
3000字详解四种常用的缺失值处理方法
不论是自己爬虫获取的还是从公开数据源上获取的数据集,都不能保证数据集是完全准确的,难免会有一些缺失值。而以这样数据集为基础进行建模或者数据分析时,缺失值会对结果产生一定的影响,所以提前处理缺失值是十分必要的。
对于缺失值的处理大致可分为以下三方面:
不处理
删除含有缺失值的样本
填充缺失值
不处理应该是效果最差的了,删除虽然可以有效处理缺失值,但是会损伤数据集,好不容易统计的数据因为一个特征的缺失说删就删实在说不过去。填充缺失值应该是最常用且有效的处理方式了,下面介绍四种处理缺失值的常用Tips。
我自己构建了一个简易的含有缺失值的DataFrame,所有操作都基于这个数据集进行。
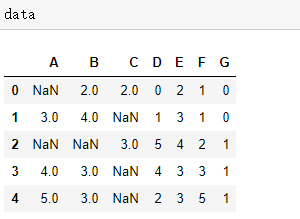
1、删除缺失值
删除虽说是一个可行的方式,但肯定是不能随便删除的,比如一个样本中仅有一个特征的值缺失,这样的情况下填充取得的效果一定会优于删除,所以在删除缺失值时,我们需要一个衡量的标准。
删除的方式无非有两种,一是删除缺失值所在行,也就是含有缺失值的样本;二就是删除缺失值所在列,也就是含有缺失值的特征,下面以后者为例。
首先需要确定的是删除的标准是什么?比如一个特征的缺失值所占比例已经超过了50%,如果选择填充的话,就表明该特征超五成的值都是自己猜测填入的,导致误差可能比删除这个特征还要大。
def find_missing(data):
#统计缺失值个数
missing_num = data.isna().sum(axis=0).sort_values(ascending=False)
missing_prop = missing_num/float(len(data)) #计算缺失值比例
drop_index = missing_prop[missing_prop>0.5].index.tolist() #过滤要删除特征名
return drop_index
在确定了这个标准之后,就可以利用一个自定义函数,将我们期望实现的功能封装至函数中。比如上面这个函数,先确定每个特征的缺失值个数并降序排列,然后计算缺失值比例,最后利用布尔索引得到需要删除的特征名。
data2 = data.copy()
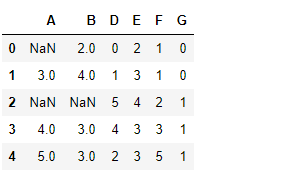
data2.drop(find_missing(data2),axis = 1)
在数据集上应用这个函数,可以看到缺失值占比超50%的特征C被删除了。
这个衡量标准自己可以依据情况设定,然后删除样本的方式可以类比上述删除特征的方式。
2、pandas填充
pandas中的fillna()应该是最常用的一种填充缺失值方法,可以指定填充指定列或者整个数据集。
data['A'].fillna(value = data['A'].mean(),limit=1)
比如上面这句代码,就是只填充特征A一列,填充的选择可以利用平均数、中位数、众数等等,limit是限制要填充的个数,如果有两个缺失值,但是参数limit=1的话,按顺序填充第一个。

value参数也允许传入字典格式,键为要填充的特征名,值为要填充的缺失值。
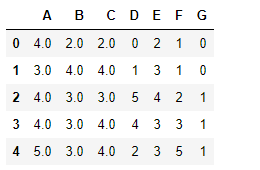
values = {'A':4,'B':3,'C':4}
data.fillna(value=values)
填充之后结果如下:
fillna()方法固然简单,但前提是含有缺失值的特征比较少,如果很多的话,代码就会很冗杂,客观性也比较差。
3、sklearn填充
第二种填充方式是利用sklearn中自带的API进行填充。
from sklearn.impute import SimpleImputer
data1 = data.copy()
#得到含有缺失值的特征
miss_index = data1.isna().any()[data1.isna().any().values == True].index.tolist()
print(miss_index)
'''
['A', 'B', 'C']
'''
首先利用布尔索引得到数据集含有缺失值的特征,后续操作只针对含有缺失值的特征。
miss_list = []
for i in miss_index:
#将一维数组转化为二维
miss_list.append(data1[i].values.reshape(-1,1))
for i in range(len(miss_list)):
#利用众数进行填充
imp_most = SimpleImputer(strategy='most_frequent')
imp_most = imp_most.fit_transform(miss_list[i])
data1.loc[:,miss_index[i]] = imp_most
最需要注意的一点是SimpleImputer传入的参数至少要是二维,如果将直接索引出的一列特征传入的话,是会发生报错的,所以必须利用reshape()将一维转化为二维。之后的操作就是先实例化、然后训练模型,最后用填充后的数据覆盖之前的数据。
参数strategy共有四个选项可填:
1、mean:平均数
2、median:中位数
3、most_frequent:众数
4、constant:如果参数指定这个,将会选择另一个参数fill_value中的值作为填充值。
SimpleImputer优于fillna()之处在于前者可以一行语句指定填充值的形式,而利用fillna()需要多行重复语句才能实现,或者需要提前计算某列的平均值、中位数或者众数。
4、利用算法填充
我们都知道一般的算法建模是通过n个特征来预测标签变量,也就是说特征与标签标量之间存在某种关系,那么通过标签变量与(n-1)个特征是否能预测出剩下的一个特征呢?答案肯定是可以的。
实际上标签变量和特征之间可以相互转化,所以利用这种方法就可以填补特征矩阵中含有缺失值的特征,尤其适用于一个特征缺失值很多,其余特征数据很完整,特别标签变量那一列的数据要完整。
但是往往一个特征矩阵中很多特征都含有缺失值,对于这种情况,可以从特征缺失值最少的一个开始,因为缺失值越少的特征需要的信息也就越少。
当预测一个特征时,其余特征的缺失值都需要用0暂时填补,每当预测完一列特征,就用预测出的结果代替原数据集对应的特征,然后预测下一特征,直至最后一个含有缺失值的特征,此时特征矩阵中应该没有需要利用0填补的缺失值了,表示数据集已经完整。
以随机森林算法为例,实现上面表述填充缺失值的过程。
data3 = data.copy()
#获取含有缺失值的特征
miss_index = data3.isna().any()[data3.isna().any().values == True].index.tolist()
#按照缺失值多少,由小至大排序,并返回索引
sort_miss_index = np.argsort(data3[miss_index].isna().sum(axis = 0)).values
sort_miss_index
'''
array([1, 0, 2], dtype=int64)
'''
第一步就是通过布尔索引得到含有缺失值的特征,并且根据缺失值的多少进行由小到大排序,这里选择利用argsort,因为返回的排序是特征在特征矩阵中的索引。
for i in sort_miss_index:
data3_list = data3.columns.tolist() #特征名
data3_copy = data3.copy()
fillc = data3_copy.iloc[:,i] #需要填充缺失值的一列
# 从特征矩阵中删除这列,因为要根据已有信息预测这列
df = data3_copy.drop(data3_list[i],axis = 1)
#将已有信息的缺失值暂用0填补
df_0 = SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0).fit_transform(df)
Ytrain = fillc[fillc.notnull()]#训练集标签为填充列含有数据的一部分
Ytest = fillc[fillc.isnull()]#测试集标签为填充列含有缺失值的一部分
Xtrain = df_0[Ytrain.index,:]#通过索引获取Xtrain和Xtest
Xtest = df_0[Ytest.index,:]
rfc = RandomForestRegressor(n_estimators = 100)#实例化
rfc = rfc.fit(Xtrain,Ytrain) # 导入训练集进行训练
Ypredict = rfc.predict(Xtest) # 将Xtest传入predict方法中,得到预测结果
#获取原填充列中缺失值的索引
the_index = data3[data3.iloc[:,i].isnull()==True].index.tolist()
data3.iloc[the_index,i] = Ypredict# 将预测好的特征填充至原始特征矩阵中
这部分代码主要的思想就是,先将需预测的一列特征暂定为标签,然后预测列中含有数据的一部分作为训练集,含有缺失值的一部分作为测试集,通过随机森林在训练集上建模,利用模型在测试集的基础上得到缺失值那部分的数据,最后填充值原特征矩阵中。
最后预测出的结果如下:
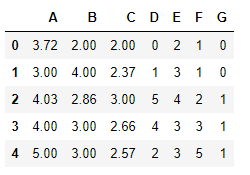
可以看到原特征矩阵中缺失值的一部分被填充好了,这种利用算法填充缺失值的方法应该是精度最高的,因为缺失值是在原有数据的基础上预测出的,而不是随意猜测的,但缺点就是没有前几种便利,当特征或缺失值较多时会比较耗时。
说在最后
缺失值处理是特征工程至关重要的一步,而特征工程和数据本身往往决定着一个模型的上限,所以数据集中的缺失值在一个项目中值得我们花些时间去处理,而不是用自己的幸运数字随意填充,一句话总结就是"你不要你觉得,而是模型觉得"。