来源:知乎
编辑:好困 小咸鱼
【新智元导读】近日,又有一起学术不端行为被网友举报,作者竟是复旦大学重点实验室的研究生?相比于此前内容的一比一复刻,这次则是对9年前顶会论文来了一个「英译中」。
于2017年发表在期刊《计算机应用与软件》上的《基于正则表达式构建学习的网页信息抽取方法》。于2008年发表在自然语言处理顶会EMNLP上《Regular Expression Learning for Information Extraction》。
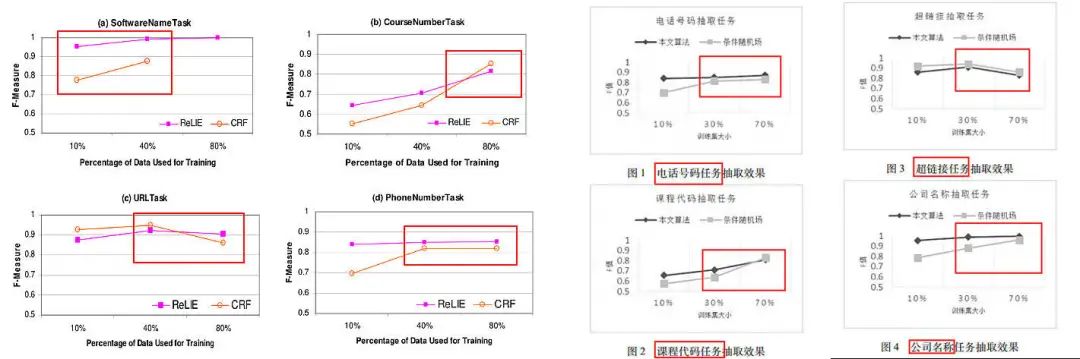
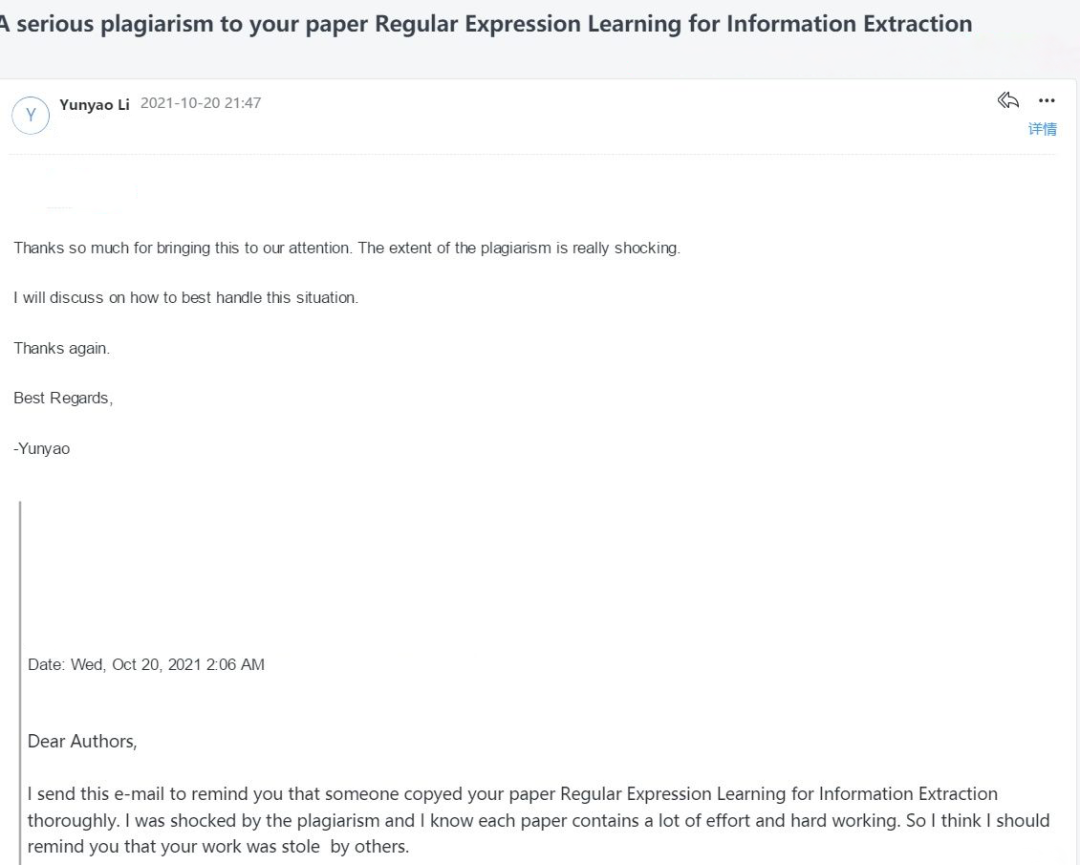
下面,我们将会为大家演示,如何「翻译」一篇英语文献并在之后进行发表。https://aclanthology.org/D08-1003.pdfhttp://www.shcas.net/jsjyup/pdf/2017/2/基于正则表达式构建学习的网页信息抽取方法.pdf通看全文,中文论文的行文逻辑和英文原版几乎完全一致。「正则表达式」是「信息抽取」的「常用方法」。「高质量且复杂的正则表达式」需要「人工成本」,为此,提出「...算法」。引言部分更夸张一些,几乎所有的关键词都被直接挪用了过去。至少在之前的摘要部分还是做了相当一部分「原创」的。如果说之前只是语言上的相似,那么接下来在第二章「2 The Regex Learning Problem (正则学习问题)」和「2 问题描述」中,内容重复之多,可以说就是「一字不差」地照搬了。首先,在问题的定义和变量的设置上,都是构造「正负」例子匹配结果的两个集合。在问题的阐述中,都提到了一个假设和三个定义,且关键处内容高度相似,仅仅更换了个别字母的使用。原作者提出的算法「ReLIE 」和中文稿的「正则表达式构建学习算法」从算法的变量定义,到执行的语法结构也完全一样。实验结果也是大差不差,下图左边原文在四个任务(SoftwareName、CourseNumber、 URL 和 PhoneNumber )上进行正则表达式的抽取,右边中文论文也在四个任务(电话号码、课程代码、超链接任务和公司名称)上抽取,实验所用的任务名称完全一样,实验图的走势也高度接近。比如,对目标函数的定义(中文论文第二个公式貌似还是错的。。。):而网上的传言也越来越离谱,从一个CS教授为什么会看中文水刊,到这是要锤复旦的阴谋论。为此,在昨晚,事件的第一发现者再次发文表示,自己举报完全是出于对科研的敬畏,并附上了发给原作者举报抄袭的邮件截图。此外,也贴出了自己在2021年10月20日下午6点发的朋友圈。该网友表示,自己就是一名在国内读大学的大四本科生,目前在公司实习,因为业务上涉及使用正则表达式筛选数据。最开始在Google Scholar上找到了IBM的那篇工作,但是感觉有些晦涩难懂,于是就决定去中文网站搜索一下相关的信息,然后就找到了这篇疑似抄袭的论文。经过和引文论文的对比,发现果然是一模一样的。此外,网友表示,复旦大学是我国最好的大学之一,为科技、社会的发展,做出了不可估量的贡献。自己非常尊敬复旦大学每一位认真科研、学习的老师和同学。虽然自己并不是全职做科研的博士或者教授,但作为一个了解过科研艰辛的人,不能容许别人肆意窃取这样的成果。这位网友相信,即便这件事在中文学术上是微不足道的,但如果大家也能在发现抄袭之后就随手进行曝光和举报,我们的学术环境一定会越来越好。一早起来,知乎这一问题下面已经有了好多人的评论。他们都表示了对这个造假发现者和举报者的支持:最近的多起学术不端行为,给学术研究者一个大大的提醒,那就是科研工作者一定要求真,求实,对学术诚信要有敬畏之心,绝不能踏过红线,不要有侥幸心理,否则就是自毁前程。每位科研工作者在做好自己的工作时,也要懂得尊重他人的学术成果。同时,科研工作者既是论文的产出者,也要做学术诚信的监督者,这样,才能推动学术发展欣欣向荣。
参考资料:
https://www.zhihu.com/question/493606496/answer/2183263738
https://aclanthology.org/D08-1003/
http://www.shcas.net/jsjyup/pdf/2017/2/基于正则表达式构建学习的网页信息抽取方法.pdf