
目标检测里,视频与图像有何区别?
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
前言 本文介绍了知乎上关于视频目标检测与图像目标检测的区别的几位大佬的回答。主要内容包括有视频目标检测与图像目标检测的区别、视频目标检测的研究进展、研究思路和方法。
作者:Naiyan Wang、炸炸、亦辰
作者:Naiyan Wang https://www.zhihu.com/question/52185576/answer/155679253
简单来说,视频检测是比单张图片检测多了Temporal Context(时间上下文)的信息。不同方法想利用这些Context来解决的问题并不相同。一类方法是关注如何使用这部分信息来加速Video Detection。因为相邻帧之间存在大量冗余,如果可以通过一些廉价的办法来加速不损害性能,在实际应用中还是很有意义的。另一类方法是关注这部分信息可以有效减轻单帧图片检测中由于运动模糊,物体面积过小导致的困难,从而来提升性能。当然最理想的方法是能又快又好啦:)
当然,这里有一些很简单的baseline方法,例如直接使用tracking关联。这类方法其实并没有深入到模型本身,一般仅仅局限于后处理步骤,虽然也可以取得一定的结果提升,但是个人觉得并不是很优美。比较关注的是来自以下两个组的工作吧。
1.CUHK: Xiaogang Wang 这面我了解到的有三篇文章,最开始 (TPAMI Short)是通过Motion的信息以及多类之间的Correlation来对单帧图像detector的输出进行后处理,算是在前面提到的Baseline方法上的小改进。后续的文章(CVPR 16)在这个基础上,引入了一个Temporal CNN对每一个Tubelet进行rescore。这样通过Temporal的信息来重新评估每个proposal的置信度。最近的工作(CVPR17)将Proposal生成这个步骤,也从静态图片拿到了时序上来做。除此之外,对于每个Tubelet的分类,也采取了流行的LSTM。
2. MSRA: Jifeng Dai 相对来讲,这面的工作更干净,思路更清晰一些。个人来说更喜欢。这面的两个工作其实思想类似,但是恰好对应于前文提到的加速和性能提升两个目的。其核心都在于通过快速计算Optical Flow来捕捉视频中的Motion信息,然后通过这个Flow的信息使用Bilinear Sampling对之前的Feature Map进行Warp(也就是通过Optical Flow来预测当前帧的Feature Map)。有了这样的信息之后,如果我们想加速,那么可以直接使用预测的Feature Map来输出结果;如果想得到更好的结果,可以将预测的Feature Map和当前帧计算出来的Feature Map融合起来一起输出结果。值得一提的是,后者也是目前唯一一个End to End的Video Detection方法。
另外有一些零碎一些的工作,基本都是在后处理过程中,处理rescore detection的问题,例如Seq-NMS等等。
最后呢,想来抛砖引玉,提出一个我们观察到在Video Detection中的问题,我们也写了一篇paper来讲这个事情([1611.06467] On The Stability of Video Detection and Tracking) 也就是在Video Detection中的稳定性(Stability)的问题。见下面这个Video,其实两个Detector如果论准确性来讲,差别并不大,然而对于人眼来看,孰优孰劣一目了然。
视频链接:https://v.youku.com/v_show/id_XMjY5MTM4MTI5Mg==.html?spm=a2hzp.8253869.0.0&from=y1.7-2
这样的稳定性的问题,在实际的应用中其实也会带来很多困扰。例如在自动驾驶中,需要稳定的2D检测框来进行车辆距离和速度的估计。不稳定的检测都会极大影响后续任务的准确性。所以呢,我们在文章中首先提出了一个定量的指标来衡量这种稳定性,然后评测了几种简单的Baseline。我们还计算了这个Stability指标和常用的Accuracy指标之间的Correlation,发现其实这两种指标其实相关性并不大,也就是说分别捕捉到了Video Detection中两方面的一个质量。希望这个工作能给大家一些启发,在改进准确性之余,也考虑一下同等重要的稳定性如何改进。
作者:炸炸 https://www.zhihu.com/question/52185576/answer/298921652
在这里想从自己的角度解答一下两者的机理与区别。因为是前两年在做基于视频的目标检测和跟踪,所用的方法相对于现行的Long Short-Term Memory (LSTM)可能相对老套,但是我觉得题主该是新手,了解一下过去的经典还是有意义的,可以作为前期补充。
研究问题
无论是基于视频还是图像,我们研究的核心是目标检测问题,即在图像中(或视频的图像中)识别出目标,并且实现定位。
基于单帧图像的目标检测
在静态图像上实现目标检测,本身是一个滑窗+分类的过程,前者是帮助锁定目标可能存在的局部区域,后者则是通过分类器打分,判断锁定的区域是否有(是)我们要寻找的目标。研究的核心多集中于后者,选什么样的特征表示来描述你锁定的区域(HOG, C-SIFT, Haar, LBP, CNN, Deformable Part Models (DPM) and etc.),将这些特征输入到什么样的分类器(SVM,Adaboost and etc.)进行打分,判断是否是我们要找的目标。
尽管我们要检测的目标可能外形变化多端(由于品种,形变,光照,角度等等),通过大量数据训练CNN得到的特征表示还是能很好地帮助实现识别和判定的过程。但是有些极端情况下,如目标特别小,或者目标和背景太相似,或者在这一帧图像中因为模糊或者其他原因,目标确实扭曲的不成样子,CNN也会觉得力不从心,认不出来它原来是我们要找的目标呢。另外一种情况是拍摄场景混入了其他和目标外观很像的东西 (比如飞机和展翅大鸟),这时候也可能存在误判。
也就是在这几种情况下,我们可能无法凭借单帧的外观信息,完成对目标鲁棒的检测。
基于视频的目标检测
单帧不够,多帧来凑。在视频中目标往往具有运动特性,这些特性来源有目标本身的形变,目标本身的运动,以及相机的运动。所以引入多帧之后,我们不仅可以获得好多帧目标的外观信息,还能获得目标在帧间的运动信息。于是就有了以下的方法:
第一种:侧重于目标的运动信息
先基于motion segmentation 或是 background extraction(光流法和高斯分布等)实现对前景和背景的分离,也就是说我们借助运动信息挑出了很有可能是目标的区域;再考虑连续帧里目标的持续性(大小,颜色,轨迹的一致性),可以帮助删去一部分不合格的候选的目标区域;然后对挑出的区域打分做判断,还是利用外观信息(单帧里提到的)。
第二种:动静结合,即在第一种的基础上,加入目标的外观形变
有些目标在视频中会呈现幅度较大的,有一定规律的形变,比如行人和鸟。这时我们可以通过学习形变规律,总结出目标特殊的运动特征和行为范式,然后看待检测的目标是否满足这样的行为变化。常见的行为特征表示有3D descriptors,Markov-based shape dynamics, pose/primtive action-based histogram等等。这种综合目标静态和动态信息来判断是否是特定目标的方法,有些偏向action classification。
第三种:频域特征的利用
在基于视频的目标检测中,除了可以对目标空间和时间信息进行分析外,目标的频域信息在检测过程中也能发挥巨大的作用。比如,在鸟种检测中,我们可以通过分析翅膀扇动频率实现鸟种的判别。
值得注意的是这里基于视频的目标检测(video-based detection)存在两种情况,一种是你只想知道这个场景中有没有这种目标,如果有,它对应的场景位置是哪; 另一种是这个场景有没有这种目标,它在每一帧中的位置是哪。我们这里介绍的方法侧重的是后一种更复杂的。
Deep learning 是钱途无量的,也是横行霸道的。希望视觉特征建模也能继续发展,整个计算机视觉研究领域更加多元化,而非被机器学习边缘化。
作者:亦辰 https://www.zhihu.com/question/52185576/answer/413306776
1.与图像目标检测的区别


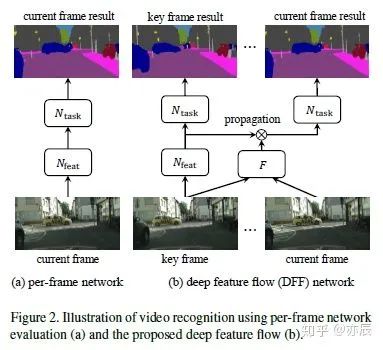
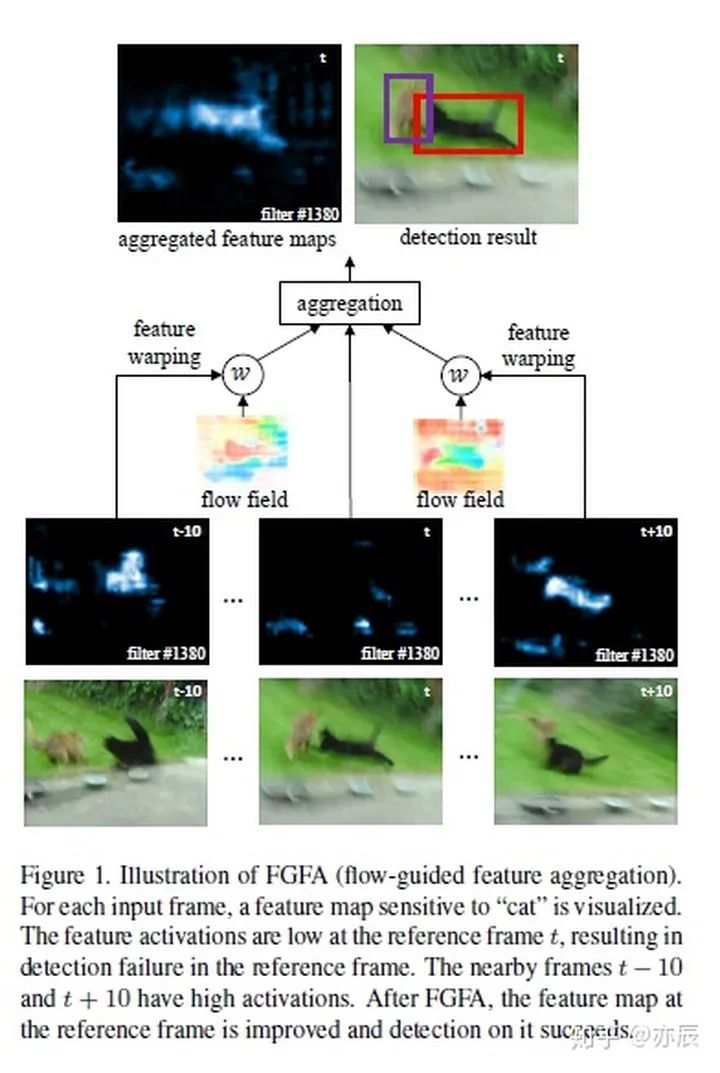
2. 与目标跟踪结合的方法
链接:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1710.03958
3. 与RNN结合的方法
链接:[1712.06317] Video Object Detection with an Aligned Spatial-Temporal Memory (arxiv.org)
链接:[1607.04648] Context Matters: Refining Object Detection in Video with Recurrent Neural Networks (arxiv.org)
4. 其他融合方法
链接:[1712.05896] Impression Network for Video Object Detection (arxiv.org)
5. 非端到端方法
链接:[1604.02532v4] T-CNN: Tubelets with Convolutional Neural Networks for Object Detection from Videos (arxiv.org)
链接:[1602.08465v3] Seq-NMS for Video Object Detection (arxiv.org)
综上,当下视频目标检测研究相对于图像领域还不够火热。研究思路多是要么关注利用冗余信息提高检测速度,要么融合连续帧之间上下文信息提高检测质量。减少冗余,提高速度这方面工作不是很多。(也有可能文章看的还不够多,欢迎指正)而融合上下文信息可以考虑借助行为识别常用的3D卷积,RNN,注意力模型等方法。
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!