
Flink on Zeppelin 系列之:Yarn Application 模式支持
作者:章剑锋(简锋)
去年 Flink Forward 在讲 Flink on Zeppelin 这个项目的未来时我们谈到了对Application 模式的支持,今天就有一个好消息要告诉大家,社区已经实现了这一Feature,欢迎大家加入 Flink on Zeppelin 的钉钉群(32803524),下载最新版来使用这个Feature。
 GitHub 地址
GitHub 地址 一、架构
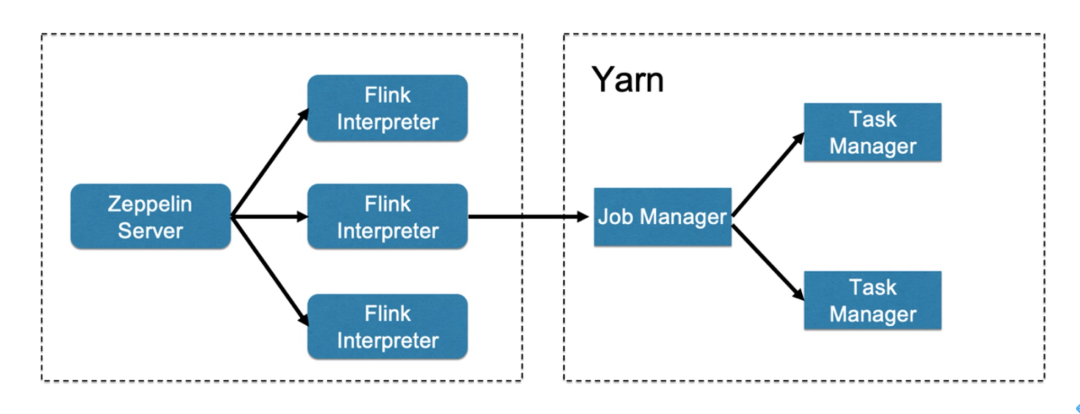
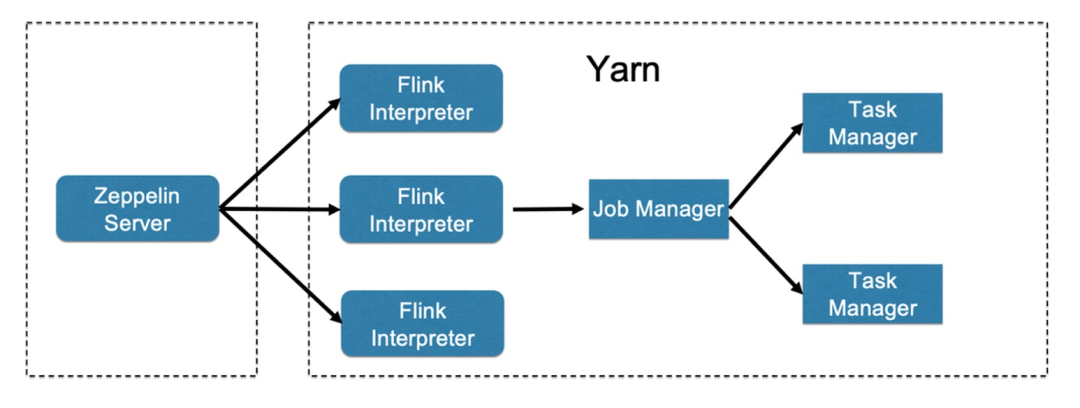
参考文档: https://www.yuque.com/jeffzhangjianfeng/gldg8w/wt1g3h 参考视频: https://www.bilibili.com/video/BV1Te411W73b?p=6
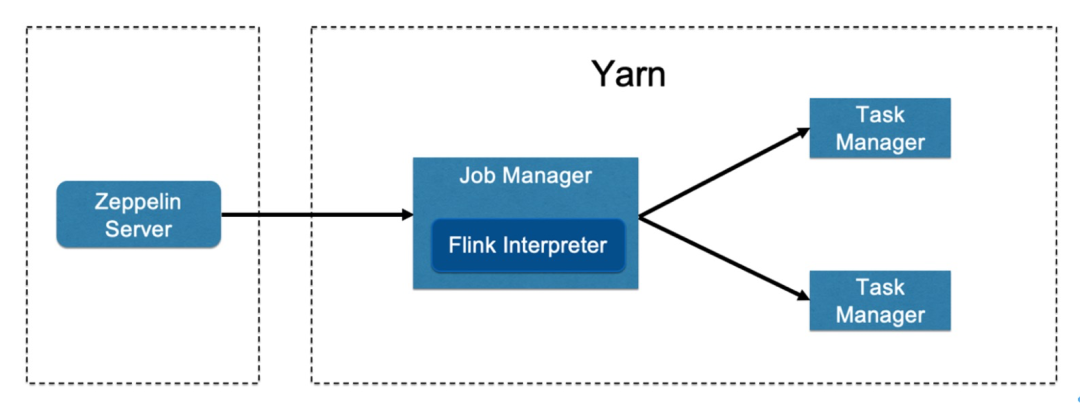
参考文档: https://www.yuque.com/jeffzhangjianfeng/gldg8w/gcah8t 参考视频: https://www.bilibili.com/video/BV1Te411W73b?p=24
二、如何使用 Yarn Application 模式
Scala (%flink)
PyFlink (%flink.pyflink)
SQL (%flink.ssql, %flink.bsql)
参考文档: https://www.yuque.com/jeffzhangjianfeng/gldg8w/pg5s82 https://www.yuque.com/jeffzhangjianfeng/gldg8w/ggxz76 https://www.yuque.com/jeffzhangjianfeng/gldg8w/te2l1c 参考视频: https://www.bilibili.com/video/BV1Te411W73b?p=4
参考文档: https://www.yuque.com/jeffzhangjianfeng/gldg8w/agf94n 参考视频: https://www.bilibili.com/video/BV1Te411W73b?p=10
在 Zeppelin 中直接写 Scala UDF;
在 Zeppelin 中直接写 PyFlink UDF;
用 SQL 创建 UDF;
使用 flink.udf.jars 来指定含有 udf 的 jar。
参考文档: https://www.yuque.com/jeffzhangjianfeng/gldg8w/dthfu2 参考视频: https://www.bilibili.com/video/BV1Te411W73b?p=17 https://www.bilibili.com/video/BV1Te411W73b?p=18 https://www.bilibili.com/video/BV1Te411W73b?p=19
flink.excuetion.packages
flink.execution.jars (需要注意的是在 Yarn Application 模式下,这里需要指定 HDFS 路径,因为 Flink Interpreter 运行在 JobManager 里,而JobManager 是跑在 yarn container, 在 yarn container 那台 NodeManager 机器上不一定有你要指定的 jar)
参考文档: https://www.yuque.com/jeffzhangjianfeng/gldg8w/rn6g1s 参考视频: https://www.bilibili.com/video/BV1Te411W73b?p=15
参考文档: https://www.yuque.com/jeffzhangjianfeng/gldg8w/mlnswx
同时支持 Batch SQL 和 Streaming SQL
多语句支持
Comment 支持
Job 并行度支持
Multiple insert 支持
JobName 的设置
Stream SQL 流式数据可视化
具体参考文档: https://www.yuque.com/jeffzhangjianfeng/gldg8w/te2l1c
▼ 关注「Flink 中文社区」,获取更多技术干货 ▼
 戳我,查看更多技术干货!
戳我,查看更多技术干货!
评论