
实操教程 | 卷积神经网络CNN详解

作者 | 台运鹏
来源 | AI有道
编辑 | 极市平台
极市导读
本文将通过Filter、池化、demo、冷知识等章节对卷积神经网络(CNN)进行解析,内含详细教程。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
章节
Filter
池化
Demo
冷知识
参考
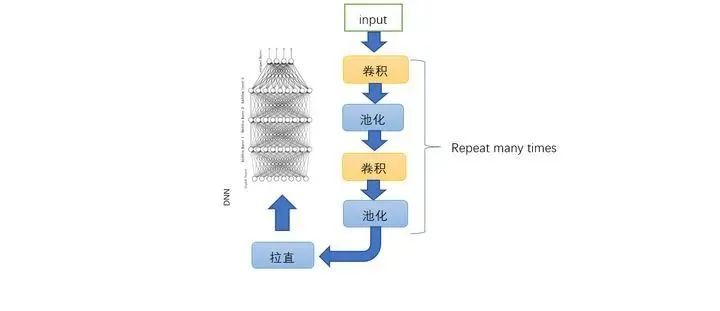
CNN 一共分为输入,卷积,池化,拉直,softmax,输出。
卷积由互关运算(用Filter完成)和激活函数。
Filter
CNN常用于图像识别,在深度学习中我们不可能直接将图片输入进去,向量是机器学习的通行证,我们将图片转换为像素矩阵再送进去,对于黑白的图片,每一个点只有一个像素值,若为彩色的,每一个点会有三个像素值(RGB)。
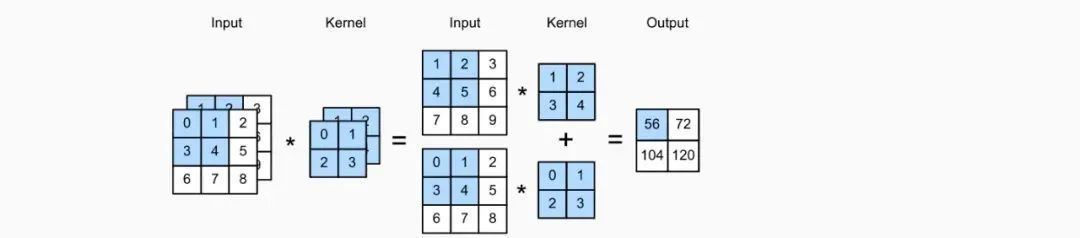
互关运算其实就是做矩阵点乘运算,用下面的Toy Example说明:其实就是用kernel(filter)来与像素矩阵局部做乘积,如下图,output的第一个阴影值其实是input和kernel的阴影部分进行矩阵乘法所得:

接下来引入一个参数(Stride),代表我们每一次滤波器在像素矩阵上移动的步幅,步幅共分为水平步幅和垂直步幅,下图为水平步幅为2,垂直步幅为3的设置。

所以filter就不断滑过图片,所到之处做点积,那么,做完点积之后的shape是多少呢?假设input shape是32 * 32,stride 为1,filter shape 为4 * 4,那么结束后的shape为29 * 29,计算公式是((input shape - filter shape) / stride ) + 1,记住在深度学习中务必要掌握每一层的输入输出。
那么,假如stride改为3,那么((32 - 4) / 3) + 1 不是整数,所以这样的设定是错误的,那么,我们可以通过padding的方式填充input shape,用0去填充,这里padding设为1,如下图,填充意味着输入的宽和高都会进行增加2 * 1,那么接下来的out shape 就是 ((32 + 2 * 1 - 4)/3) + 1,即为11 * 11。

接下来引入通道(channel),或为深度(depth)的介绍,一张彩色照片的深度为3,每一个像素点由3个值组成,我们的filter的输入通道或者说是深度应该和输入的一致,举例来说,一张照片32 * 32 * 3,filter可以设置为3 * 3 * 3,我们刚开始理解了一维的互关运算,三维无非就是filter拿出每一层和输入的每一层做运算,最后再组成一个深度为3的输出,这里stride设置为1,padding也为1,所以输出的shape为30 * 30 * 3。
卷积的时候是用多个filter完成的,一般经过卷积之后的output shape的输入通道(深度)为filter的数量,下图为输入深度为2的操作,会发现一个filter的输出最终会相加,将它的深度压为1,而不是一开始的输入通道。这是一个filter,多个filter最后放在一起,最后的深度就是filter的数量了。
Q & A
1.卷积的意义是什么呢?
其实如果用图片处理上的专业术语,被叫做锐化,卷积其实强调某些特征,然后将特征强化后提取出来,不同的卷积核关注图片上不同的特征,比如有的更关注边缘而有的更关注中心地带等等,如下图:

当完成几个卷积层后(卷积 + 激活函数 + 池化):
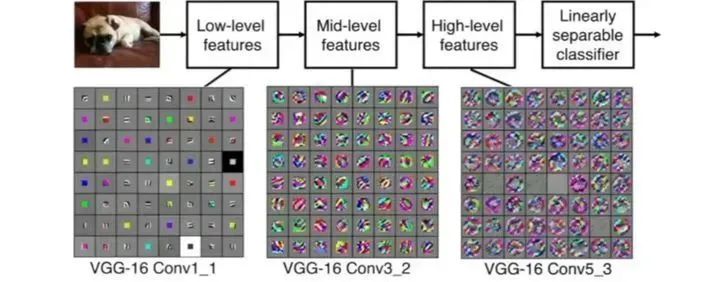
可以看出,一开始提取一些比较基础简单的特征,比如边角,后面会越来越关注某个局部比如头部甚至是整体。
2.如何使得不同的卷积核关注不同的地方?
设置filter矩阵的值,比如input shape是4 * 4的,filter是2 * 2,filter是以一个一个小区域为单位,如果说我们想要关注每一个小区域的左上角,那么将filter矩阵的第一个值设为1,其他全为0即可。
总结来说,就是通过不断改变filter矩阵的值来关注不同的细节,提取不同的特征
3.filter矩阵里的权重参数是怎么来的?
首先会初始化权重参数,然后通过梯度下降不断降低loss来获得最好的权重参数
4.常见参数的默认设置有哪些?
一般filter的数量(output channels)通常可以设置为2的指数次,如32,64,128,512,这里提供一组比较稳定的搭配(具体还得看任务而定),F(kernel_size/filter_size)= 3,stride = 1,padding = 1;F = 5,stride = 1,Padding = 2;F = 1,S = 1,P = 0
5.参数数量?
举例来说,filter的shape为5 * 5 * 3 ,一共6个,stride设置为1,padding设为2,卷积层为(32 * 32 * 6),注意卷积层这里是代表最后的输出shape,输入shape为 32 * 32 * 3,那么所需要的参数数量为 6 * (5 * 5 * 3 + 1),里面 +1 的原因是原因是做完点积运算之后会加偏置(bias),当然这个参数是可以设置为没有的
6. 1x1 卷积的意义是什么?
filter的shape为1 x 1,stride = 1,padding = 0,假如input为32 * 32 * 3,那么output shape = (32 - 1) / 1 + 1 = 32,换言之,它并没有改变原来的shape,但是filter的数量可以决定输出通道,所以,1 x 1的卷积目的是改变输出通道。可以对输出通道进行升维或者降维,降维之后乘上的参数数量会减少,训练会更快,内存占用会更少。升维或降维的技术在ResNet中同样运用到啦(右图):
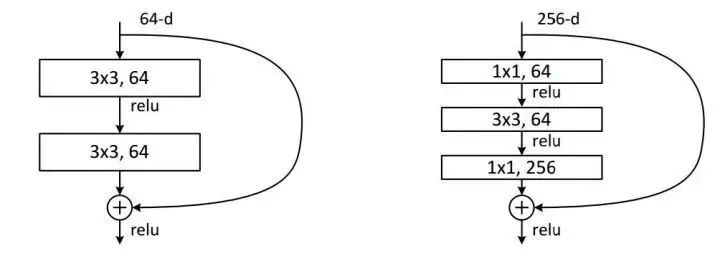
另外,其实1 x 1的卷积不过是实现多通道之间的线性叠加,如果你还记得上面多通道的意思,1 x 1 卷积改变卷积核的数量,无非就是使得不同的feature map进行线性叠加而已(feature map指的是最后输出的每一层叠加出来的),因为通道的数量可以随时改变,1 x 1卷积也可以有跨通道信息交流的内涵。
池化
卷积好之后会用RELU进行激活,当然,这并不会改变原来的shape,这样可以增加模型的非线性兼容性,如果模型是线性的,很容易出问题,如XOR问题,接下来进行池化操作(Pooling),常见的是MaxPooling(最大池化),它基本上长得跟filter一样,只不过功能是选出区域内的最大值。假如我们的shape是4 * 4 ,池化矩阵的shape是2 * 2,那么池化后的shape是2 * 2(4 / 2)。
那么,池化的意义是什么?池化又可以被成为向下取样(DownSample),经过池化之后shape会减小不少,如果说卷积的意义是提取出特征,那么,池化的意义是在这些特征中取出最有代表性的特征,这样可以降低像素的重复性,使得后续的卷积更有意义,同时可以降低shape,使得计算更为方便。
当然,也还有平均池化(AveragePooling),这样做试图包含区域内的所有的特征,那么,如果图片相邻色素重复很多,那么最大池化是不错的,如果说一张图片很多不同的特征需要关注,那么可以考虑平均池化。
补充一下,可以给上述池操作加一个Global,这就意味着全局,而不是一个一个的小区域。
Demo
我的PyTorch完整Demo在:https://colab.research.google.com/drive/1XMlSmiZ4FjHohptX-GSHsT_CFs4EoE6f?usp=sharing
进行卷积池化这样一组操作多次之后再全部拉直送入全连接网络,最后输出10个值,然后优化它们与真实标签的交叉熵损失,接下来用PyTorch和TensorFlow实操一下。
首先先搭建一个简单的PyTorch网络,这里采用Sequential容器写法,当然也可以按照普遍的self.conv1 = ...,按照Sequential写法更加简洁明了,后面前向传播函数也没有采取x = ...不断更新x,而是直接放进layer,遍历每一层即可,简洁干净。
# 导入库
import torch
from torch import nn
import torchvision
from torchvision import datasets,transforms
import torch.nn.functional as F
import matplotlib.pyplot as plt
class Net(nn.Module):
def __init__(self):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=32,kernel_size=3),nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32,64,2),nn.ReLU(),
nn.MaxPool2d(2,2),
nn.Flatten(),
nn.Linear(64 * 6 * 6,10),nn.Softmax(),
)
def forward(self,x):
x = self.layer(x)
return x
PyTorch中输入必须为(1,1,28,28),这里比tensorflow多了一个1,原因是Torch中有一个group参数,默认为1,所以可以不设置,如果为N,就会把输入分为N个小部分,每一个部分进行卷积,最后再将结果拼接起来
搭建好网络之后,建议先检验一下网络和优化器参数
# 如果GPU没有就会调到CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Net().to(device)
print(model.parameters)
# 训练时还需要优化器(Optimizer)
optimizer = torch.optim.Adam(model.parameters())
print(optimizer)

接下来定义训练和测试函数,先介绍几个小知识
model.train() # 启用BatchNormalization和Dropout
model.eval() # 因为是测试,所以取消两者
i = torch.tensor([
[1,2,3],
[4,5,6]
])
# 输出最大的值和它的索引
print(i.max(1,keepdim=True))
# torch.return_types.max(values=tensor([[3],[6]]), indices=tensor([[2],[2]]))
# 一般只要索引的话:
print(i.max(1,keepdim=True))[1]
# tensor([[2],
# [2]])
a = torch.tensor([1,2,3,4])
b = torch.tensor([[1],
[-1],
[-2],
2])
# 将a转换为与b形状相同
a.view_as(b)
print(a)
# tensor([[1],
# [2],
# [3],
# [4]])
# 相对于numpy的equal函数,判断tensor里每一个值是否相等
# 输出为True 或者 False
print(b.eq(a.view_as(b)))
# tensor([[ True],
# [False],
# [False],
# [False]])
# 求和用来判断损失和准确率
# True --> 1,False --> 0
print(b.eq(a.view_as(b)).sum())
# tensor(1)
# 最后将PyTorch的tensor转换为Python中标准值
print(b.eq(a.view_as(b)).sum().item())
# 1
# 下载训练和测试数据集
# transforms函数可以对下载的数据做一些预处理
# Compose 指的是将多个transforms操作组合在一起
# ToTensor 是将[0,255] 范围 转换为[0,1]
# 灰度图片(channel=1),所以每一个括号内只有一个值,前者代表mean,后者std(标准差)
# 彩色图片(channel=3),所以每一个括号内有三个值,如
# transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,),(0.5,))
])
data_train = datasets.MNIST(root="填自己的主路径",
transform=transform,
train=True,
download=True)
data_test = datasets.MNIST(root="填自己的主路径",
transform=transform,
train=False)
# 加载数据集
# Load Data
train_loader = torch.utils.data.DataLoader(dataset=data_train,
batch_size=64,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=data_test,
batch_size=64,
shuffle=True)
每一次新的batch中都需要梯度清零,否则的话梯度就会跨batch。
def train(model,device,train_loader,optimizer,epoch):
model.train()
for batch_idx,(data,target) in enumerate(train_loader):
data,target = data.to(device),target.to(device)
optimizer.zero_grad() # 梯度清零
output = model(data)
loss = F.nll_loss(output,target) # negative likelihood loss
loss.backward() # 误差反向传播
optimizer.step() # 参数更新
if (batch_idx + 1) % 200 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item())) # .item()转换为python值
return loss.item()
因为测试的时候不需要更新参数,所以with torch.no_grad()。
# 定义测试函数
def test(model, device, test_loader):
model.eval()
test_loss,correct = 0 , 0
with torch.no_grad(): # 不track梯度
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction = 'sum') # 将一批的损失相加
pred = output.max(1, keepdim = True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item() # equals
test_loss /= len(test_loader.dataset)
acc = correct / len(test_loader.dataset)
print("\nTest set: Average loss: {:.4f}, Accuracy: {} ({:.0f}%) \n".format(
test_loss, acc ,
100.* correct / len(test_loader.dataset)
))
return acc
接下来定义可视化函数
def visualize(lis,epoch,*label):
plt.xlabel("epochs")
plt.ylabel(label)
plt.plot(epoch,lis)
plt.show()
最后进行训练和测试
BATCH_SIZE = 512 # 大概需要2G的显存
EPOCHS = 20 # 总共训练批次
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_ = []
test_acc = []
for epoch in range(1,EPOCHS+1):
train_loss = train(model,DEVICE,train_loader,optimizer,epoch)
acc = test(model,DEVICE,test_loader)
train_.append(train_loss)
test_acc.append(acc)
visualize(train_,[i for i in range(20)],"loss")
visualize(test_acc,[i for i in range(20)],"accuracy")
接下来使用tensorflow-gpu 1.14.0再实操一下
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import matplotlib as mpl
import sys
# solve could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.compat.v1.InteractiveSession(config=config)
# 不同库版本,使用此代码块查看
print(sys.version_info)
for module in mpl,np,tf,keras:
print(module.__name__,module.__version__)
'''
sys.version_info(major=3, minor=6, micro=9, releaselevel='final', serial=0)
matplotlib 3.3.4
numpy 1.16.0
tensorflow 1.14.0
tensorflow.python.keras.api._v1.keras 2.2.4-tf
'''
# If you get numpy futurewarning,then try numpy 1.16.0
# load train and test
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
# 1 Byte = 8 Bits,2^8 -1 = 255。[0,255]代表图上的像素,同时除以一个常数进行归一化。1 就代表全部涂黑。0 就代表没涂
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# CNN 的输入方式必须得带上channel,这里扩充一下维度
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
# y 属于 [0,9]代表手写数字的标签,这里将它转换为0-1表示,可以类比one-hot,举个例子,如果是2
# [[0,0,1,0,0,0,0,0,0,0]……]
model = keras.Sequential(
[
keras.Input(shape=(28, 28, 1)),
keras.layers.Conv2D(filters=32, kernel_size=(3, 3), activation="relu"),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Conv2D(filters=64, kernel_size=(3, 3), activation="relu"),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(units=10, activation="softmax"),
]
)
# 注意,Conv2D里面有激活函数不代表在卷积和池化的时候进行。而是在DNN里进行,最后拉直后直接接softmax就行
# kernel_size 代表滤波器的大小,pool_size 代表池化的滤波器的大小
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.summary()
history = model.fit(x_train, y_train, batch_size=128, epochs=15, validation_split=0.1) #10层交叉检验
score = model.evaluate(x_test, y_test)
print("Test loss:", score[0])
print("Test accuracy:", score[1])
# Test loss: 0.03664601594209671
# Test accuracy: 0.989300012588501
# visualize accuracy and loss
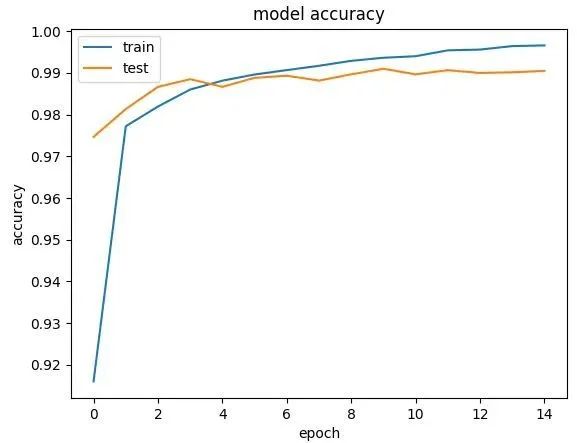
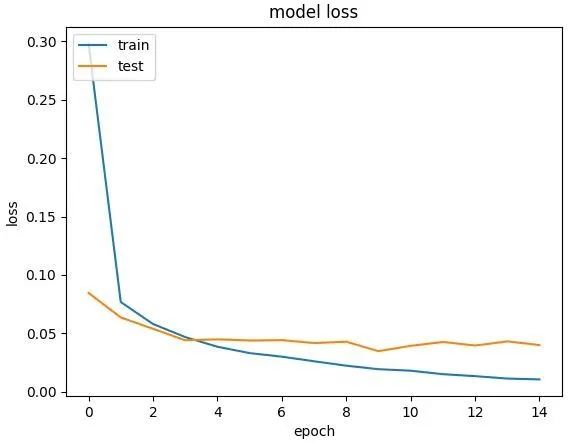
def plot_(history,label):
plt.plot(history.history[label])
plt.plot(history.history["val_" + label])
plt.title("model " + label)
plt.ylabel(label)
plt.xlabel("epoch")
plt.legend(["train","test"],loc = "upper left")
plt.show()
plot_(history,"acc")
plot_(history,"loss")
在机器学习中画精确度和loss的图很有必要,这样可以发现自己的代码中是否存在问题,并且将这个问题可视化。
冷知识
We don't minimize total loss to find the best function.
我们采取将数据打乱并分组成一个一个的mini-batch,每个数据所含的数据个数也是可调的。关于epoch。
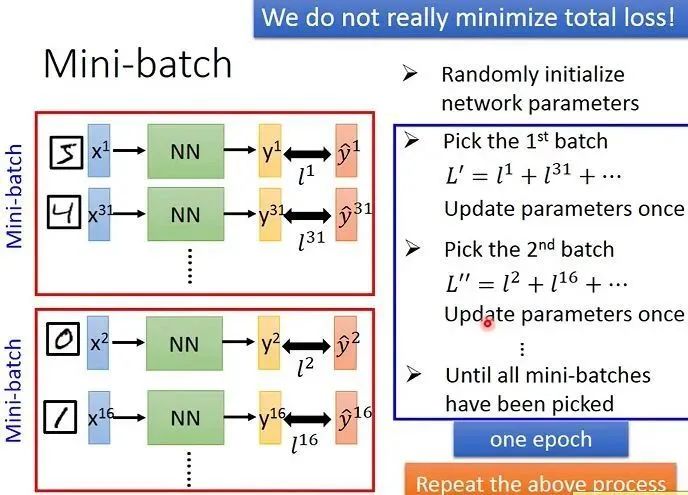
将一个mini-batch中的loss全部加起来,就更新一次参数。一个epoch就等于将所有的mini-batch都遍历一遍,并且经过一个就更新一次参数。
如果epoch设为20,就将上述过程重复20遍。
这里再细谈一下batch 和 epoch。
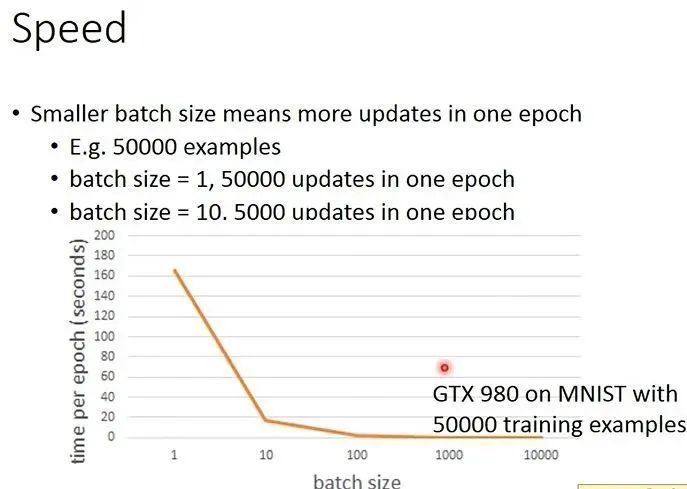
由图可知,当batch数目越多,分的越开,每一个epoch的速度理所应当就会**上升**的,当batch_size = 1的时候,1 epoch 就更新参数50000次 和 batch_size = 10的时候,1 epoch就更新5000次,那么如果更新次数相等的话,batch_size = 1会花**166s**;batch_size = 10每个epoch会花**17s**,总的时间就是**17 * 10 = 170s**。其实batch_size = 1不就是[SGD](../optimization/GD.md)。随机化很不稳定,相对而言,batch_size = 10,收敛的会更稳定,时间和等于1的差不多。那么何乐而不为呢?
肯定有人要问了?随机速度快可以理解,看一眼就更新一次参数.

为什么batch_size = 10速度和它差不多呢?按照上面来想,应该是一个mini-batch结束再来下一个,这样慢慢进行下去,其实没理由啊。接下来以batch_size = 2来介绍一下:
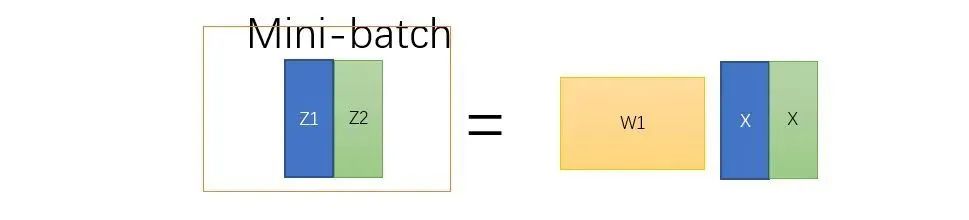
学过线性代数应该明白,可以将同维度的向量拼成矩阵,来进行矩阵运算,这样每一个mini-batch都在同一时间计算出来,即为平行运算
所有平行运算GPU都能进行加速。
那么,好奇的是到底计算机看到了什么?是一个一个的数字吗?

其实这件事情很反直觉,原以为计算机是看一张一张的图片,可是这个很难看出是单个数字而是数字集,那么我们试试看最大化像素。

其实左下角的6其实蛮像的耶。
参考
https://zh-v2.d2l.ai/
https://demo.leemeng.tw/
http://cs231n.stanford.edu/
https://www.youtube.com/watch?v=FrKWiRv254g&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49&index=19
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
