
Flink 原理 | Flink 新一代流计算和容错——阶段总结和展望
摘要:本文整理自 Apache Flink 引擎架构师、阿里巴巴存储引擎团队负责人梅源在 Flink Forward Asia 2021 核心技术专场的演讲。本次演讲内容围绕 Flink 的高可用性探讨 Flink 新一代流计算的核心问题和技术选型,包括:
Flink 高可用流计算的关键路径 容错 (Fault Tolerance) 2.0 及关键问题 数据恢复过程 稳定快速高效的 Checkpointing 云原生下容错和弹性扩缩容
一、高可用流计算的关键路径

二、容错 (Fault Tolerance) 2.0
及关键问题
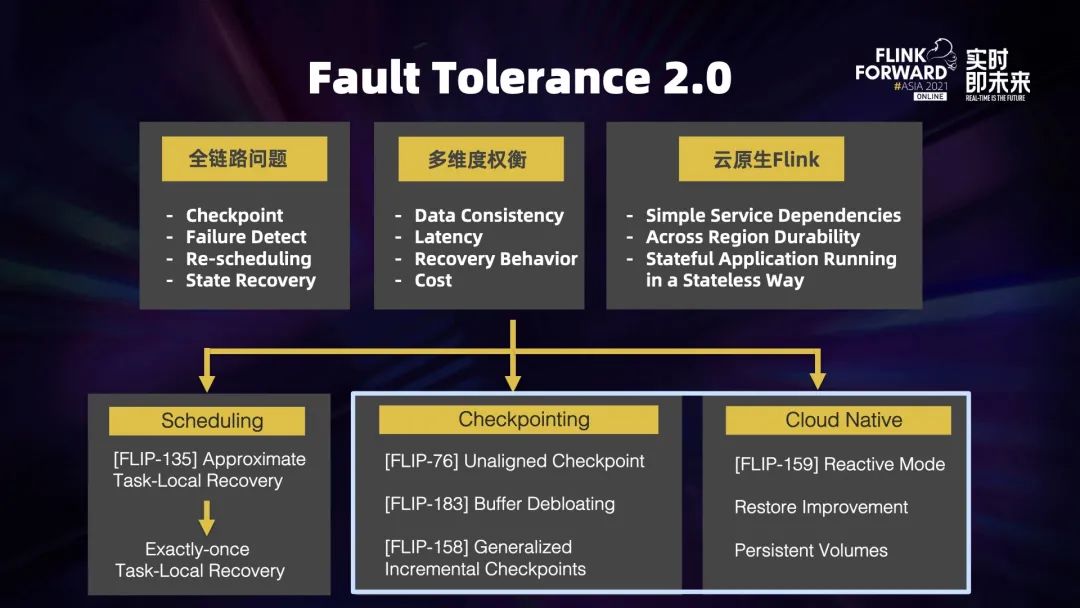
容错也是多维度的问题,不同的用户、不同的场景对容错都有不同需求,主要包括以下几个方面:
数据一致性 (Data Consistency),有些应用比如在线机器学习是可以容忍部分数据丢失; 延迟 (Latency),某些场景对端到端的延迟要求没那么高,所以可以将正常处理和容错恢复的时候要做的工作综合平均一下; 恢复时的行为表现 (Recovery Behavior),比如大屏或者报表实时更新的场景下,可能并不需要迅速全量恢复,更重要的在于迅速恢复第一条数据; 代价 (Cost),用户根据自己的需求,愿意为容错付出的代价也不一样。综上,我们需要从不同的角度去考虑这个问题。
三、Flink 中的数据恢复过程
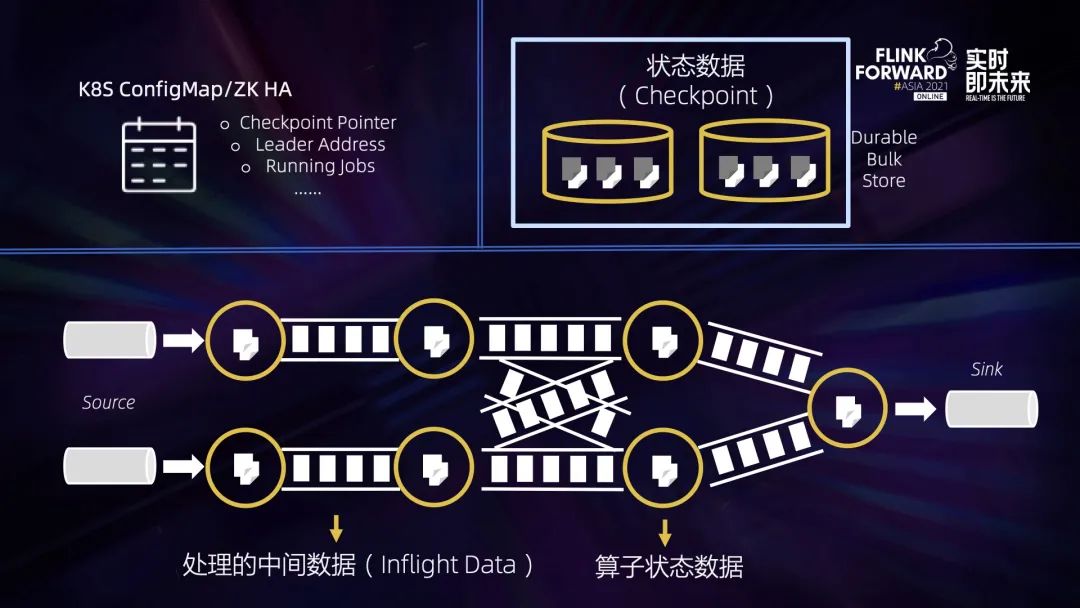
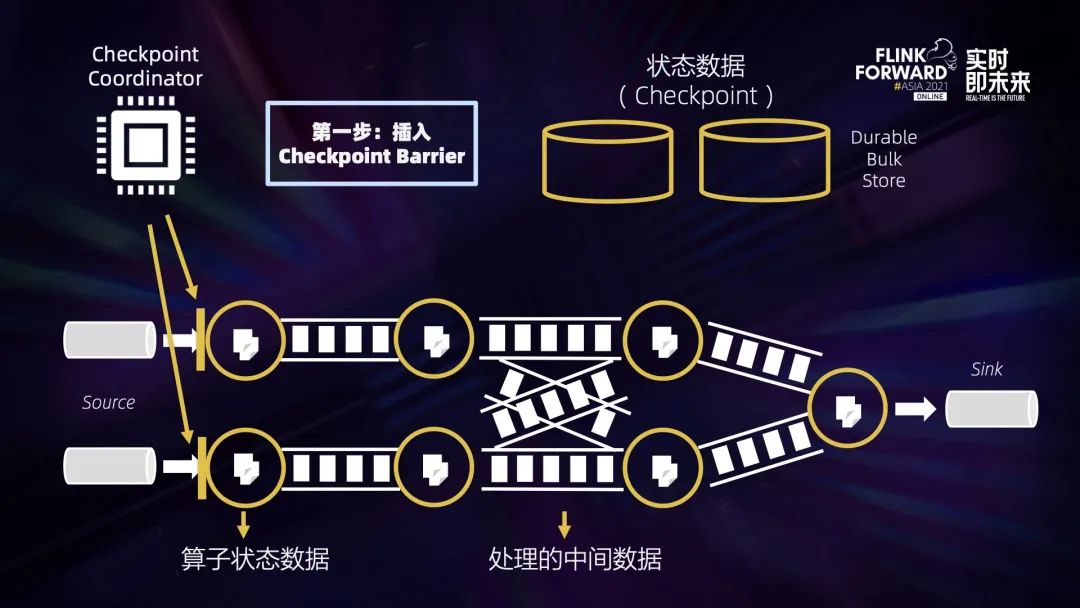
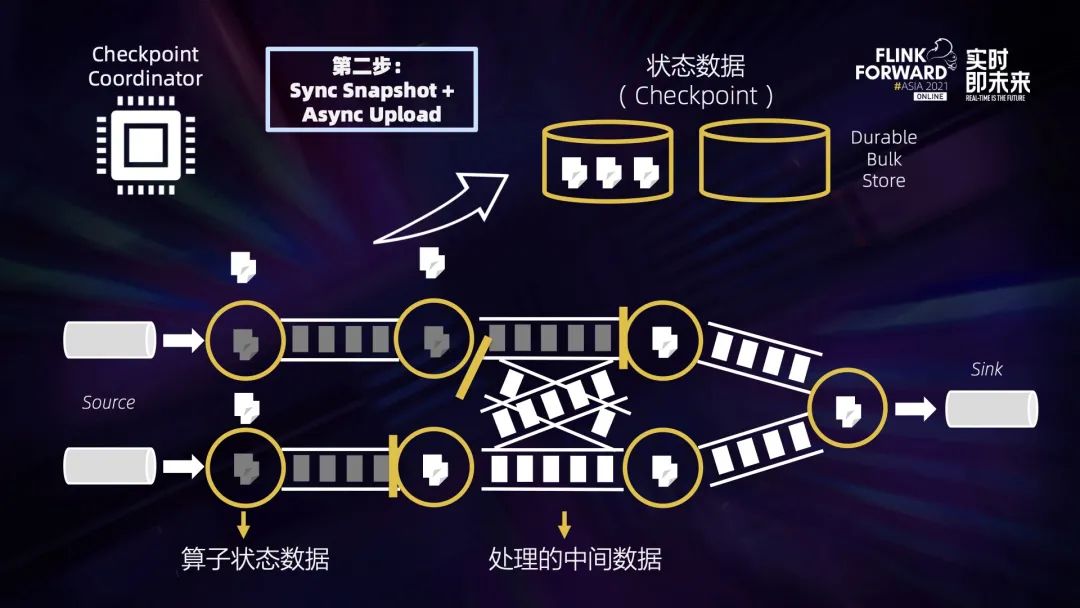
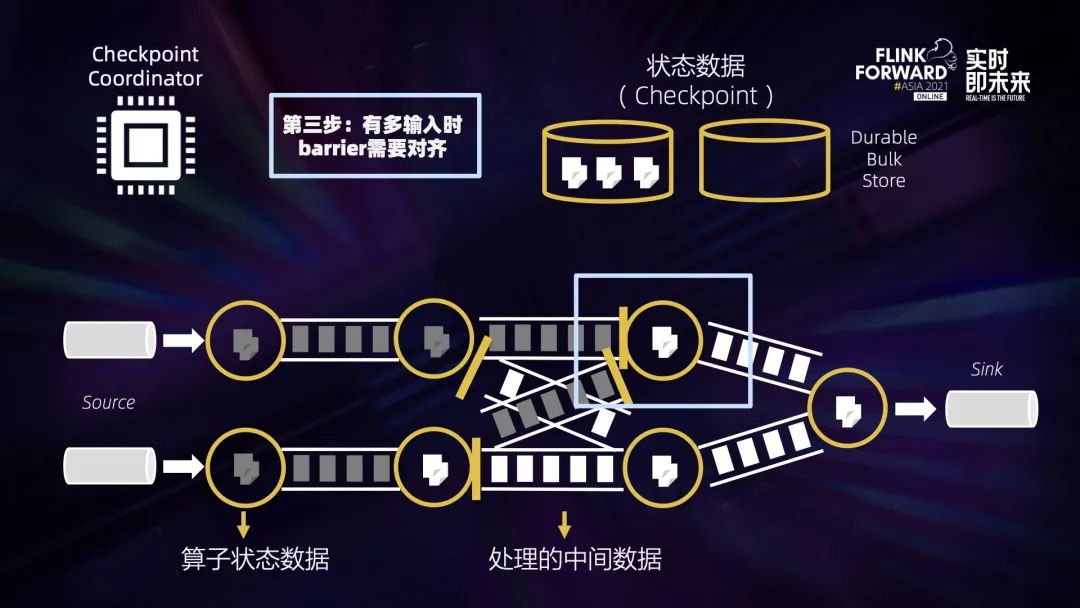
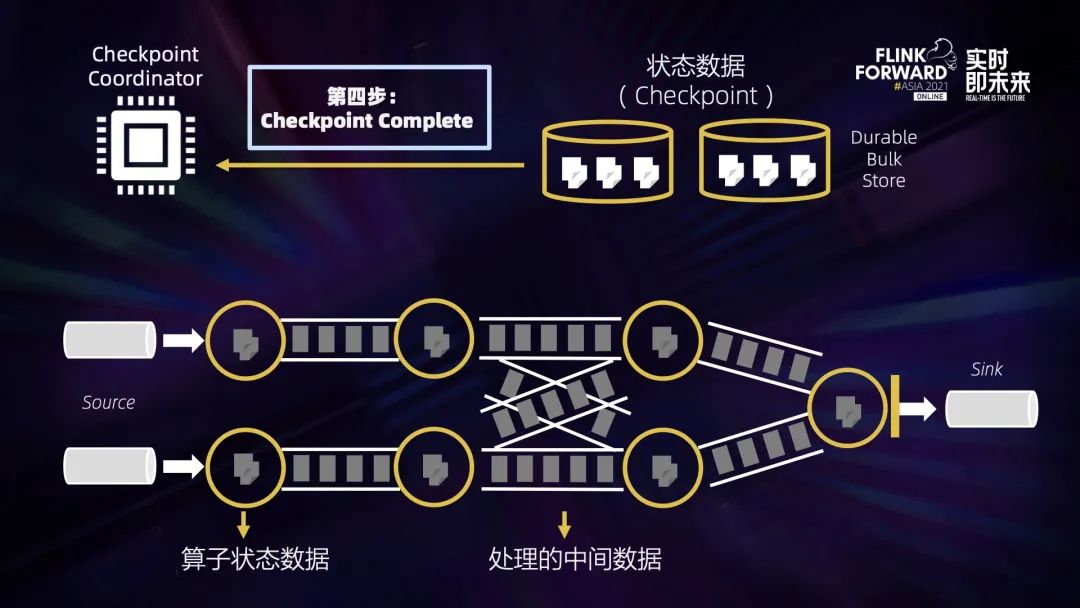
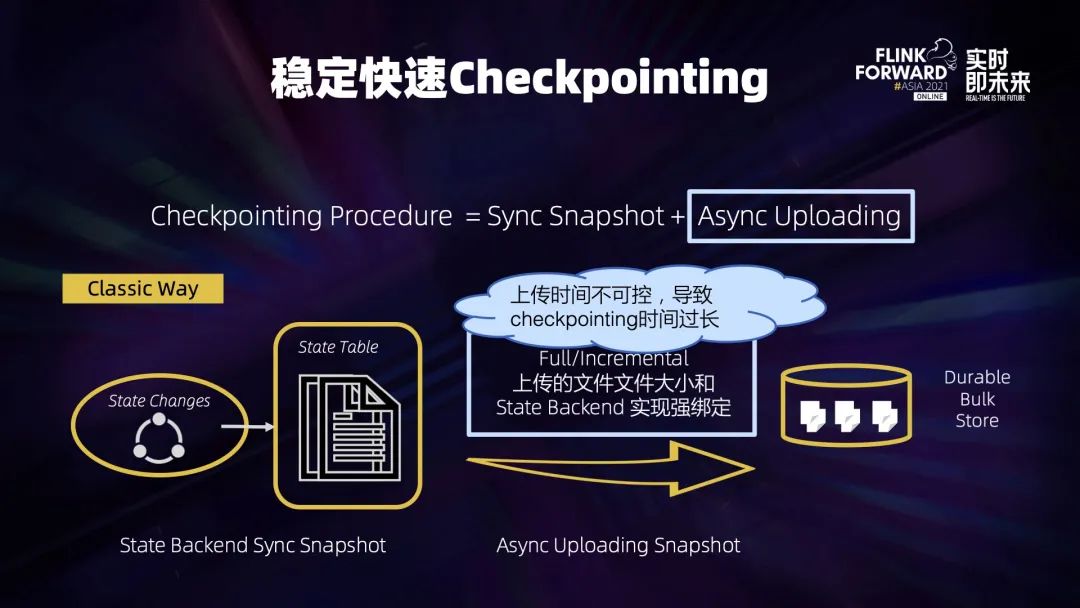
四、稳定快速高效的 Checkpointing
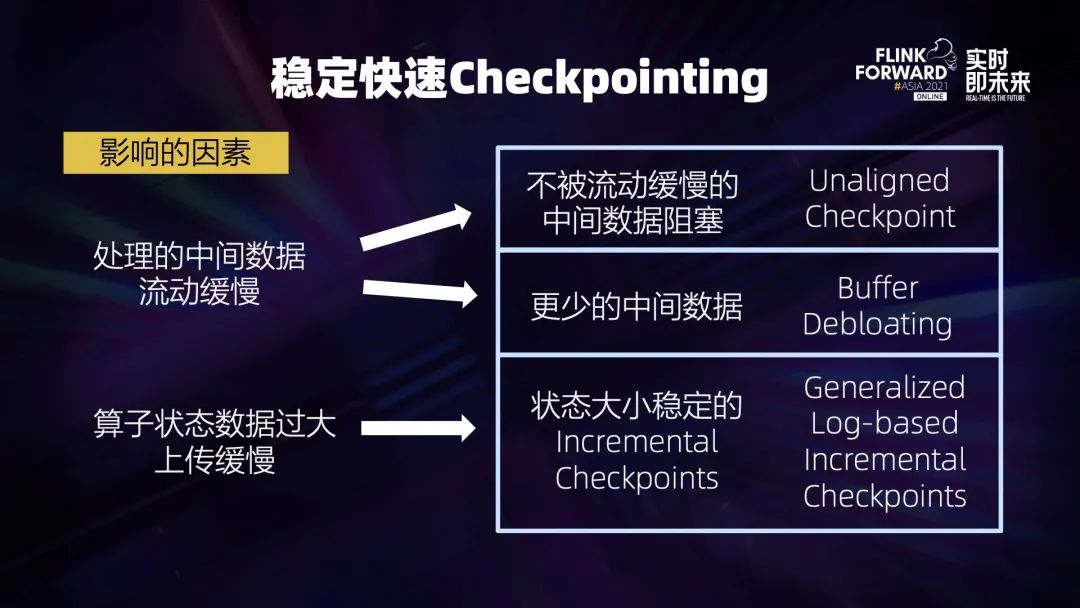
针对中间数据流动缓慢,可以:
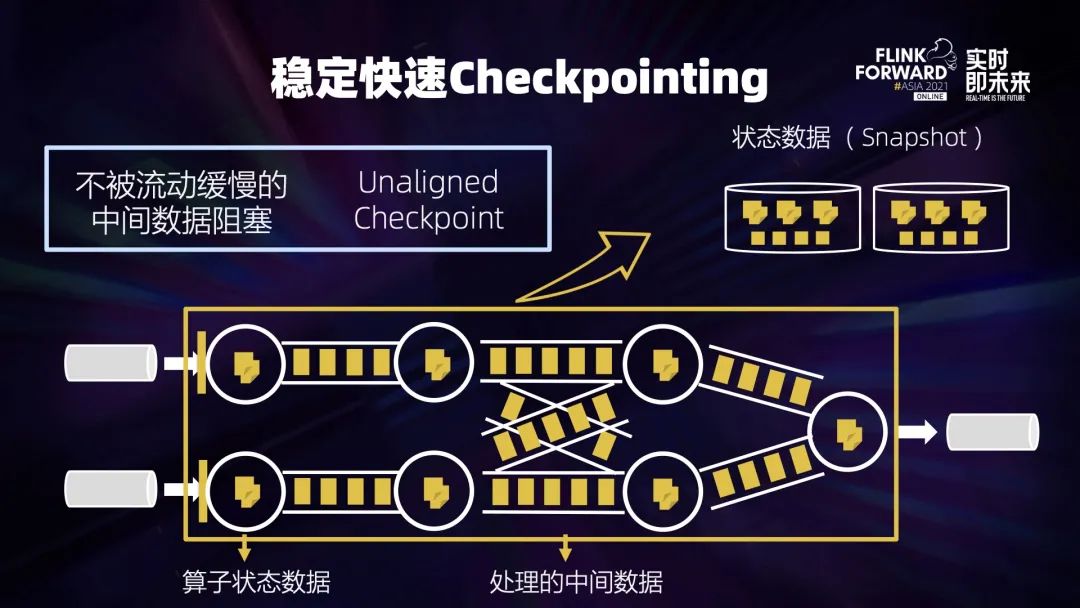
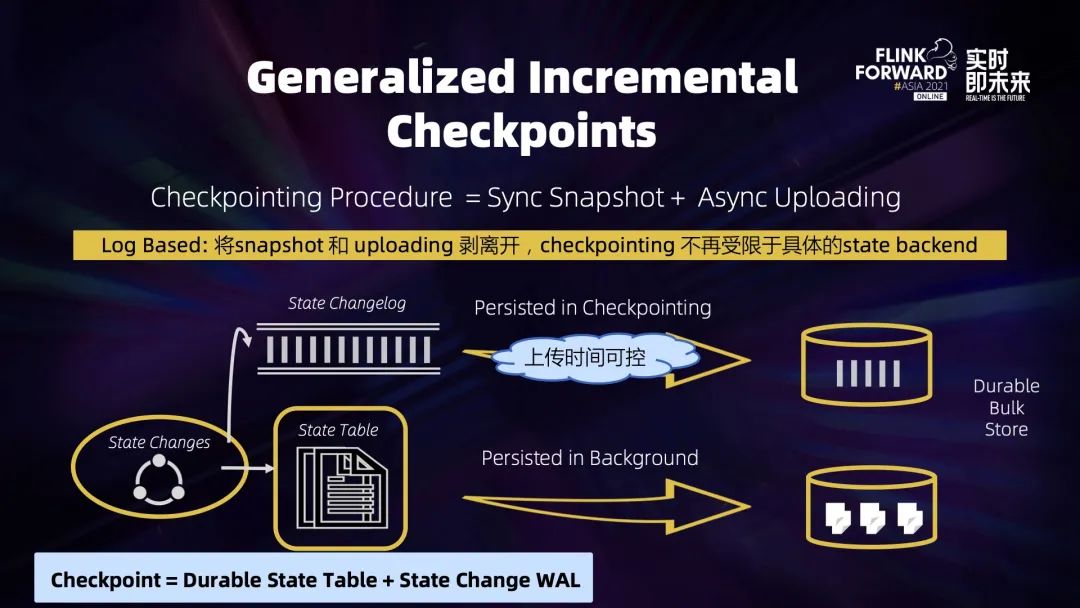
想办法不被中间数据堵塞:Unaligned Checkpoint——直接跳过阻塞的中间数据; 或者让中间的数据变得足够少:Buffer Debloating。 针对状态数据过大,我们需要将每次做 Checkpoint 时上传的数据状态变得足够小:Generalized Log-Based Incremental Checkpoint。
4.1 Unaligned Checkpoint
4.2 Buffer Debloating
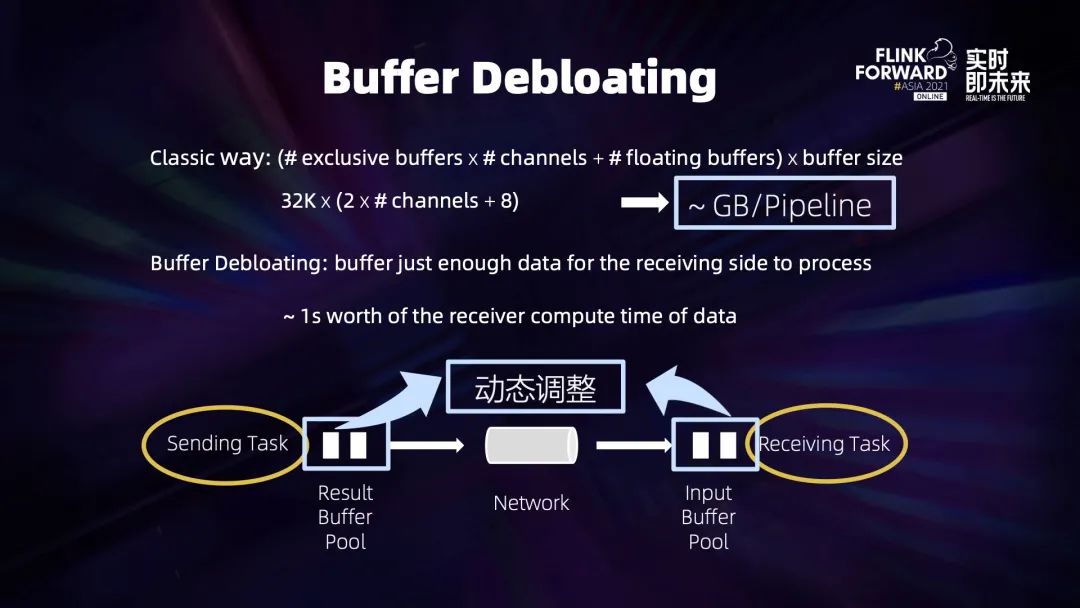
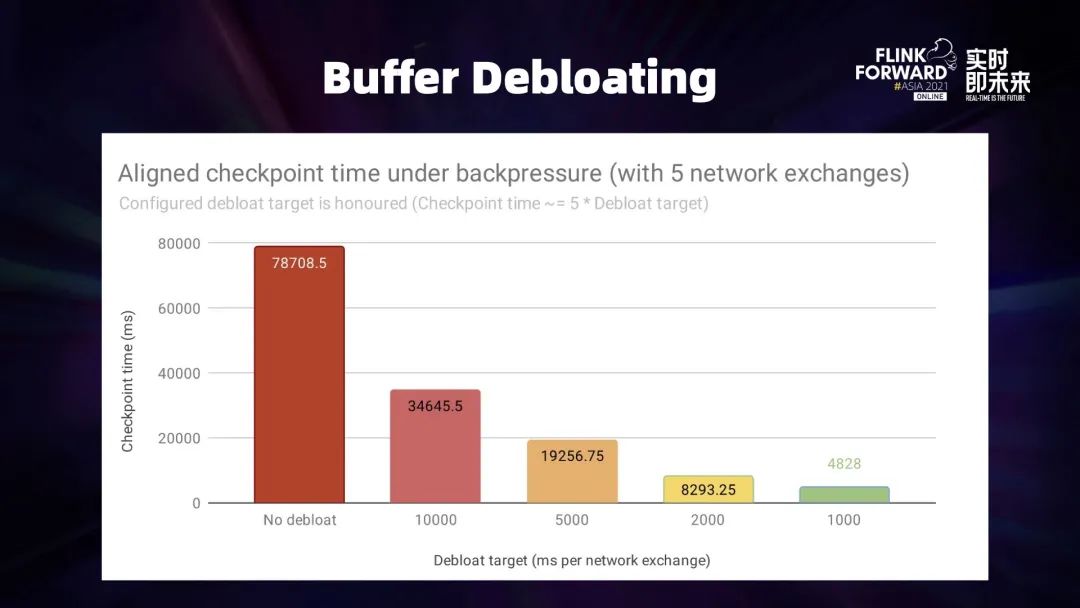
4.3 Generalized Log-Based Incremental Checkpoint
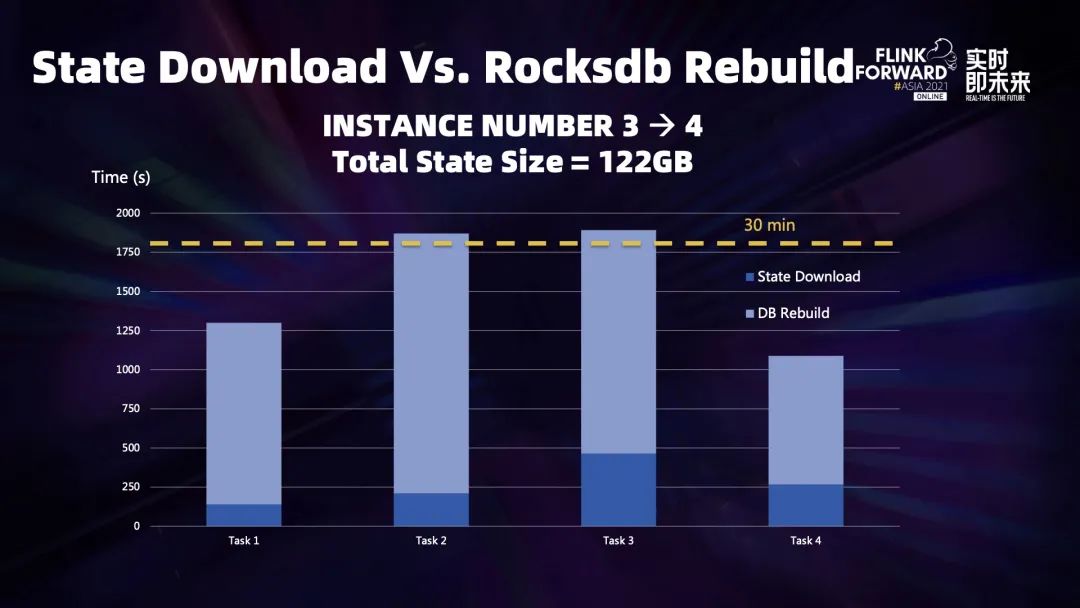
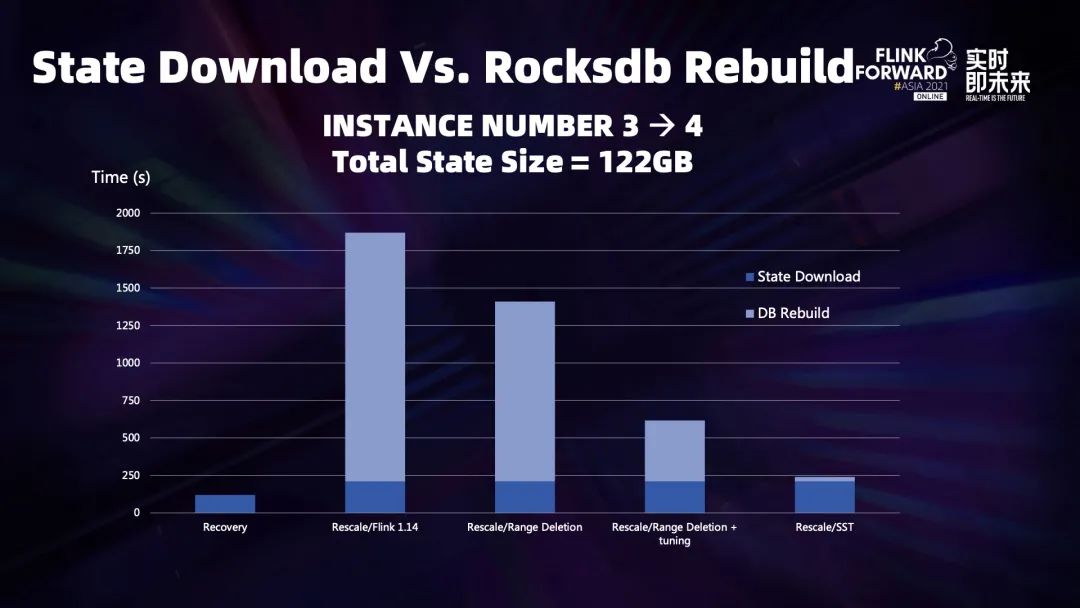
五、云原生下容错和弹性扩缩容

往期精选




 戳我,查看原文视频&演讲PDF~
戳我,查看原文视频&演讲PDF~
评论