
阿里妈妈搜索广告CTR模型的“瘦身”之路
▐ 前言
▐ 1. 超大规模模型演进之路的辩证思考
2)列维度:即Embedding向量维度压缩
3)值精度:即FP16/Int8量化等
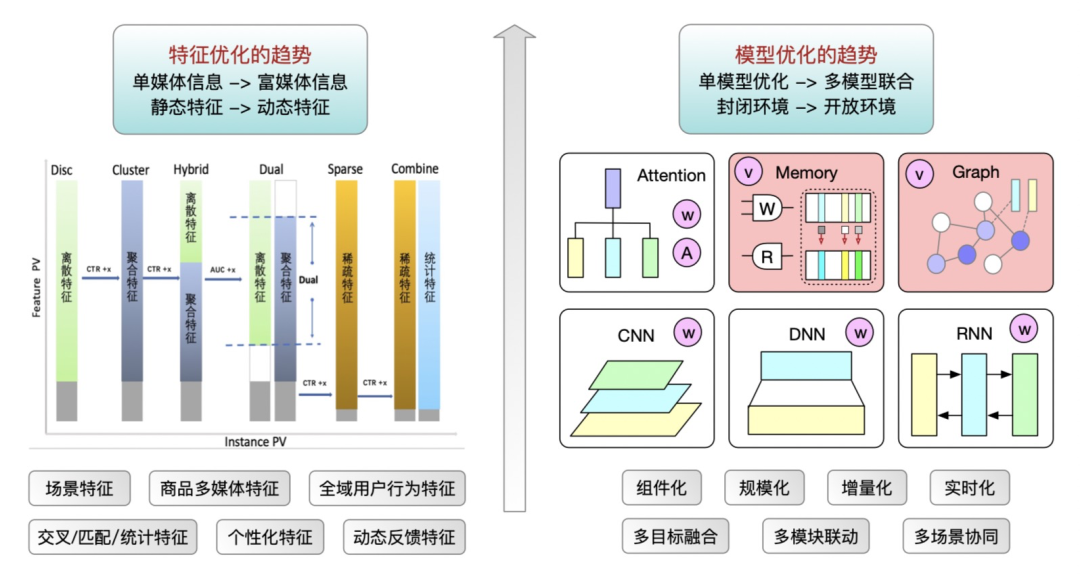
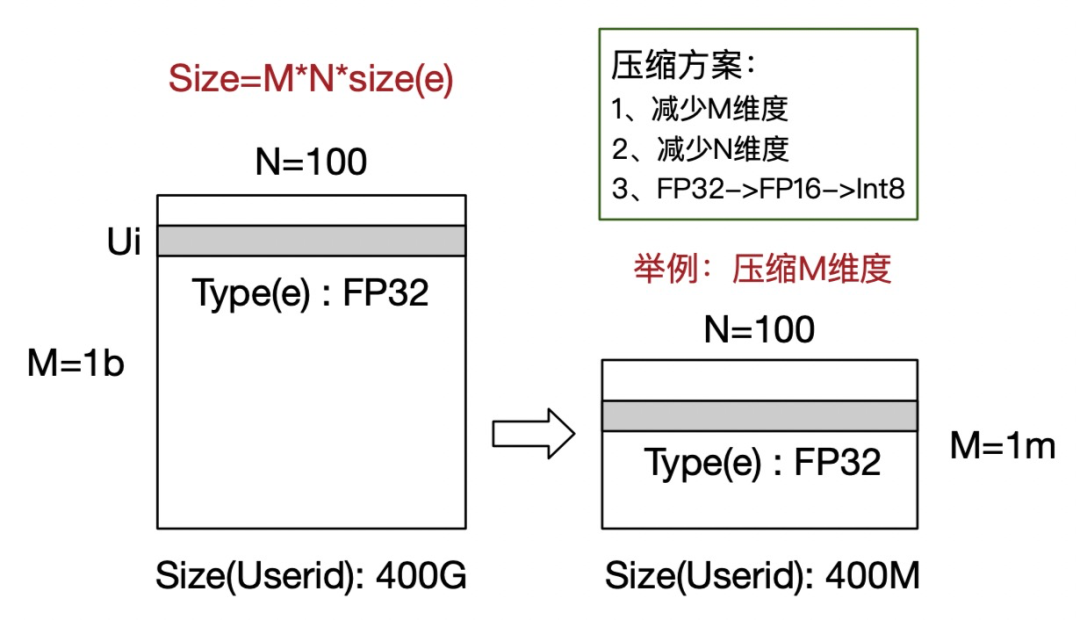
我们在这3个方向都有充分实践,本文主要介绍在行维度的特征压缩,也是在直通车场景可以做到训练过程中自压缩,模型压缩比有量级(其他两个优化方向只有倍数压缩比)上的显著收益且模型预估精度保持不变,下图举例说明。
▐ 2. 小而美模型的蜕变之路
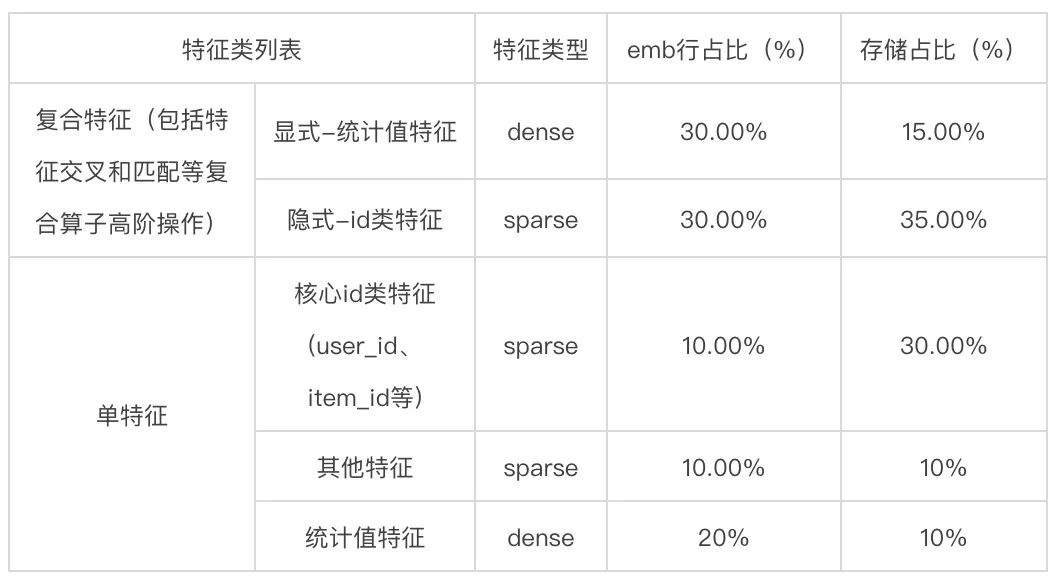
复合特征的隐式类型的id类特征,例如<user_age, item_id>交叉特征对应的 Embedding,这一类特征提供了更加微观的id类特征的表征方式,在样本规模较为充分的情况下能够提供更加细腻的特征空间区分能力,实践中效果较为显著。
复合特征的显式类型的统计值特征,例如<user_age, item_id>交叉特征的历史14天统计 CTR,这一类特征可以注入先验的数据分布,提供一定的泛化能力,在实践中效果较为明显。
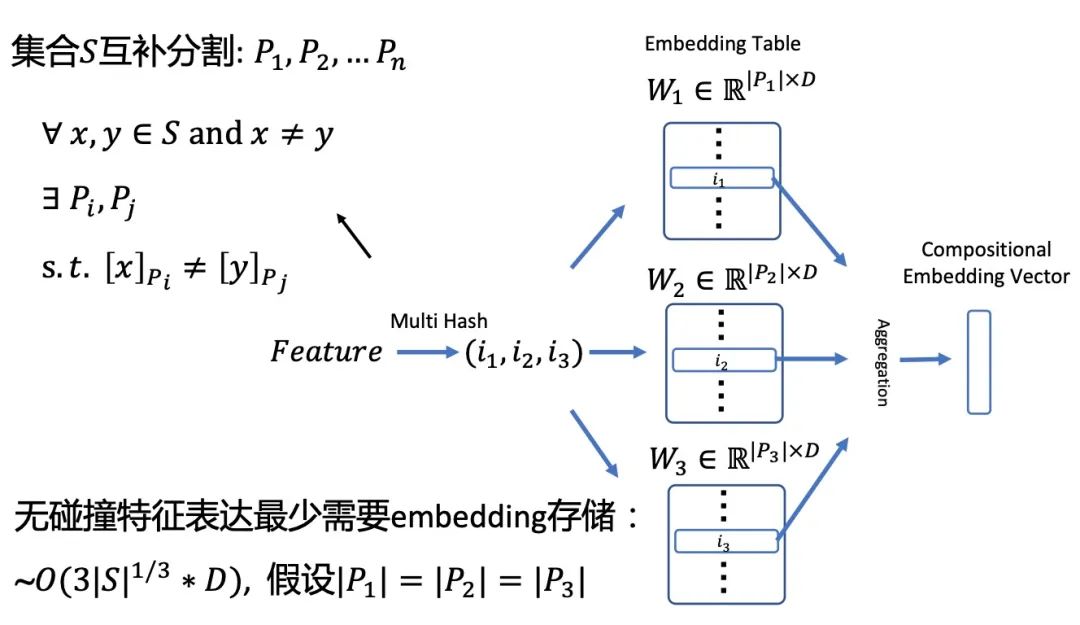
单特征的核心id类特征,例如query_id,item_id,user_id等,这一类特征是模型预估的基石,随着模型的演进我们也由有冲突 hash 升级到无冲突 hash 模式。虽然效果有提升,但为了控制住模型规模,系统需要配置相应的特征准入准出策略,当遇到数据分布变化剧烈的时期,例如季节变换或者大促时节,策略需要频繁调整,鲁棒性较低。
设计关系网络,取代复合特征的隐式类型的id类特征; 设计基于 Graph 的预训练网络,取代复合特征的显式类型的统计值特征; 设计 Multi-Hash 通用的压缩方案,升级单特征的核心id类特征; 设计随模型可学习的特征选择方案,确保整体特征结构的精简性,特征均有正向边际收益;
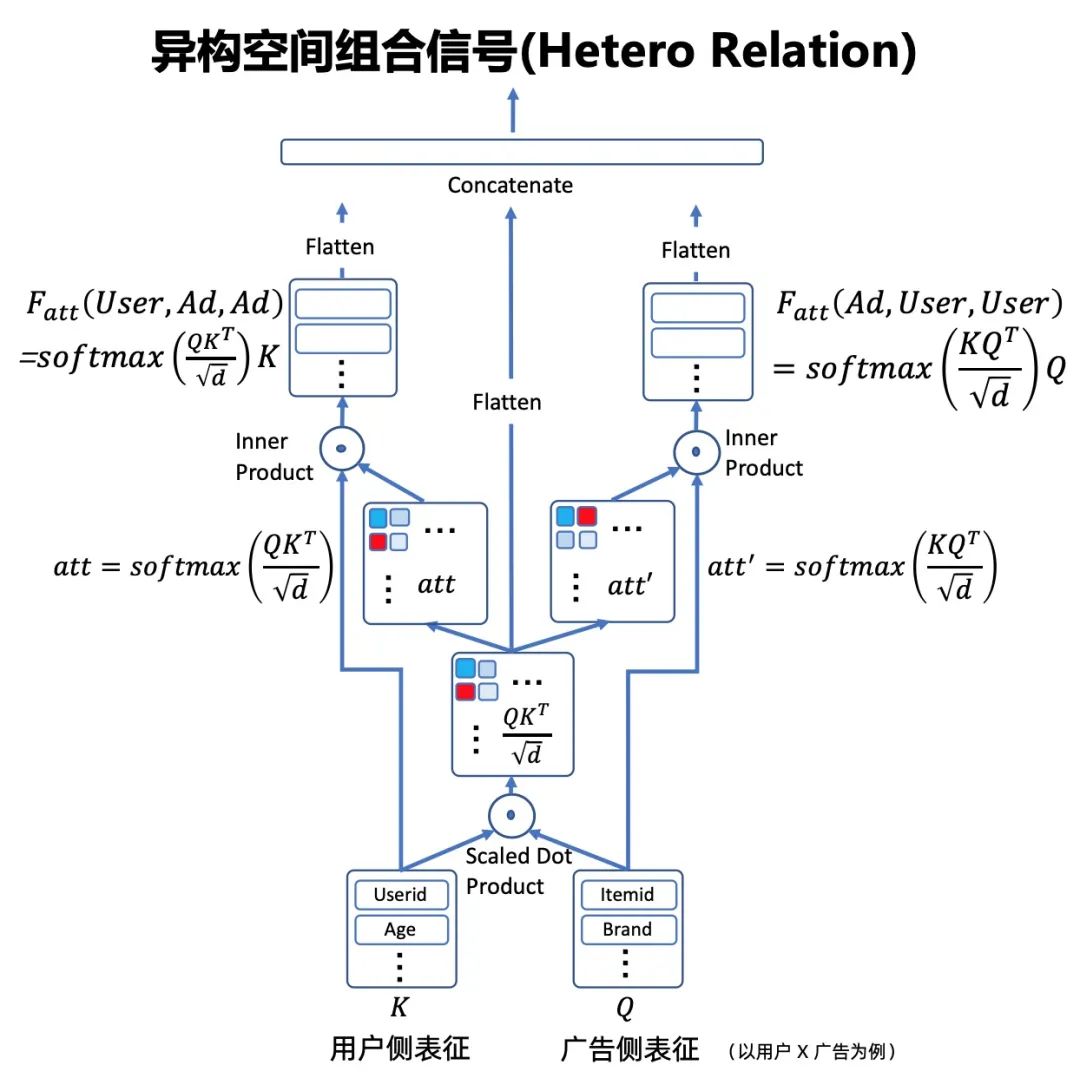
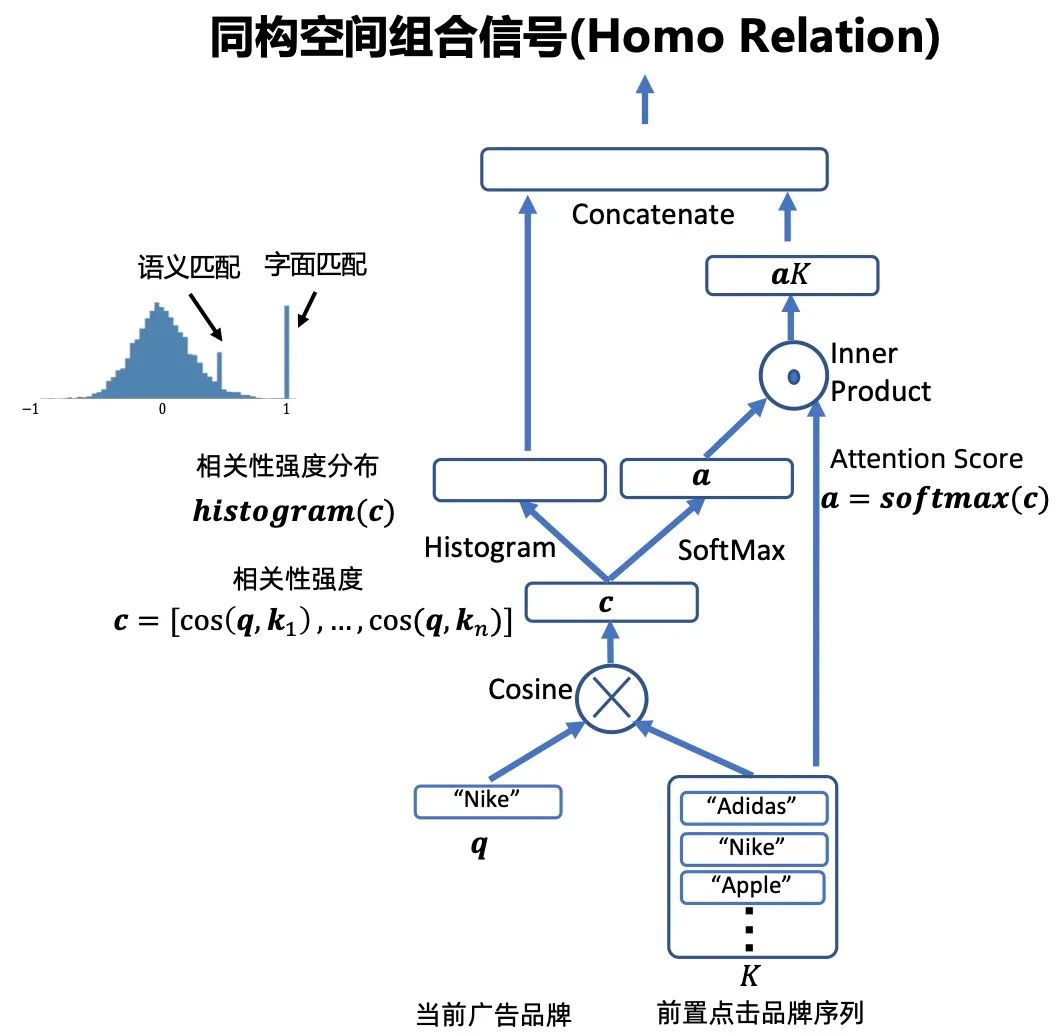
交叉特征的隐式 Embedding 表征是业界关注最多的话题,我们借鉴业界较为常用的特征交叉建模方案(例如 FM 系列,DCN[1],AutoInt[2]等),设计适配直通车场景的交叉网络。该网络的特点是参考 self-attention 结构,基于共享的交互强度矩阵,对称性地双视角建模两两特征的交叉关系。且根据实际情况,对交叉特征域做先验设定(只保留流量需求侧与供给侧交互关系),整体交叉网络作为 Deep 的一部分(实验表明 Wide 设计效果不佳),大块的矩阵线性计算也有利于 GPU 加速,整体很好地刻画了交叉特征的 Embedding 表征。
2.2. 基于 Graph 的预训练网络
复合特征除了上述提到的隐式类型以外,另一类就是显式的统计值,这类特征业务提效也非常明显,是业界提效公开的秘密手段,存储规模占比也不小,但是想做精简却无法像上述关系网络拟合一样来处理。举例来说,<user_age, item_id>交叉特征的 Embedding,可以通过单特征各自 user_age 的 Embedding 和 item_id 的 Embedding 计算得到,但是<user_age, item_id>交叉特征的 CTR,无法拆解成 user_age 的 CTR 和 item_id 的 CTR 交互计算。
2.4. Droprank 特征选择
▐ 3. 总结与展望