计算机视觉:你必须了解的图像数据底层技术
点击上方“智能算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
转自|新机器视觉
引言
计算机视觉(Computer Vision)自兴起以来就非常迅速且广泛应用于各个领域,比如我们熟悉的且每天都会使用的基于手机摄像头的人脸识别,除此之外,它还可以在自动驾驶领域辅助汽车识别交通信号、标志和行人;在制造业辅助工业机器人监督和指导人工操作。

计算机视觉的主要目的是让计算机能像人类一样甚至比人类更好地看见和识别世界。计算机视觉通常使用C++、Python和MATLAB等编程语言,是增强现实(AR)的一项重要技术。目前主流的计算机视觉工具有OpenCV、Tensorflow、Gpu、YOLO、Keras等。计算机视觉其实是一个复杂多元的交叉领域,包含了很多来自数字信号处理、神经科学、图像处理、模式识别、机器学习(ML)、机器人、人工智能(AI)等领域的概念。

本文,小编想具体介绍一下计算机视觉的工作流程。
什么是计算机视觉(Computer Vision)
一言蔽之,计算机视觉是让计算机理解并标记图像内容的技术领域。
举个例子,请看下图:

对于人类来说,你很难向从没穿过衣服的原始人解释什么是连衣裙或者什么是鞋。计算机视觉也是如此,如果它并没有相关输入,就不会理解上图的东西都是什么。
所以,我们需要收集并标记大量关于衣服、鞋、包包的图片,输入进计算机“告诉”它这些图片里的东西是什么,在经过不断的学习和训练后,计算机将会识别出哪个是连衣裙,哪个是鞋、哪个是包包。
计算机视觉的主要应用
计算机视觉目前应用的领域不胜枚举,小编就挑出5个具有代表性的应用吧:
物体与行为识别
自动驾驶汽车
医疗影像分析与诊断
图片标记
人脸识别
计算机视觉工作流程
计算机视觉工作流程其实是大多数计算机视觉应用程序将经历的一系列步骤。许多视觉应用程序都是从获取图像和数据开始,然后处理数据,执行一些分析和识别步骤,最后执行一个动作的:
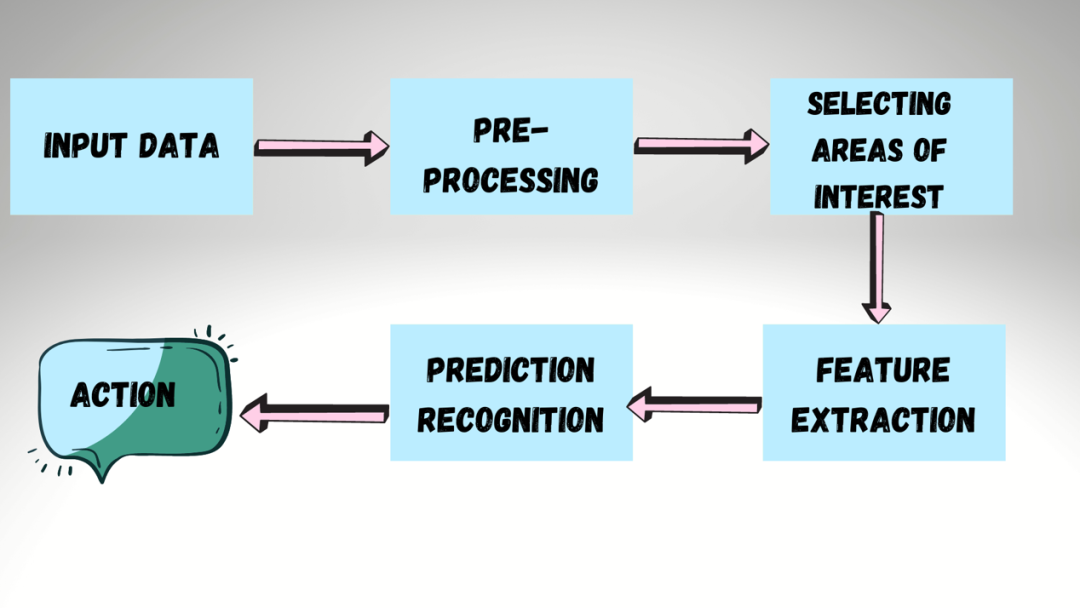
计算机视觉工作流程
就拿人脸识别来说吧,它也主要遵循了计算机视觉的工作流程:
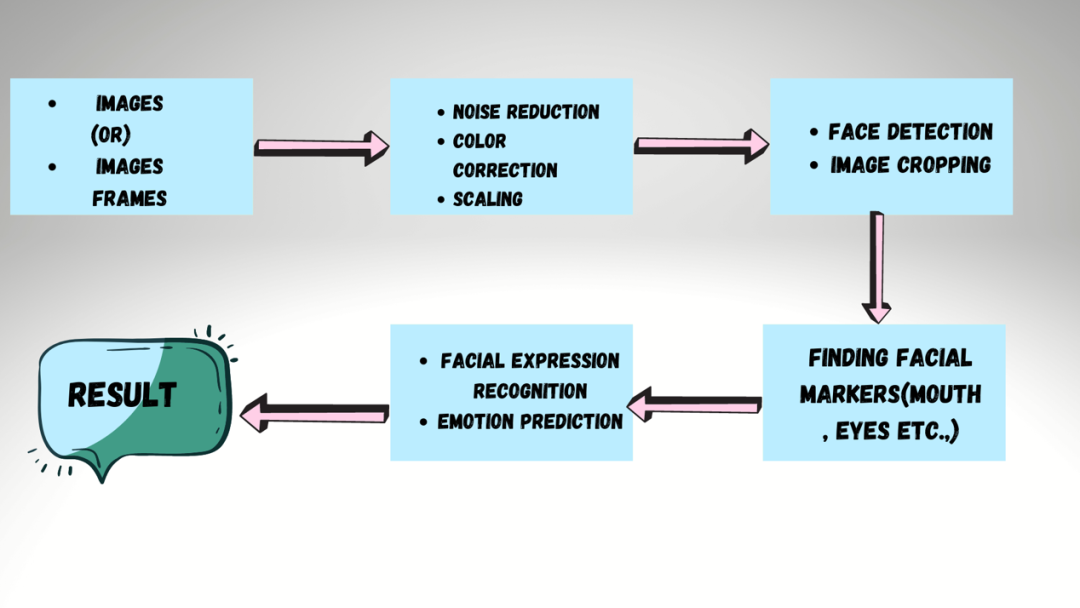
人脸识别工作流程
我们可以看到,大部分计算机视觉技术应用其实都是从数据预处理开始的,其实这也是机器学习的关键。
数据标准化
所谓预处理图像就是将输入的图像数据标准化,以便后续工作流程的顺利进行。例如,假设我们创建了一个简单的聚类算法来区分红玫瑰和其他花朵:

我们将算法设计为计算给定图像中红色像素的数量,如果有足够多的红色像素(大于300个红色像素)就被归类为红玫瑰。(这个例子里我们只提取了颜色特征)
还有一点需要注意的是,输入图像的大小、裁切方式都会影响算法的输出结果,因此数据预处理非常重要!
作为数据的图像
图像中的每一个像素都是一个我们可以改变的数值,比如,我们可以将一个像素乘以一个标量来改变图像亮度,我们也可以将每个像素值向右移动来改变图像饱和度等。
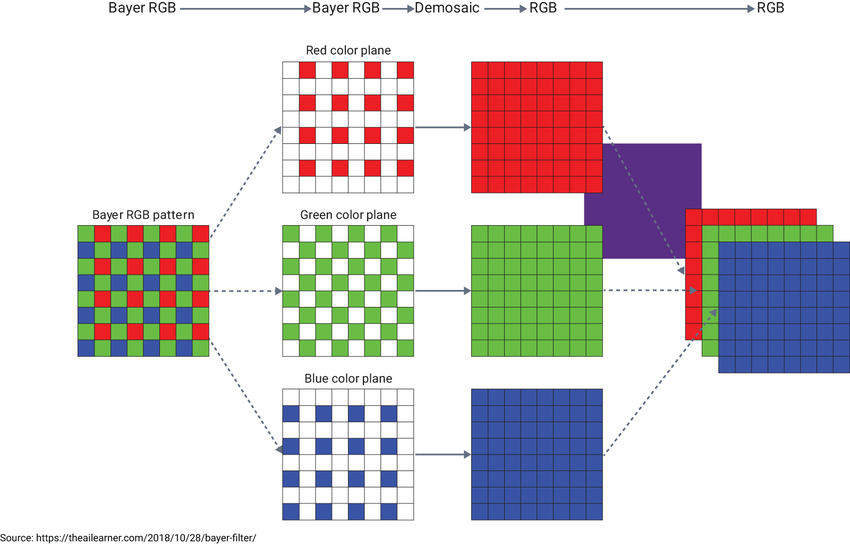
将图像视为数字网格是许多图像处理技术的基础。一般来说,色彩与形状改变都是通过数学运算对图像进行逐像素变换完成的。
训练神经网络
为了训练神经网络,我们要提供一组标记过的图像数据,然后比较这些输入图像与计算机预测的输出标签或识别的测量值的差异以检测算法模型的准确率。基于神经网络的深度学习会监督它所犯的错误(误差),并通过修正它发现的图像数据间的模式与差异来实现迭代与拟合。
其中,梯度下降法是一种减少神经网络误差的数学方法,其中卷积神经网络是一种特殊类型的神经网络,通常用于计算机视觉应用,在我们往期推文里有详细介绍~
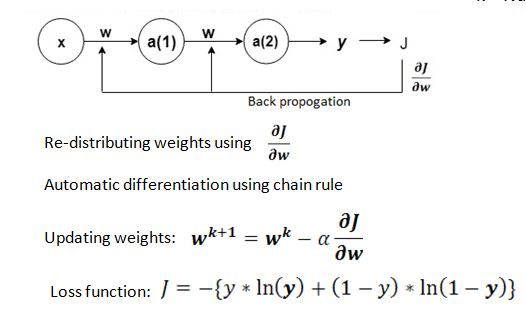
X =输入;a = 活化函数;W = 卷积神经网络中的权重;J = 损失函数;Alpha = 学习率;y = 地面真值;y = 预测;k = 迭代次数
来源:数艺学苑
参考文献
https://www.analyticsvidhya.com/blog/2020/11/computer-vision-a-key-concept-to-solve-many-problems-related-to-image-data/