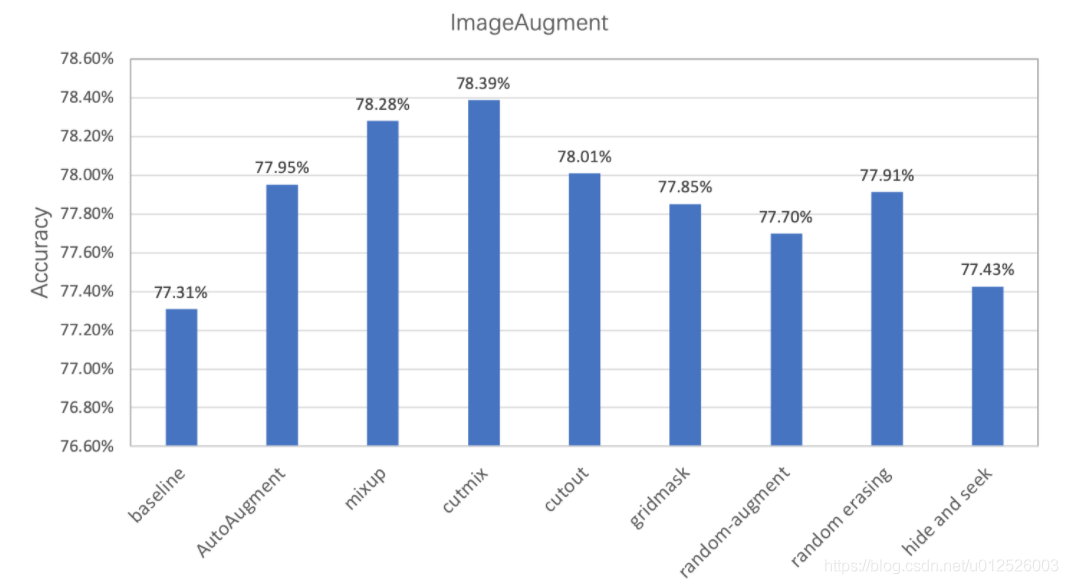
经过实验验证,在ImageNet1k数据集上基于PaddleClas使用不同数据增广方式的分类精度如下所示,可见通过数据增广方式可以有效提升模型的准确率。
PaddleClas数据增广避坑
指南以及部分注意事项
最后再为大家介绍几个PaddleClas数据增广使用方面的小Trick:
在使用图像混叠类的数据处理时,需要将配置文件中的use_mix设置为True,另外由于图像混叠时需对label进行混叠,无法计算训练数据的准确率,所以在训练过程中没有打印训练准确率。 在使用数据增广后,由于训练数据更难,所以训练损失函数可能较大,训练集的准确率相对较低,但其拥有更好的泛化能力,所以验证集的准确率相对较高。 在使用数据增广后,模型可能会趋于欠拟合状态,建议可以适当的调小l2_decay的值来获得更高的验证集准确率。 几乎每一类图像增广均含有超参数,PaddleClas在这里只提供了基于ImageNet-1k的超参数,其他数据集需要用户自己调试超参数,当然如果对于超参数的含义不太清楚的话,可以阅读相关的论文,调试方法也可以参考训练技巧的章节( https://github.com/PaddlePaddle/PaddleClas/blob/master/docs/zh_CN/models/Tricks.md)。



END
精彩赛事推荐
评论