
DataOps、MLOps 和 AIOps,你要的是哪个Ops?| IDCF

来源:infoQ 作者:Merelda Wu 策划:田晓旭 原文链接:https://towardsdatascience.com/what-the-ops-are-you-talking-about-518b1b1a2694
如何在 DataOps、MLOps 和 AIOps 之间进行选择?大数据团队应该采取哪种 Ops?
至少我们是这么认为的。
这在当时对我们来说是不可思议的,因为我们的数据科学家就坐在数据工程师的旁边。我们遵循了所有好的敏捷实践——每天开站会,讨论阻碍我们的因素,并没有那种“隔墙扔砖”的状态。我们密切合作,我们的科学家和工程师彼此相爱。但进展很缓慢,团队成员很沮丧。
过了两年,我终于理解了 DevOps 的真正含义。它在数据团队中是如此的相同,又是如此的不同。
在讨论以数据为中心的 Ops 之前,让我们先从软件开始。它们有太多的相似之处和对比了,请耐心听我说……
DevOps 与其说是一项工作职能,不如说是一种实践或文化。在构建任何软件时都应该采用它。
“以最低的错误率,尽可能快的速度交付软件”。

一、DataOps vs MLOps vs DevOps(以及 AIOps?)

注:在本文中,分析团队是指使用 SQL/PowerBI 来生成业务洞察力的传统 BI 团队。AI 团队是指使用大数据技术构建高级分析和机器学习模型的团队。有时他们是同一个团队,但我们会将他们分开,这样能更容易地解释相应概念。
通过客户与软件程序的交互产生数据。 软件将数据存储在应用程序的数据库中。 分析团队根据这些来自不同团队的应用程序数据库构建 ETL。 分析团队为业务用户构建报表和仪表盘,以协助他们做出以数据为驱动的决策。 然后,数据工程师将原始数据、合并了的数据集(来自分析团队)和其他非结构化的数据集整合到某种形式的数据湖中。 然后,数据科学家利用这些海量的数据集建立模型。 然后,这些模型利用用户生成的新数据进行预测。 然后,软件工程师将预测结果呈现给用户。 这样的循环不断进行下去……
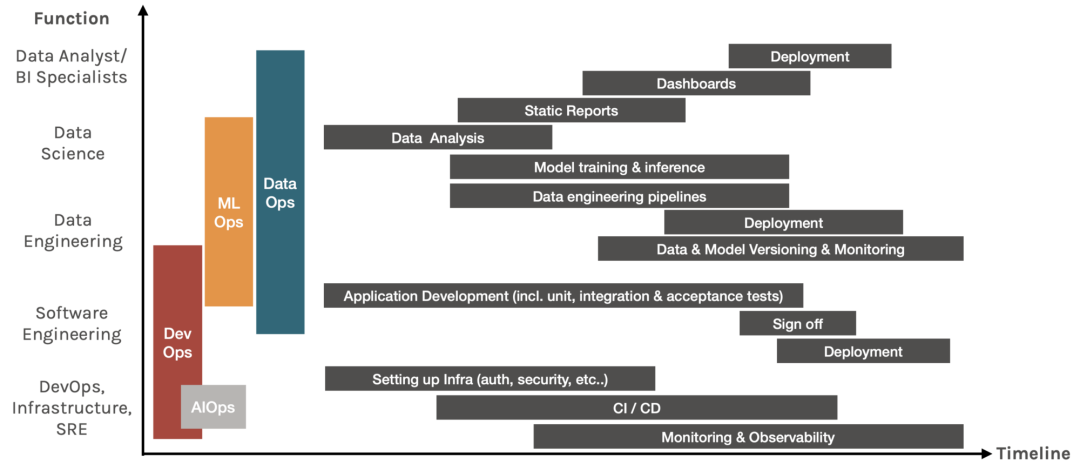
DevOps 更快地交付软件
DataOps 更快地交付数据
MLOps 更快地交付机器学习模型
附加:AIOps 利用 AI 的功能增强了 DevOps 工具
AIOps 平台利用大数据、现代机器学习以及其他先进的分析技术,直接或间接地增强 IT 运维(监控、自动化和服务台),具有前瞻性、个性化以及动态的洞察力。
二、是原则不是工作角色
DataOps、MLOps 和 DevOps 的实践必须是与语言、框架、平台和基础设施无关的。
第一个组件是触发事件,即触发器是数据科学家的手动触发器、日历计划事件和阈值触发器吗? 第二个组件是新模式的实际再培训。生成模型的脚本、数据和超参是什么?它们的版本以及它们之间的联系。 最后一个组件是模型的实际部署,它必须由具有预警功能的部署管道进行编排。
Awesome Machine Learning:https://github.com/josephmisiti/awesome-machine-learning Awesome Production Machine Learning:https://github.com/ethicalml/awesome-production-machine-learning
三、结论
培养跨学科技能:培养 T 型个人和团队(弥合差距,协调问责制)。 尽早实现自动化(足够):集中在一个技术栈上并实现自动化(减小工程过程的开销)。 以终为始:在解决方案设计上提前投资,以减少从 PoC 到生产的摩擦。

FDCC - Fundamental DevOps Capability Certification【基础认证-⽩腰带】,限时免认证费,回复“FDCC”即可申请。
评论