
【机器学习】使用随机搜索进行超参数调整
作者 | Arindam Banerjee
编译 | Flin
来源 | analyticsvidhya

简介
超参数调整或优化在任何机器学习模型训练活动中都很重要。模型的超参数无法通过学习过程从给定的数据集中确定。但是,它们对于控制学习过程本身非常重要。这些超参数源自机器学习模型的数学公式。
例如,在训练线性回归模型时学习的权重是参数,但梯度下降中的学习率是超参数。模型在数据集上的性能很大程度上取决于所找到的模型超参数的最佳组合。
超参数优化有不同的技术,如网格搜索、随机搜索、贝叶斯优化等。今天我们将讨论随机搜索的方法和实现。数据科学家设置模型超参数来控制模型的实现方面。
一旦数据科学家确定了模型超参数的值,就可以将超参数视为模型设置。这些设置需要针对每个问题进行调整,因为一个数据集的最佳超参数不会是所有数据集的最佳超参数。
什么是随机搜索?

网格搜索和随机搜索是超参数调优中两种广泛使用的技术.
网格搜索彻底搜索指定的超参数值的每个组合。
与网格搜索相比,随机搜索从指定分布中抽取固定数量的参数设置。如果所有参数都以列表形式呈现,则执行无替换采样。如果至少一个参数作为分布给出,则使用替换抽样。可以预先指定如何在随机搜索中进行抽样。对于每个超参数,可以指定可能值的分布或离散值列表(要均匀采样)。对于具有连续值的超参数,应指定连续分布以充分利用随机化。
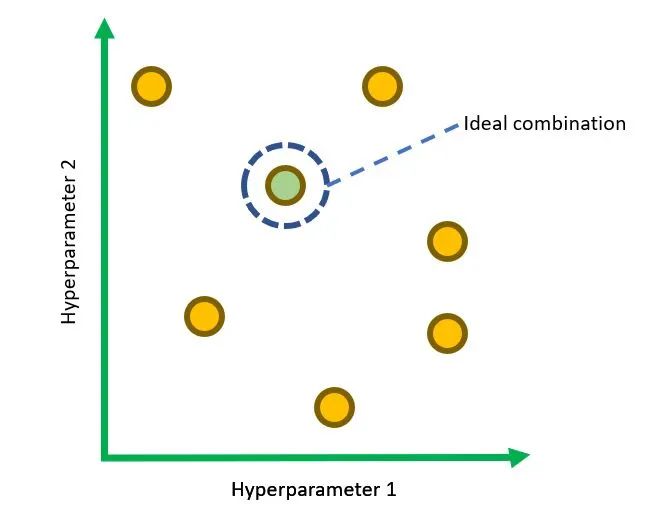
用于调整两个超参数的随机搜索空间示例
Python 实现
让我们看看基于 Python 的随机搜索实现。scikit-learn 模块附带了一些流行的参考数据集,包括轻松加载和获取它们的方法。我们将使用乳腺癌数据集进行二元分类。乳腺癌数据集是一个经典且直接的二元分类数据集。
数据集:https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_breast_cancer.html#sklearn.datasets.load_breast_cancer
scikit-learn 的随机搜索实现称为 RandomizedSearchCV 函数。让我们看看这个函数的重要参数:
estimator:scikit-learn 模型类型的对象。
param_distributions:以参数名称作为键和分布或要搜索的参数列表的字典。
评分:一种评分策略,用于评估交叉验证模型在测试集上的性能。
n_iter:它指定随机尝试的组合数。选择太低的数字会降低我们找到最佳组合的机会。
选择太大的数字会增加处理时间。因此,它权衡了运行时间与解决方案的质量。cv:在Randomized Search CV中,“CV”代表交叉验证,也在优化过程中进行。交叉验证
是一种重采样方法,用于使用样本外数据块测试模型的泛化能力。我们可以通过该方法中的“cv”值来确定交叉验证拆分策略。
我们将使用load_breast_cancer方法加载乳腺癌数据集。如果return_X_y为真,则返回 (data, target)。
X, y = load_breast_cancer(return_X_y=True)
print(X.shape)
让我们使用train_test_split将数据集拆分为训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X, y)
我们将使用标准标量来预处理数据。你可以看到训练数据经过fit_transform,而测试数据仅经过transform。
ss = StandardScaler()
X_train_ss = ss.fit_transform(X_train)
X_test_ss = ss.transform(X_test)
首先,我们将使用没有随机搜索和超参数默认值的随机森林分类器。
clf = RandomForestClassifier()
clf.fit(X_train_ss, y_train)
y_pred = clf.predict(X_test_ss)
可以根据测试数据计算准确度分数,并且可以开发混淆矩阵:
confusion_matrix(y_test, y_pred), "Test data")
acc_rf = accuracy_score(y_test, y_pred)
print(acc_rf)
我们将使用带有随机搜索的随机森林分类器来找出超参数的最佳可能值。我们在这里调整了随机森林分类器的五个超参数:max_depth、max_features、min_samples_split、bootstrap 和criteria。随机搜索将搜索给定的超参数分布以找到最佳值。我们还将使用 3 折交叉验证方案(cv = 3)。
一旦训练数据拟合模型,就可以从最终结果中提取随机搜索的最佳参数。
param_dist = {"max_depth": [3, 5],
"max_features": sp_randint(1, 11),
"min_samples_split": sp_randint(2, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"]}
# build a classifier
clf = RandomForestClassifier(n_estimators=50)
# Randomized search
random_search = RandomizedSearchCV(clf, param_distributions=param_dist,
n_iter=20, cv=5, iid=False)
random_search.fit(X_train_ss, y_train)
print(random_search.best_params_)

完整的 Python 代码:https://www.kaggle.com/arindambanerjee/randomized-search-simplified
结论
虽然 Grid Search 会检查超参数的每个组合,但当我们需要处理大型数据集时,它的表现不佳。在大数据集上尝试所有超参数组合是一项乏味的工作。如果一个模型有 m 个超参数,并且每个超参数如果我们测试 n 个值,那么 Grid Search 会检查mxn组合。
在随机搜索中,假设并非所有超参数都同等重要。每次迭代都会对超参数的随机组合进行采样,找到好的组合的机会更高。
这篇文章的主要内容是:
在机器学习中,超参数优化至关重要,这样模型才能在给定的数据集上进行最佳训练。这些不是通过学习过程学到的。
随机搜索比网格搜索提供更少的处理时间。
在随机搜索中,从指定分布中抽取固定数量的参数设置。
Python scikit-learn 库在其RandomizedSearchCV函数中实现了随机搜索。这个函数需要和它的参数一起使用,例如estimator、param_distributions、scoring、n_iter、cv等。
随机搜索比网格搜索更快。但是,我们需要在减少处理时间和找到最佳组合之间权衡。随机搜索方法可能无法保证找到超参数的最佳组合。
参考
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html
https://en.wikipedia.org/wiki/Hyperparameter_optimization
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码