
ECCV 2022 | 在视觉Transformer上进行递归,不增参数,计算量还少
视学算法
共 2375字,需浏览 5分钟
· 2022-07-31
视学算法专栏
今天跟大家分享一篇来自CMU等机构的论文《Sliced Recursive Transformer》,该论文已被 ECCV 2022 接收。
目前 vision transformer 在不同视觉任务上如分类、检测等都展示出了强大的性能,但是其巨大的参数量和计算量阻碍了该模型进一步在实际场景中的应用。基于这个考虑,本文重点研究了如何在不增加额外参数量的前提下把模型的表达能力挖掘到极致,同时还要保证模型计算量在合理范围内,从而可以在一些存储容量小,计算能力弱的嵌入式设备上部署。
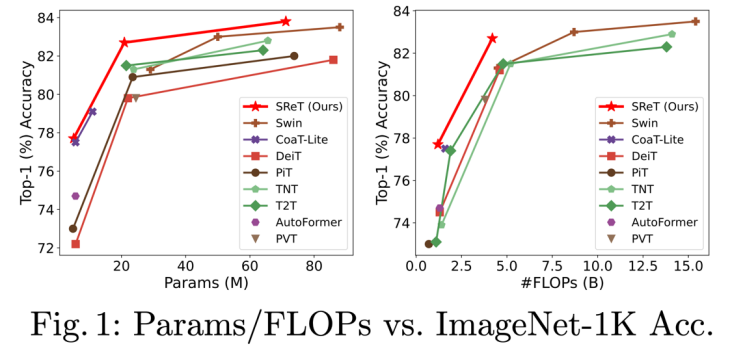
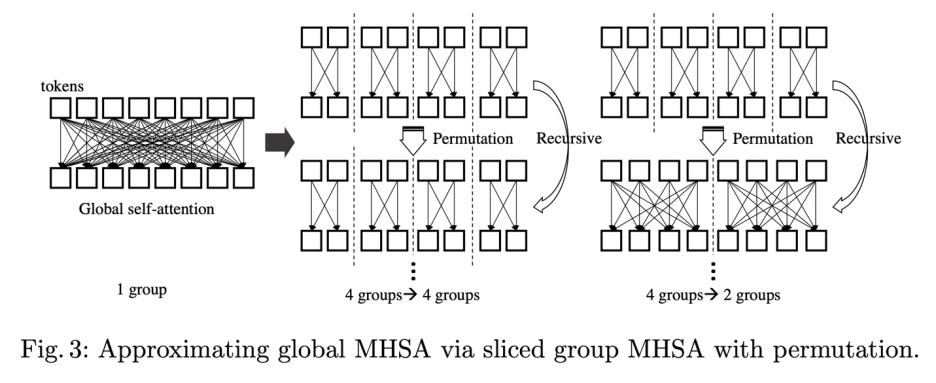
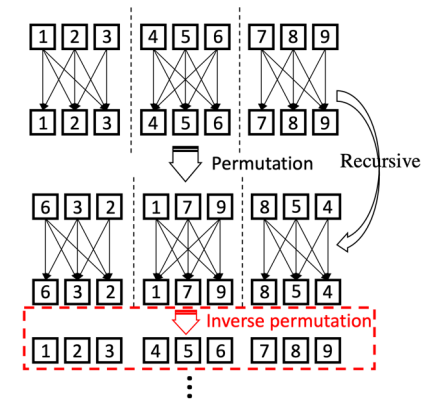
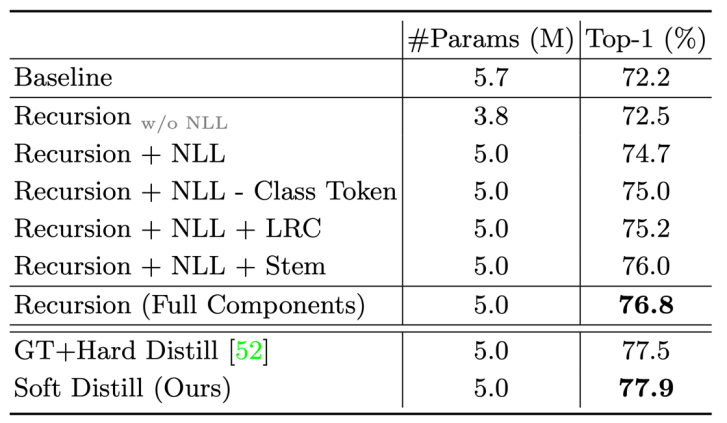
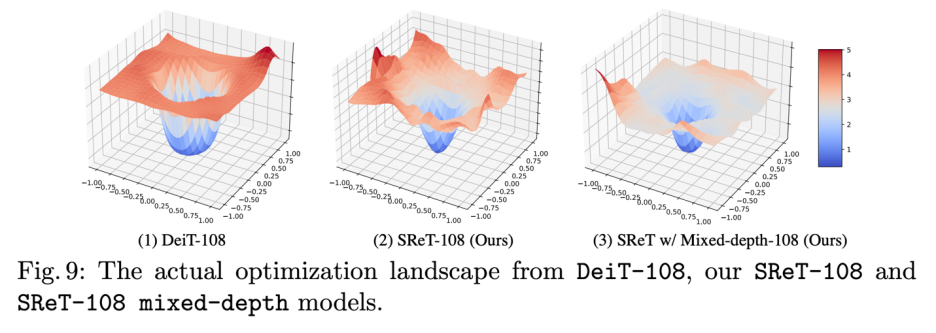
基于这个动机,Zhiqiang Shen、邢波等研究者提出了一个 SReT 模型,通过循环递归结构来强化每个 block 的特征表达能力,同时又提出使用多个局部 group self-attention 来近似 vanilla global self-attention,在显著降低计算量 FLOPs 的同时,模型没有精度的损失。

论文地址:https://arxiv.org/pdf/2111.05297.pdf 代码和模型:https://github.com/szq0214/SReT
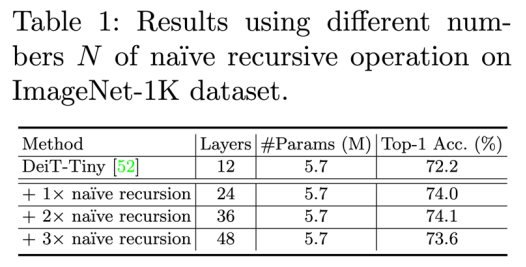
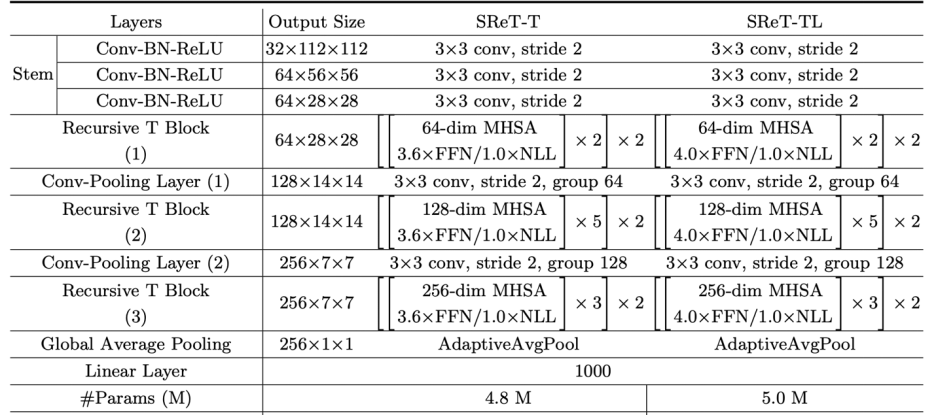
使用类似 RNN 里面的递归结构(recursive block)来构建 ViT 主体,参数量不涨的前提下提升模型表达能力; 使用 CNN 中 group-conv 类似的 group self-attention 来降低 FLOPs 的同时保持模型的高精度;
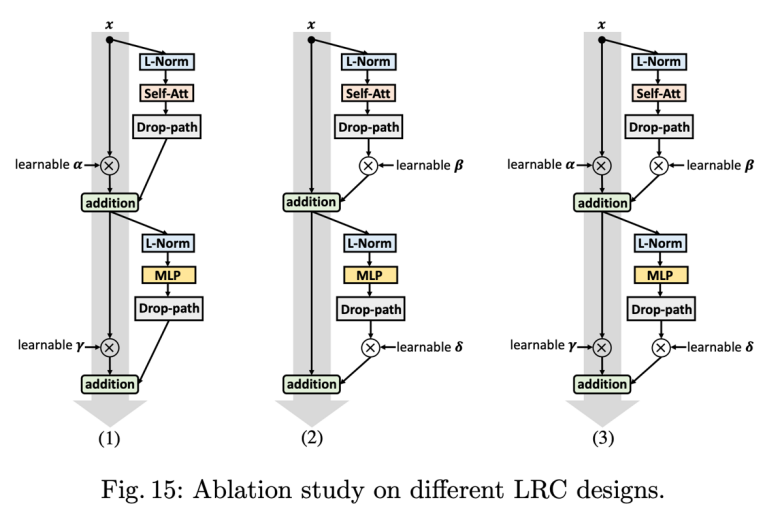
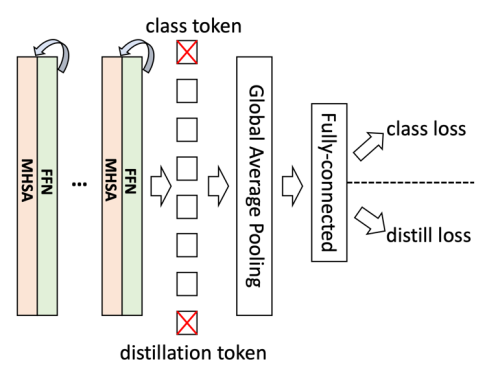
网络最前面使用三层连续卷积,卷积核为 3x3,结构直接使用了研究者之前 DSOD 里面的 stem 结构; Knowledge distillation 只使用了单独的 soft label,而不是 DeiT 里面 hard 形式的 label 加 one-hot ground-truth,因为研究者认为 soft label 包含的信息更多,更有利于知识蒸馏; 使用可学习的 residual connection 来提升模型表达能力;





© THE END
转载请联系原公众号获得授权

点个在看 paper不断!
评论
老爸嘲讽我了,写破代码一年就挣十几万,他在工地带50个工人,一个月光人头费就3万,让我滚回去跟他干!
点击上方 "大数据肌肉猿"关注, 星标一起成长点击下方链接,进入高质量学习交流群今日更新| 1052个转型案例分享-大数据交流群来自:网络,侵删有个网友的父亲是做工程的,天天就嘲笑他,说他天天写着破代码有啥用,一年就拿个十多万的死工资,然后告诉他自己在工地里面带了50个工人,一个月能抽三万
程序源代码
0
如何计算数据中心的冷却需求?
今日分享 【导读】数据中心的冷却要求受多种因素影响,包括设备的热量输出、占地面积、设施设计和电气系统功率额定值等等……众所周知,环境因素会严重影响数据中心设备。过多的热量积聚会损坏服务器,可能导致其自动关闭。经常在高于可接受的温度下运行服务器会缩短其使用
数据中心运维管理
0
BigDecimal 为什么可以保证精度不丢失?
来源:juejin.cn/post/7348709938023940136👉 欢迎加入小哈的星球 ,你将获得: 专属的项目实战 / Java 学习路线 / 一对一提问 / 学习打卡 / 赠书福利全栈前后端分离博客项目 2.0 版本完结啦, 演示链接
小哈学Java
0
聊一聊我最常关注的9个计算机视觉、自动驾驶、AI方向高质量圈子
随着计算机视觉(2D/3D)、SLAM、自动驾驶、AI技术的快速迭代更新,可落地的技术也成为人们争先学习的重点。这使得从业者对于最前沿技术的获取能力变得至关重要。微信公众号便是一个非常有效的前沿信息分享平台。这里给大家推荐9个最常打开的计算机视觉、自动驾驶、SLAM、机器学习和AI方向的优质公众号平
机器学习初学者
0
新规!不授予学位!博士毕业更难了?
来源:阿秒富友研究院编辑:学妹据4月22日科技日报消息,全国人大常委会法工委发言人杨合庆在近日举行的记者会上表示,即将提请十四届全国人大常委会第九次会议审议的学位法草案二次审议稿将进一步完善学位授予条件和程序,并对保障博士学位质量作出专门规定。杨合庆介绍,2023年8月,十四届全国人大常委会第五次会
机器学习初学者
0
GPT的风也吹到了CV,详解自回归视觉模型的先驱! ImageGPT:使用图像序列训练图像 GPT模型
作者丨科技猛兽编辑丨极市平台导读 在 CIFAR-10 上,iGPT 使用 linear probing 实现了 96.3% 的精度,优于有监督的 Wide ResNet,并通过完全微调实现了 99.0% 的精度,匹配顶级监督预训练模型。本文目录1 自回归视觉模型的先驱 ImageGPT:
机器学习初学者
0
面试官:在原生input上面使用v-model和组件上面使用有什么区别?
前言面试官:vue3的v-model都用过吧,来讲讲。粉丝:v-model其实就是一个语法糖,在编译时v-model会被编译成:modelValue属性和@update:modelValue事件。一般在子组件中定义一个名为modelValue的props来接收父组件v-model传递的值,然后当子组
高级前端进阶
0
特斯拉中国Model Y、S、X全系降价;盒马否认侯毅张勇出价20亿美元联手买下盒马;瑞幸回应“不招聘上海人”
特斯拉中国Model Y、S、X全系降价特斯拉中国Model Y售价降至24.99万元人民币,MODEL Y长续航版售价降至29.09万元人民币。特斯拉中国 MODEL Y高性能版售价降至35.49万元人民币。特斯拉中国MODEL S售价降至68.49万元人民币。特斯拉中国 MODEL S PLAI
亿欧网
0