
综述:光流估计从传统方法到深度学习
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
作者丨肖泽东 Shon@知乎
来源丨https://zhuanlan.zhihu.com/p/74460341
编辑丨目标检测与深度学习
编者荐语
光流估计是计算机视觉研究中的一个重要方向,然而,因为其不容易在应用中“显式”地呈现,而未被大众熟知。随着计算机视觉学界从图像理解转向视频理解,互联网用户从发布图片朋友圈转向发布短视频,人们对视频的研究和应用的关注不断增强。
1.摘要
近年来,深度学习技术,作为一把利剑,广泛地应用于计算机视觉等人工智能领域。如今时常见诸报端的“人工智能时代”,从技术角度看,是“深度学习时代”。
光流估计作为视频理解的隐形战士,等着我们去寻找其踪迹。
本文首先介绍了什么是视频光流估计;再介绍光流估计的算法原理,包括最为经典的Lucas-Kanade算法和深度学习时代光流估计算法代表FlowNet/FlowNet2;
最后,介绍了视频光流估计的若干应用。希望对光流估计的算法和应用有个较为全面的介绍。
2.介绍
光流,顾名思义,光的流动。比如人眼感受到的夜空中划过的流星。在计算机视觉中,定义图像中对象的移动,这个移动可以是相机移动或者物体移动引起的。具体是指,视频图像的一帧中的代表同一对象(物体)像素点移动到下一帧的移动量,使用二维向量表示。如图2-1。
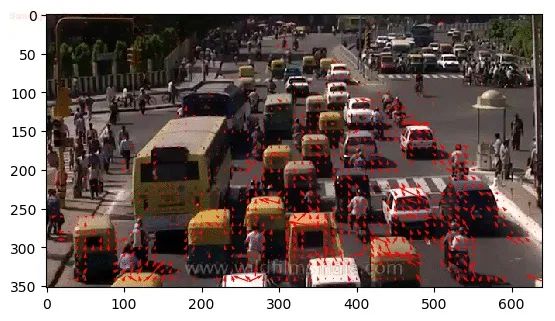
图2-1 光流示意图
根据是否选取图像稀疏点进行光流估计,可以将光流估计分为稀疏光流和稠密光流,如图2,左图选取了一些特征明显(梯度较大)的点进行光流估计和跟踪,右图为连续帧稠密光流示意图。

图2-2 左图 稀疏点光流,右图 稠密光流
稠密光流描述图像每个像素向下一帧运动的光流,为了方便表示,使用不同的颜色和亮度表示光流的大小和方向,如图2-2右图的不同颜色。图2-3展示了一种光流和颜色的映射关系,使用颜色表示光流的方向,亮度表示光流的大小。
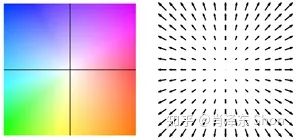
图2-3 稠密光流表示颜色空间
3.算法
最为常用的视觉算法库OpenCV中,提供光流估计算法接口,包括稀疏光流估计算法cv2.calcOpticalFlowPyrLK(),和稠密光流估计cv2.calcOpticalFlowFarneback()。
其中稀疏光流估计算法为Lucas-Kanade算法,该算法为1981年由Lucas和Kanade两位科学家提出的,最为经典也较容易理解的算法,下文将以此为例介绍传统光流算法。
对于最新的深度学习光流估计算法,FlowNet的作者于2015年首先使用CNN解决光流估计问题,取得了较好的结果,并且在CVPR2017上发表改进版本FlowNet2.0,成为当时State-of-the-art的方法。
截止到现在,FlowNet和FlowNet2.0依然和深度学习光流估计算法中引用率最高的论文,分别引用790次和552次。因此,深度学习光流估计算法将以FlowNet/FlowNet2.0为例介绍。
3.1 传统算法 Lucas-Kanade
为了将光流估计进行建模,Lucas-Kanade做了两个重要的假设,分别是亮度不变假设和邻域光流相似假设。
3.1.1 亮度不变假设

图3-1-1 - Lucas-Kanade 亮度不变假设
亮度不变假设如图3-1-1,假设待估计光流的两帧图像的同一物体的亮度不变,这个假设通常是成立的,因为环境光照通常不会发生太大的变化。假设  时刻,位于
时刻,位于  像素位置的物体,在
像素位置的物体,在  时刻位于
时刻位于  位置,基于亮度不变假设,有:
位置,基于亮度不变假设,有:

将等式右边进行一阶泰勒展开得:

即有:

写成矩阵形式有:

其中,  分别为 像素点处图像亮度在x方向和y方向的偏导数,即图像x和y方向的梯度。
分别为 像素点处图像亮度在x方向和y方向的偏导数,即图像x和y方向的梯度。  为t时刻, 处像素亮度对时间的导数,
为t时刻, 处像素亮度对时间的导数,  即为两图之间的 坐标位置的亮度差,表示为
即为两图之间的 坐标位置的亮度差,表示为  。即:
。即:

给定两张图像,  均为已知量,
均为已知量,  即为待求的光流。式(3-1-5)中建立了一个等式,存在两个未知数( ),无法得到唯一解。因此,需要借助邻域光流相似假设。
即为待求的光流。式(3-1-5)中建立了一个等式,存在两个未知数( ),无法得到唯一解。因此,需要借助邻域光流相似假设。
3.1.2 邻域光流相似假设
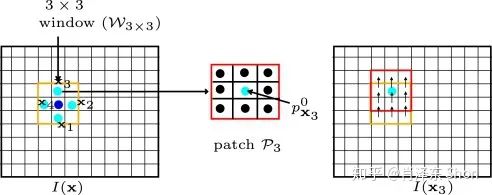
图3-1-2 - 领域光流相似假设
邻域光流相似假设如图3-1-2,以像素点 为中心,设定3x3的邻域(以3x3举例,也可以是其他的大小),假设该邻域内的所有像素点光流值一致,通常,一个小的图像区域里像素移动方向和大小是基本一致的,因此,这个假设也是合理的。借助该假设,领域内的所有像素都有式(3-1-5),得:

上式即为  的形式,可求得光流
的形式,可求得光流  的最小二乘解:
的最小二乘解:

其中,要求  可逆,如果 不可逆,式3-1-6将出现多解,即出现孔径问题(Aperture Problem),如图3-1-3,从圆孔中观察三种移动的条纹的变化,是一致的,从而无法通过圆孔得到条纹的真实移动方向(光流方向)。
可逆,如果 不可逆,式3-1-6将出现多解,即出现孔径问题(Aperture Problem),如图3-1-3,从圆孔中观察三种移动的条纹的变化,是一致的,从而无法通过圆孔得到条纹的真实移动方向(光流方向)。
因此,Lucas-Kanade方法将选取一些 可逆的像素点估计光流,这些点是一些亮度变化明显的角点,知名的角点检测算法Harris角点检测算法正是借助了 可逆的相关性质。
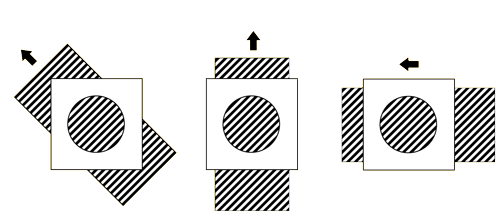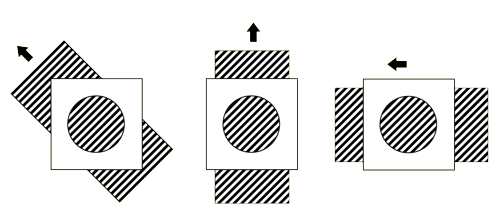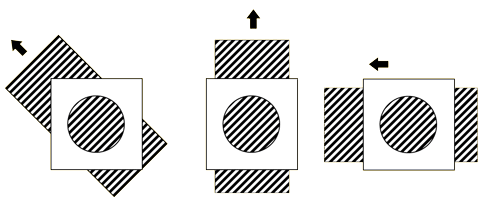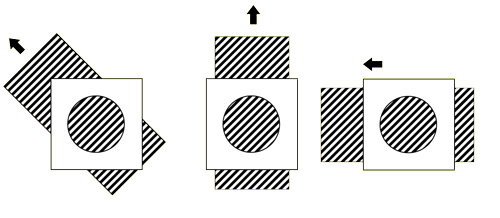
图3-1-3 光流求解的孔径问题
除了基于亮度不变假设和邻域光流相似假设,为了解决图像偏移较大的情况,Lucas-Kanade算法还借助了图像金字塔(Pyramid)的方式,在高层低分辨率图像上,大的偏移将变为小的偏移。最终,Lucas-Kanade方法给出了一种求解稀疏(明显特征的角点)光流的方法。
3.2 深度学习算法 FlowNet/FlowNet2.0
ICCV2015提出的FlowNet是最早使用深度学习CNN解决光流估计问题的方法,并且在CVPR2017,同一团队提出了改进版本FlowNet2.0。FlowNet2.0 是2015年以来光流估计邻域引用最高的论文。
3.2.1 FlowNet
作者尝试使用深度学习End-to-End的网络模型解决光流估计问题,如图3-2-1,该模型的输入为待估计光流的两张图像,输出即为图像每个像素点的光流。我们从Loss的设计,训练数据集和网络设计来分析FlowNet。
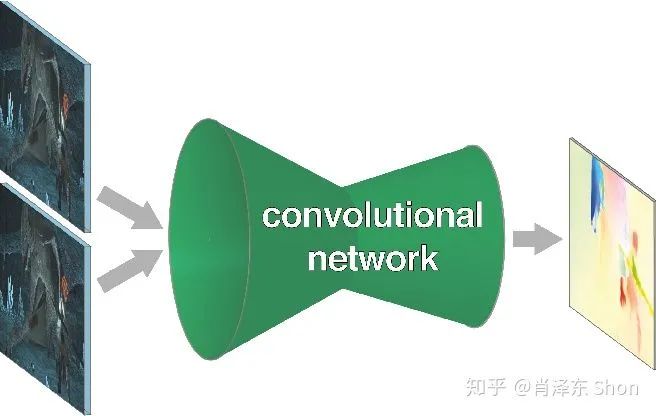
图3-2-1 深度学习End-to-End 光流估计模型
对于Loss的设计,如果给定每个像素groundtruth的光流,那么对于每个像素,loss可以定义为预测的光流(2维向量)和groundtruth之间的欧式距离,称这种误差为EPE(End-Point-Error),如图
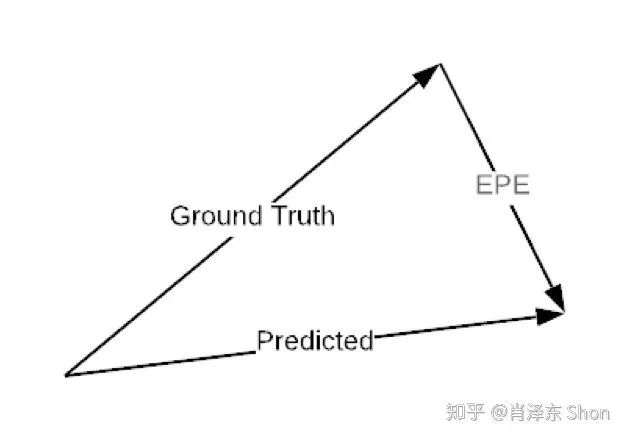
图3-2-2 End Point Error
对于训练数据集,由于稠密光流的groundtruth为图像每个像素的光流值,人工标注光流值几乎不可能。
因此,作者设计了一种生成的方式,得到包括大量样本的训练数据集FlyingChairs。其生成方式为对图像做仿射变换生成对应的图像。为了模拟图像中存在多种运动,比如相机在移动,同时图像中的人或物体也在移动。作者将虚拟的椅子叠加到背景图像中,并且背景图和椅子使用不同的仿射变换得到对应的另一张图,如图3-2-3。

图3-2-3 FlyingChairs数据集生成
对于深度网络结构,该类网络通常包括降维的encoder模块和升维的decoder模块。作者设计了两种网络,FlowNetSimple和FlowNetCorr(Correlation)。这两种网络的Encoder模块不同,Decoder模块相同。
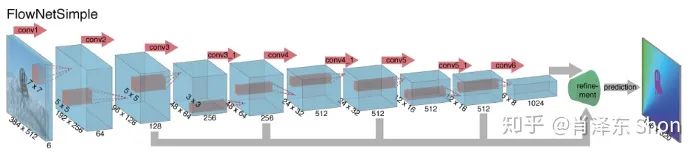
图3-2-4 FlowNetSimple
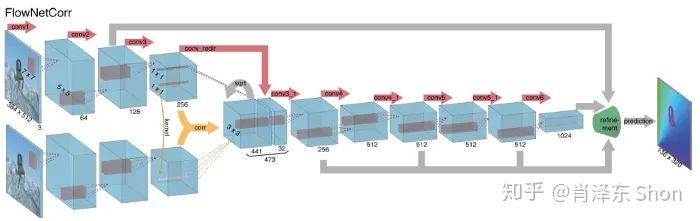
图3-2-5 FlowNetCoor
FlowNetSimple简单地将两张图排列到一起,即将两张  图,合并成
图,合并成  的Tensor,作为CNN encoder的输入(如图3-2-4),这是最为简单的将两张图的信息整合到一起的方式,也因此命名为FlowNetSimple。FlowNetCoor则先对两张图像分别进行卷积,获得较为高层的feature后,再进行相关运算(引入人为定义的规则),将信息合并,如图3-2-5。
的Tensor,作为CNN encoder的输入(如图3-2-4),这是最为简单的将两张图的信息整合到一起的方式,也因此命名为FlowNetSimple。FlowNetCoor则先对两张图像分别进行卷积,获得较为高层的feature后,再进行相关运算(引入人为定义的规则),将信息合并,如图3-2-5。
其中,相关运算借鉴了传统视觉算法中,找图像匹配的思想。如图3-2-6,为了寻找上图红框椅子角在下图中对应得位置,在下图对应像素位置周围依次滑动,做相关运算(即对应位置像素相乘求和)。得到的值越大,代表越相关,即图像越接近。
FlowNetCoor网络中的相关运算类似,不同点是其不在图像本身做相关,在卷积得到的FeatureMap上做相关运算,图3-2-6上图FeatureMap与下图FeatureMap对应像素附近区域做相关,上图(u,v)坐标图块与下图对应区域的邻域内(绿框)滑动做相关运算,得到的值在输出FeatureMap通道方向上依次排开,图3-2-4中相关运算的输出通道数为441,即下图做相关运算的邻域范围为  。
。

图3-2-6 相关运算示意图
两种网络的Decoder是一致的(见图3-2-7),其通过反卷积进行升维,各层反卷积运算的输入包括三个部分,第一部分是上一层的反卷积输出deconv*(高层语义信息),第二部分来之Encoder相关层的FeatureMap conv*_1(低层局部信息),第三部分由前一层卷积的输出coarse的光流flow*上采样得到。从而融合了高层和低层的信息,也引入了coarse-to-fine(由粗到细)的机制。
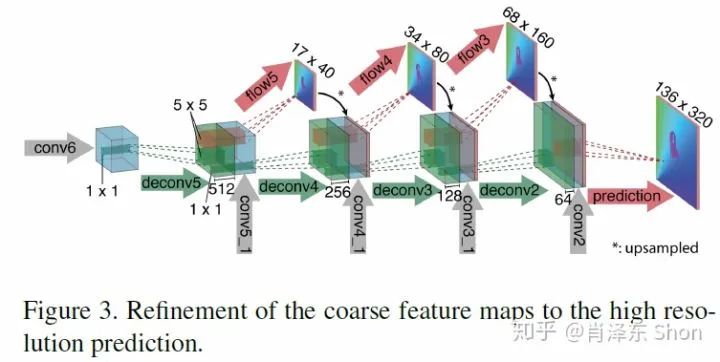
图3-2-7 Decoder网络结构
基于上述网络和训练集,作者基于深度学习设计的FlowNet在实时估计光流算法中取得了state-of-the-art的结果,但是依然比非实时的传统方法效果要差。同时,作者对比了FlowNetS和FlowNetCoor,FlowNetCoor的效果更好,证实了人工加入的相关运算是有效的,也符合预期。
3.2.2 FlowNet2.0
FlowNet2.0是FlowNet团队发表在CVPR2017的改进方法,该方法达到了state-of-the-art效果(包括非实时的传统方法),并且计算速度很快,达到实时的要求。FlowNet2.0的改进主要体现在两个方面,一方面是通过堆叠多个FlowNet网络,实现Coarse-to-Fine的效果;另一方面是解决FlowNet小偏移(Small Displacement)估计不准确的问题。FlowNet2.0整体网络结构如图3-2-8,图上方依次堆叠了FlowNetCoor+FlowNetS+FlowNetS。
值得注意的是,后续FlowNet的输入不仅仅是两张图片(图1和图2),还包括前一个网络输入的光流估计Flow,和一张Warped图,再加一张亮度误差(Brightness Error)。
其中Warped图为将估计的光流作用在图2上,即为使用估计的每个像素偏移,偏移图2的每一个像素,使其与图1对齐。虽然作用了光流偏移,由于光流估计的不够准确,Warped图和图1依然存在一定的偏差,图1的亮度减去Warped图的亮度,即可得到亮度误差(BrightnessError)图。
最后,将所有的五项输入堆叠成输入的Tensor,输入到后续的网络中。小偏移即光流偏移较小的情形,作者设计了适合小偏移的FlowNet-SD(Small-Displacement),其修改FlowNet中卷积核和stride的大小,使其更适合小偏移。具体的变化为,将FlowNet中7x7和5x5的卷积和改为3x3的卷积核(更小的卷积和意味着更加精细的处理,因此更加适合小偏移估计的问题),并且将stride=2改为stride=1。
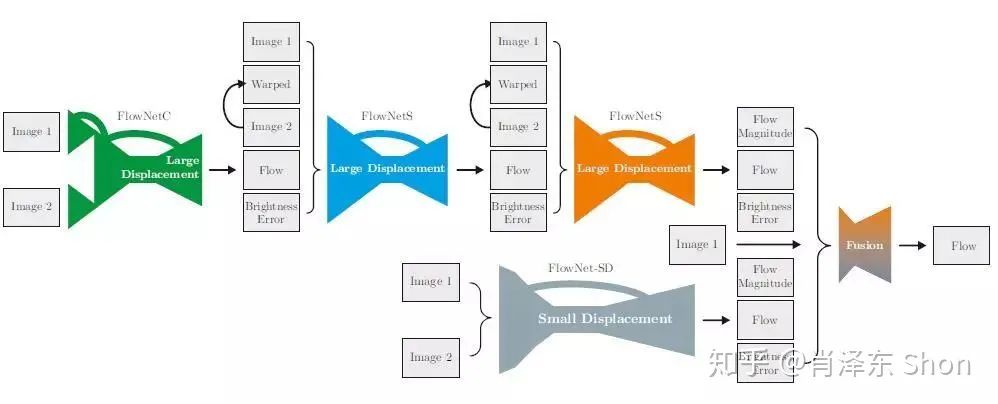
图3-2-8 FlowNet2.0 整体框图
作者给出的FlowNet2.0实验结果如图3-2-9,其中给出了5种版本的FlowNet2,FlowNet2、FN2-CSS-ft-sd/FN2-css-ft-sd、FN2-ss、FN2-s, c/C代表Coor网络,s/S代表Simple网络,小写(s,c)代表网络参数较少(缩小了卷积和数量)的版本。FlowNet2是指FlowNet2的完整网络(如图3-2-8),ft代表在真实数据集上进行了fine-tune,sd代表包含small-displacement模块。
因此,实验结果表明FlowNet2达到了所有方法State-of-the-are结果(包括非实时的传统方法),计算效率要比最好的传统方法快两个数量级,达到了实时的要求。并且根据不同的应用需求,不同速度和精度的要求,有不同的版本供选择。
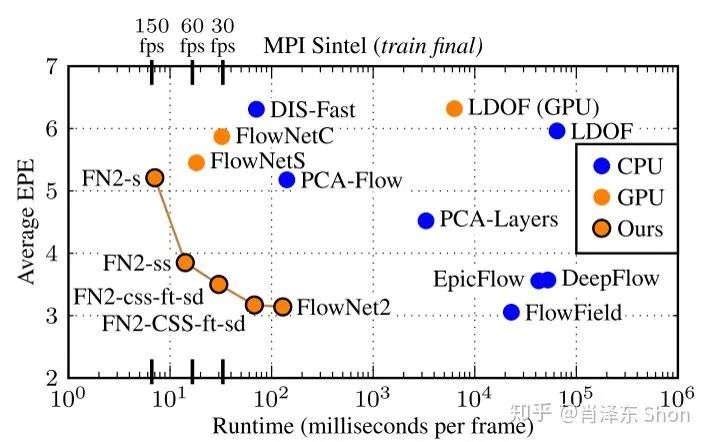
图3-2-9 FlowNet2.0 对比结果
4.应用
光流,从物理意义的角度看,描述了视频中物体、对象在时间维度上的关联性,从而建立了视频中连续图像之间的关联关系。
因此,最为直接而自然的应用就是视频中物体的跟踪,在物体跟踪领域知名的TLD算法便借助了光流估计,图2中展示了在车辆上的特征点光流跟踪的效果。在视觉里程计和SLAM同步定位与建图领域,光流可以作为图像特征点匹配的一种方式,比如知名的视觉惯性里程计开源算法VINS-Mono。英伟达也提供了基于其GPU的光流SDK,其中展示了利用光流进行视频动作识别(video action recognition)和视频插帧的应用,如图4-1,4-2。
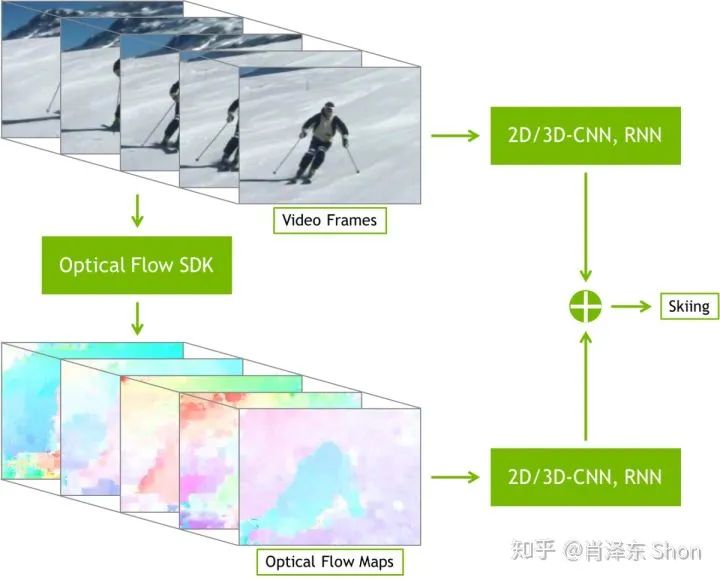
图4-1 光流应用于动作识别
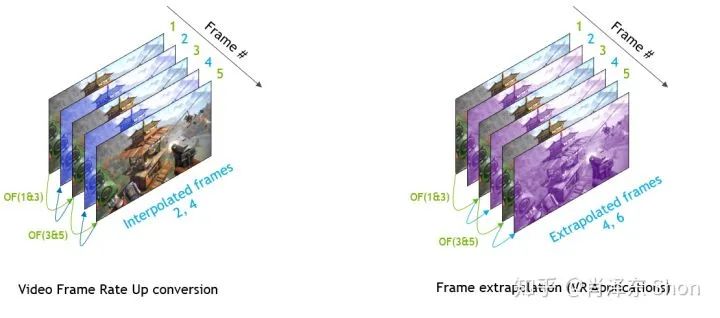
图4-2 光流应用于视频插帧
5.总结
对于稀疏光流,本文提到的Lucas-Kanade是一种经典且有效的算法,对于稠密光流估计,传统方法需要在精度和速度上做出取舍,而基于深度学习的FlowNet2算法可以实时取得state-of-the-art的精度。
参考文献
[1] Ilg, Eddy, et al. "Flownet 2.0: Evolution of optical flow estimation with deep networks."Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[2] Dosovitskiy, Alexey, et al. "Flownet: Learning optical flow with convolutional networks."Proceedings of the IEEE international conference on computer vision. 2015.
[3] NVIDIA Optical Flow SDK developer.nvidia.com/op , Accessed at 2019/7/20
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
—THE END—