
Spark Yarn Client模式解析
最近在定位Yarn的crash问题时,顺便把spark怎么使用yarn的好好的梳理了一遍。不过我先了解一下Yarn和怎么提交yarn的job的。
首先我们先看看Yarn的架构:
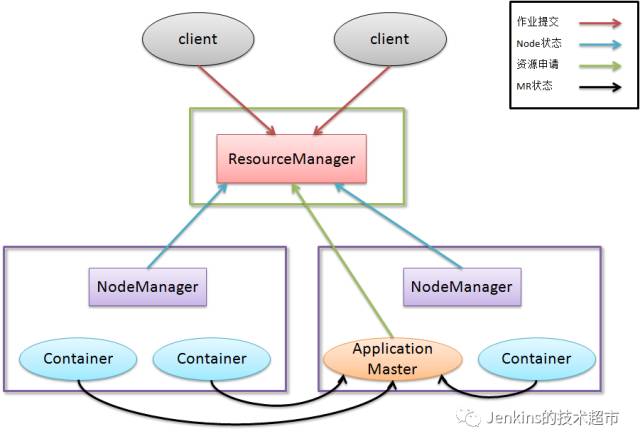
图 1 Yarn 分布式架构
-
ResourceManager
-
一个纯粹的调度器
-
根据应用程序的资源请求严格限制系统的可用资源
-
在保证容量、公平性及服务等级的情况下,优化集群资源利用率,让所有资源都得到充分的利用
-
由可插拔的调度器来应用不同的调度算法,如注重容量调度还是注意公平调度
-
ApplicationManager
-
负责与ResourceManager协商资源,并和NodeManager协同工作来执行和监控Container以及他们的资源消耗
-
有责任与ResourceManager协商并获取合适的资源Container,跟踪他们的状态,以及监控其进展
-
在真实环境中,每一个应用都有自己的ApplicationMaster的实例,但是也可为一组提供一个ApplicationMaster,比如Pig或者Hive的ApplicationMaster
一、 YarnClient 编写
1. 创建Yarn客户端
YarnClient yarnClient =YarnClient.createYarnClien。t();
yarnClient.init(conf);
yarnClient.start();
2. 创建Yarn应用
YarnClientApplication app = yarnClient.createApplication();
3. 设置Applicaton 的名字,内存 和 cpu 需求 以及 优先级和 Queue 信息, YARN将根据这些信息来调度AppMaster
app.getApplicationSubmissionContext().setApplicationName("jenkins.ApplicationMaster");
app.getApplicationSubmissionContext().setResource(Resource.newInstance(100,1));
app.getApplicationSubmissionContext().setPriority(Priority.newInstance(0));
app.getApplicationSubmissionContext().setQueue("default");
4. 设置ContainerLaunchContext,这一步, amContainer中包含了App Master 执行需要的资源文件,环境变量和 启动命令,这里将资源文件上传到了HDFS,这样在NODE Manager 就可以通过 HDFS取得这些文件
app.getApplicationSubmissionContext().setAMContainerSpec(amContainer);
5. 提交应用
ApplicationId appId =yarnClient.submitApplication(app.getApplicationSubmissionContext());
二、YARNApplicationMaster 编写
ApplicationMaster编写的编写比较复杂,其需要通Resource Manager 和 Node Manager 交互,
通过ResourceManager:申请Container,并接收Resource Manager的一些消息,如可用的Container,结束的Container等。
通过NodeManage: 启动Container,并接收Node Manage 的一些消息,如Container的状态变化以及Node状态变化。
1. 创建一个AMRMClientAsync对象,这个对象负责与ResourceManager 交互
amRMClient= AMRMClientAsync.createAMRMClientAsync( 1000, new RMCallbackHandler());
这里的RMCallbackHandler是我们编写的继承自AMRMClientAsync.CallbackHandler 的一个类,其功能是处理由ResourceManager收到的消息,
其需要实现的方法由如下
public void onContainersCompleted(List<ContainerStatus> statuses);
public void onContainersAllocated(List<Container> containers) ;
public void onShutdownRequest() ;
public void onNodesUpdated(List<NodeReport> updatedNodes) ;
public void onError(Throwable e) ;
这里不考虑异常的情况下,只写onContainersAllocated, onContainersCompleted 这两个既可以, 一个是当有新的Container 可以使用, 一个是Container 运行结束。
在onContainersAllocated我们需要编写启动container的代码,amNMClient.startContainerAsync(container, ctx); 这里的ctx 同Yarn Client 中第4步中的amContainer是同一个类型, 即这个container 执行的一些资源,环境变量与命令等, 因为这是在回调函数中,为了保证时效性,这个操作最好放在线程池中异步操作。
在onContainersCompleted中,如果是失败的Container,我们需要重新申请并启动Container,(这一点有可能是YARN的 Fair Schedule 中会强制退出某些Container 以释放资源)成功的将做记录既可以。
2. 创建一个NMClientAsyncImpl对象,这个对象负责与NodeManager 交互
amNMClient= new NMClientAsyncImpl(new NMCallbackHandler());
这里NMCallbackHandler使我们需要编写的继承自NMClientAsync.CallbackHandler 的对象,其功能是处理由NodeManager 收到的消息
public void onContainerStarted(ContainerId containerId, Map<String, ByteBuffer> allServiceResponse);
public void onContainerStatusReceived(ContainerId containerId, ContainerStatus containerStatus);
public void onContainerStopped(ContainerId containerId) ;
public void onStartContainerError(ContainerId containerId, Throwable t);
public void onGetContainerStatusError(ContainerId containerId, Throwable t) ;
public void onStopContainerError(ContainerId containerId, Throwable t);
这里简单的不考虑异常的情况下,这些函数可以写一个空函数体,忽略掉处理
3. 将ApplicationMaster注册到ResourceManager 上
RegisterApplicationMasterResponseresponse = amRMClient.registerApplicationMaster(NetUtils.getHostname(), -1,"");
这个函数将自己注册到RM上,这里没有提供RPCport 和TrackURL.
4. ApplicationMaster向ResourceManager申请Container
ContainerRequestcontainerAsk = new ContainerRequest(
//100*10M + 1vcpu
Resource.newInstance(100, 1), null, null,
Priority.newInstance(0));
amRMClient.addContainerRequest(containerAsk);
这里一个containerAsk表示申请一个Container,这里的对nodes和rasks设置为NULL,猜测MapReduce应该由参数来尝试申请靠近HDFSblock的container的
5. 申请到Container后,回调AMRMClientAsync.CallbackHandler的onContainersAllocated就会响应,然后通过amNMClient在Container运行计算任务:
List<String>commands = new LinkedList<String>();
commands.add("sleep"+ sleepSeconds.addAndGet(1));
ContainerLaunchContextctx = ContainerLaunchContext.newInstance(null, null, commands, null, null,null);
amNMClient.startContainerAsync(container,ctx);
6. 等待Container 执行完毕,清理退出
我的代码如下, 循环等待container执行完毕,并上报执行结果
void waitComplete() throws YarnException, IOException{
while(numTotalContainers.get() != numCompletedConatiners.get()){
try{
Thread.sleep(1000);
LOG.info("waitComplete" +
", numTotalContainers=" + numTotalContainers.get() +
", numCompletedConatiners=" + numCompletedConatiners.get());
} catch (InterruptedException ex){}
}
exeService.shutdown();
amNMClient.stop();
amRMClient.unregisterApplicationMaster(FinalApplicationStatus.SUCCEEDED, "dummy Message", null);
amRMClient.stop();
}
三、YARN Container Application
真正处理数据的是由ApplicationMaster由amNMClient.startContainerAsync(container, ctx)提交的 Containerapplication, 然后这这个应用并不需要特殊编写,任何程序通过提交相应的运行信息都可以在这些Node中的某个Container 中执行,所以这个程序可以是一个复杂的MapReduce Task 或者是一个简单的脚本。
总结:
YARN 提供了对cluster 资源管理 和 作业调度的功能。
编写一个应用运行在YARN 之上,比较复杂的是ApplicationMaster的编写,其需要维护container 的状态并能共做一些错误恢复,重启应用的操作。比较简答的是Client的编写,只需要提交必须的信息既可以,不需要维护状态。真正运行处理数据的是Container Application ,这个程序可以不需要针对YARN做代码编写
四、Spark Yarn Client模式
Spark Yarn有两种模式,一直是client模式,一种是cluster模式,今天我们先说说client模式,以下是Spark YarnClient的交互图。
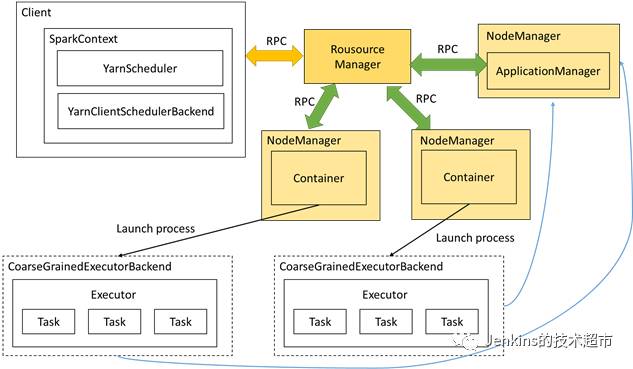
图 2 Spark Yarn Client 模式
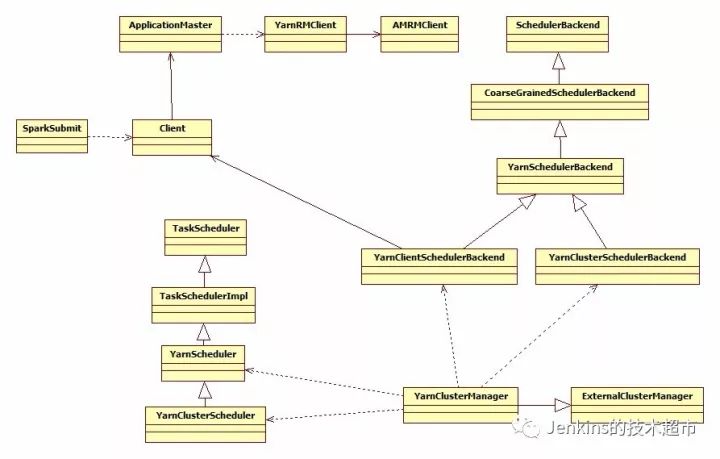
图 3 Spark Yarn 类图
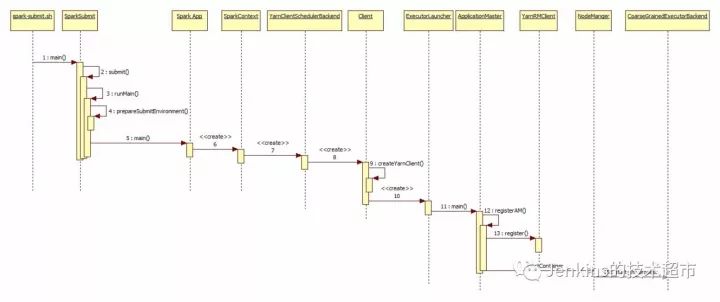
图 4 Spark Yarn Client 模式 job 提交过程