
BERT---容易被忽视的细节
来源:https://zhuanlan.zhihu.com/p/69351731
最近面试,被问到一些模型的相关细节,所以又重新读了一些论文
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文地址:https://arxiv.org/pdf/1810.04805.pdf
细节一:Bert的双向体现在什么地方?
Bert可以看作Transformer的encoder部分。Bert模型舍弃了GPT的attention mask。双向主要体现在Bert的
预训练任务一:遮蔽语言模型(MLM),如:
小 明 喜 欢 [MASK] 度 学 习 。
这句话输入到模型中,[MASK]通过attention均结合了左右上下文的信息,这体现了双向。
attention是双向的,但GPT通过attention mask达到单向,即:让[MASK]看不到 度 学 习这三个字,只看到上文 小 明 喜 欢 。
细节二:Bert的是怎样预训练的?
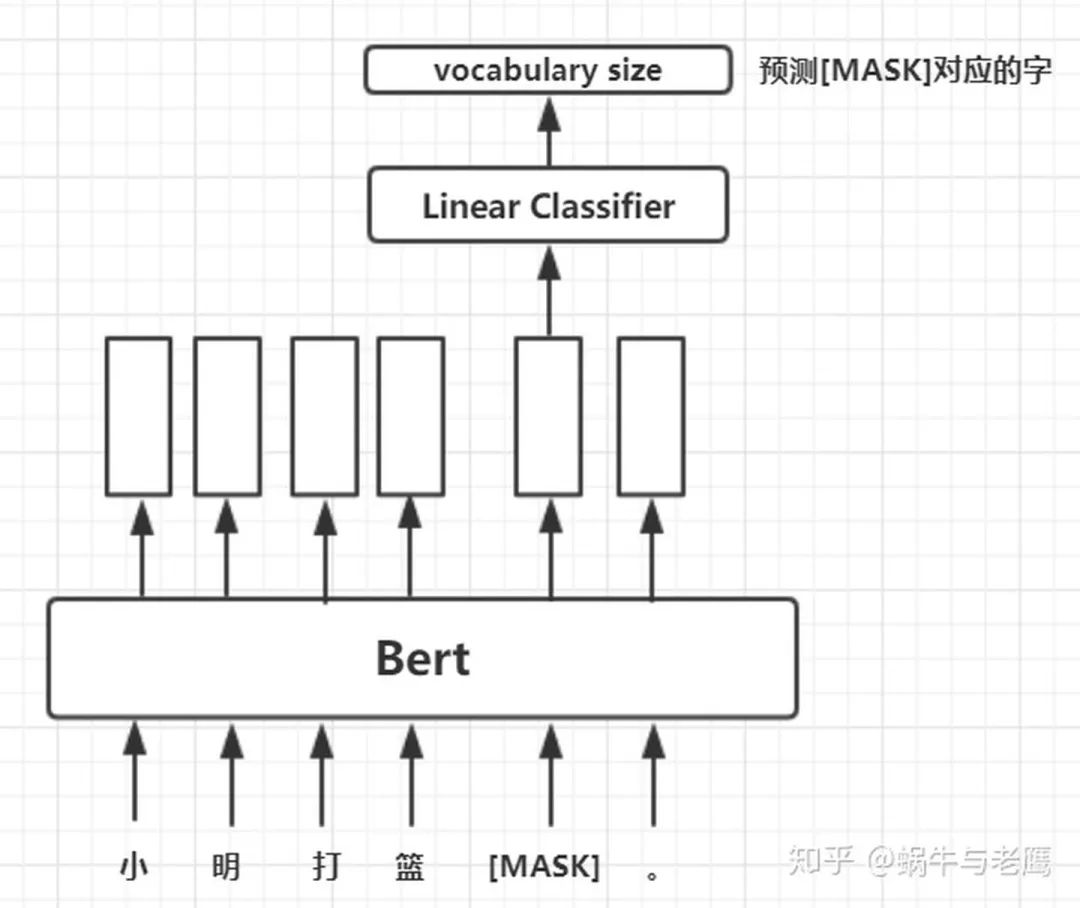
预训练任务一:遮蔽语言模型(MLM)
将一句被mask的句子输入Bert模型,对模型输出的矩阵中mask对应位置的向量做分类,标签就是被mask的字在字典中对应的下标。这么讲有点抽象,如图:
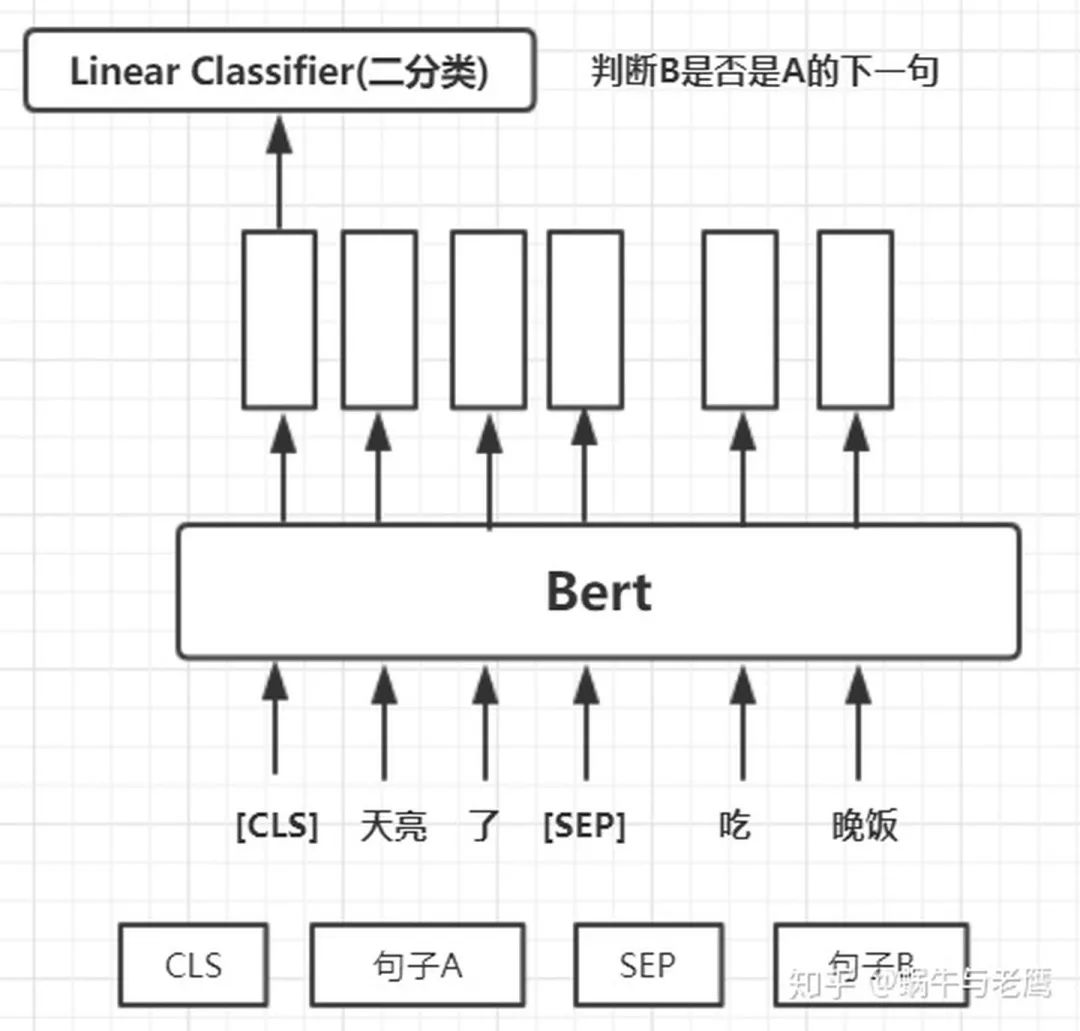
预训练任务二:下一句预测(NSP)
训练一个下一句预测的二元分类任务。
具体 来说,在为每个训练前的例子选择句子 A 和 B 时,50% 的情况下 B 是真的在 A 后面的下一个句子, 50% 的情况下是来自语料库的随机句子。
然后将[cls]对应的向量取出做二分类训练,如图:
两个任务共享Bert,使用不同的输出层,做Muti-Task。
细节三:对于任务一,对于在数据中随机选择 15% 的标记,其中80%被换位[mask],10%不变、10%随机替换其他单词,原因是什么?
两个缺点:
1、因为Bert用于下游任务微调时, [MASK] 标记不会出现,它只出现在预训练任务中。这就造成了预训练和微调之间的不匹配,微调不出现[MASK]这个标记,模型好像就没有了着力点、不知从哪入手。所以只将80%的替换为[mask],但这也只是缓解、不能解决。
2、相较于传统语言模型,Bert的每批次训练数据中只有 15% 的标记被预测,这导致模型需要更多的训练步骤来收敛。
··· END ···