
大模型时代目标检测任务会走向何方?
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达

导读
细数从常见的目标检测到现在 MLLM 盛行的时代,和 Object Detection 的任务以及近期涌现的新任务。
你或许很好奇,现在目标检测都在干啥?在大模型时代有啥花样可以做的?作为研究者还有啥可以挖的吗?作为从业者有没有好的东西可以借鉴?
如果你有这些疑问,那么这篇文章很适合你。
其实这篇文章是想说明下从我们常见的目标检测到现在 MLLM 盛行的时代,和 Object Detection 任务有哪些?目前又涌现了哪些新的任务?是否有很大的实际价值?希望能够打开下大家思路!!!
1 Object Detection
经典目标检测大家应该非常熟悉了,一般指的就是闭集固定类别的检测。

2 Open Set/Open World/OOD
这个任务是指在实际应用上可以检测任何前景物体,但是有些不需要预测类别,只要检测出框就行。在很多场合也有应用场景,有点像类无关的增量训练。

unknown 就是模型预测的不知道类别的检测结果。
3 Open Vocabulary
也是开放集任务,相比于 open set,需要知道不在训练集类别中的新预测物体类别。这类模型通常都需要接入文本作为一个模态输入,因为开放词汇目标检测的定义就是给定任意词汇都可以检测出来。
训练时候通常是要确保训练集和测试集的类别不能重复,否则就是信息泄露了,但是训练和测试集图片是否重复其实也没有强制限制。

可以看出 OVD 任务更加贴合实际应用,文本的描述不会有很大限制,同一个物体你可以采用多种词汇描述都可以检测出来。OVD 任务是一个比较实用的,但是目前还没有出现开源的超级强的 OVD 算法(这个超强是指的对比 SAM 来说,极强的 open 检测能力)
4 Phrase Grounding
这个任务也叫做 phrase localization。给定名词短语,输出对应的单个或多个物体检测框。如果是输入一句话,那么就是定位这句话中包括的所有名词短语。在 GLIP 得到了深入的研究。

从上图可以看出,Phrase Grounding 任务是包括了 OVD 任务的。常见的评估数据集是 Flickr30k Entities

5 Referring Expression Comprehension
简称 REC,有时候也称为 visual grounding。给定图片和一句话,输出对应的物体坐标,通常就是单个检测框。

常用的是 RefCOCO/RefCOCO+/RefCOCOg 三个数据集。是相对比较简单的数据集。这个任务侧重理解。
6 Description Object Detection

描述性目标检测也可以称为广义 Referring Expression Comprehension。为何叫做广义,这就要说道目前常用的
Referring Expression Comprehension 存在的问题了:
-
REC 数据集通常都是指代一个物体,不太符合实际
-
REC 数据集没有负样本,也就是每句话一定对应了图片中的物体,这样训练的模型会存在很大的幻觉
-
REC 数据集通常都是正向描述,例如上图的一条在图片左边的狗,但是没有反向描述,例如一条没有被绳子牵引着在外面的狗
基于此,Described Object Detection 论文提出了这个新的数据集,命名为 DOD。类似还有 gRefCOCO
其实还有一个更细致的任务叫做 :Open-Vocabulary Visual Grounding 和 Open-Vocabulary Phrase Grounding,来自论文 OV-VG

可以看出这个任务重点是想特意区分类别泄露问题,但是由于大数据集训练时代,这个情况是无法避免的。
7 Caption with Grounding
这个任务的含义是:给定图片,要求模型输出图片描述,同时对于其中的短语都要给出对应的 bbox

有点像 Phrase Grounding 的反向过程。这个任务可以方便将输出的名称和 bbox 联系起来,方便后续任务的进行。
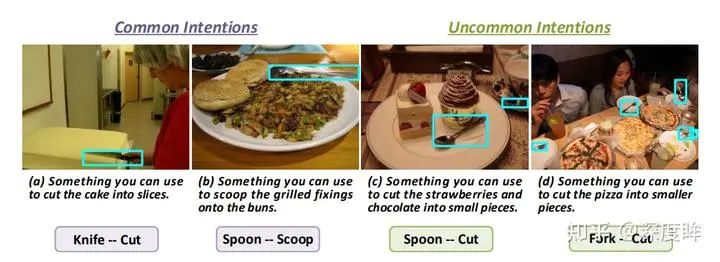
8 Reasoning Intention-Oriented Object Detection
意图导向的目标检测,和之前的 DetGPT 提出的推理式检测,我感觉非常类似。
DetGPT 中的推理式检测含义是:给定文本描述,模型要能够进行推理,得到用户真实意图。

例如 我想喝冷饮,LLM 会自动进行推理解析输出 冰箱 这个单词,从而可以通过 Grounding 目标检测算法把冰箱检测出来。模型具备推理功能。
而 RIO 我觉得也是一样,来自论文 RIO: A Benchmark for Reasoning Intention-Oriented Objects in Open Environments,想做的事情也是一样

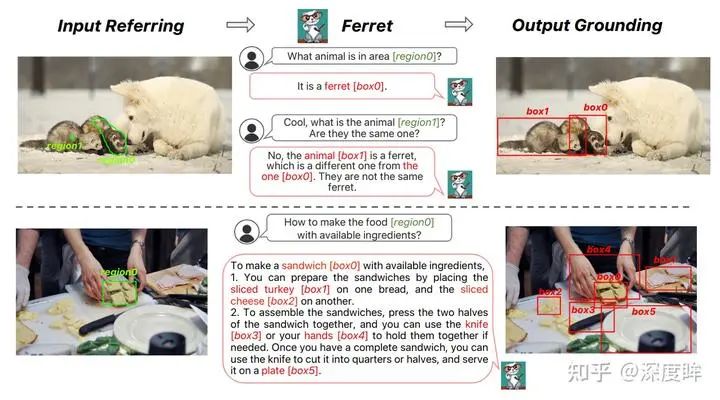
9 基于区域输入的理解和 Grounding
这个是一个非常宽泛的任务,表示不仅可以输入图文模态,还可以输入其他任意你能想到的模态,然后进行理解或者定位相关任务。
最经典的任务是 Referring expression generation:给定图片和单个区域,对该区域进行描述。常用的评估数据集是 RefCOCOg
现在也有很多新的做法,典型的如 Shikra 里面提到的 Referential dialogue,包括 REC,REG,PointQA,Image Caption 以及 VQA 5 个任务

Apple 也提出了新的可交互的设计
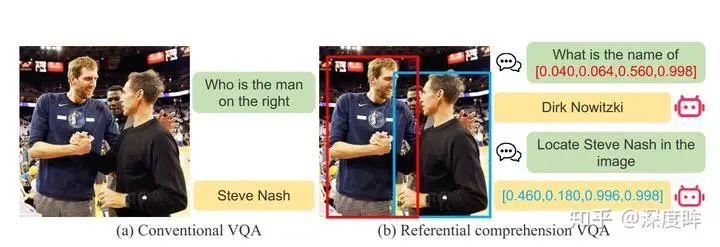
其实文本、bbox 和图片配合,还可以实现很多任务,但是由于都是比较特殊或者不是很主流,这里就没有写了。
10 结尾
可能还漏掉了一些,欢迎大家留言评论。后续可以讲讲这些任务应该如何解决?每个任务到底是咋评测的,通常的做法是咋样的。
现在都是大数据训练时代,评测虽然非常有用,但是很难避免数据泄露问题,如果作者不开源,你根本无法知道到底是模型性能还是数据泄露,这个一个值得思考的问题...,而这个问题也很难解,因为作者不开源,你也没有精力去做复现...
由于我们也没有做过工业,不知道大家认为哪个任务才是大家真正需要的?或者说这些任务还不够还可以扩展以满足实际需求,欢迎留言和交流!!!
声明:部分内容来源于网络,仅供读者学习、交流之目的。文章版权归原作者所有。如有不妥,请联系删除。