
Flink 实践 | Flink 通过 State Processor API 实现状态的读取和写入
大家好,我是 JasonLee。
在 1.9 版本之前,Flink 运行时的状态对于用户来说是一个黑盒,我们是无法访问状态数据的,从 Flink-1.9 版本开始,官方提供了 State Processor API 这让用户读取和更新状态成为了可能,我们可以通过 State Processor API 很方便的查看任务的状态,还可以在任务第一次启动的时候基于历史数据做状态冷启动。从此状态对于用户来说是透明的。下面就来看一下 State Processor API 的使用。
添加依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-state-processor-api_2.11artifactId>
<version>1.14.4version>
dependency>
Mapping Application State to DataSets
State Processor API 将流应用程序的状态映射到一个或多个可以单独处理的数据集。为了能够使用 API,我们先来理解一下任务的状态和 DataSets 之间是如何映射的。
让我们先看看有状态的 Flink 作业是什么样子的。Flink 作业由多个算子组成,通常有一个或多个 source 数据源,一些用于实际处理数据的算子,以及一个或多个 sink 算子。每个算子并行的在一个或多个 task 上运行,并且可以处理不同类型的状态。一个算子可以有 0、1 个或多个 operator states,这些状态被组织成 list,作用于所有的 tasks 上。如果 operator 应用于 keyed states,它还可以有 0 个、1 个或多个 keyed state,这些状态的作用域为从每个 record 中提取的 key。
下图显示了应用程序 MyApp,它由 Src、Proc 和 Snk 三个算子组成。Src 有一个 operator state 状态(os1), Proc 有一个 operator 状态(os2) 和两个 keyed state 状态(ks1, ks2),而 Snk 是无状态的。

MyApp 的 SavePoint 或 CheckPoint 由所有的状态数据组成,以便可以恢复每个 task 的状态。在使用 batch 作业处理保存点(或检查点)的数据时,我们需要将各个任务状态的数据映射到数据集或表中的心智模型。实际上,我们可以将保存点视为数据库。每个 operator(由其UID标识)代表 namespace。每一个算子的 operator state 在 namespace 里都映射到一个固定的表里,其中有一列包含所有 task 的状态数据。一个算子的所有 keyed state 都映射到由 key 的列组成的单个表,以及另外一列对应每一个 keyed state。下图显示了MyApp 的保存点如何映射到数据库。
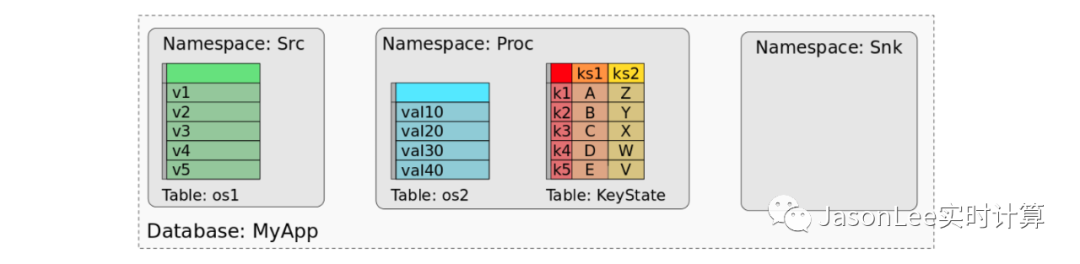
该图显示了 Src 的 operator state 的值是如何映射到一个表的,该表有一列和五行,每一行代表 Src 的所有并行任务中的每个列表条目。算子 Proc 的 operator state(os2) 类似地映射到单个表。keyed state ks1 和 ks2 合并到一个包含三列的表中,一列表示 key,一列用于 ks1,一列用于 ks2。这个 keyed table 为两个 keyed state 的每个不同 key 保存一行。因为算子 Snk 没有任何状态,所以它的 namespace 是空的。
Reading State
读取状态首先需要指定一个有效的 savepoint 或 checkpoint 的路径,以及应该用于恢复数据的 StateBackend。恢复状态的兼容性保证与恢复 DataStream 应用程序时相同。
ExecutionEnvironment bEnv = ExecutionEnvironment.getExecutionEnvironment();
ExistingSavepoint savepoint = Savepoint.load(bEnv, "hdfs://path/", new HashMapStateBackend());
读取状态时支持三种不同类型的状态:
Operator State
Keyed State
Window State
Writing New Savepoints
也可以编写 Savepoints,它允许这样的用例,如基于历史数据的启动状态。每个 Savepoints 由一个或多个 BootstrapTransformation(下面会解释)组成,每个 BootstrapTransformation 都定义了单个算子的状态。
❝注意:state processor api 当前未提供 Scala API。因此,它将始终使用 Java 类型堆栈自动推断出序列化器。要为 Scala Datastream API 启动 savepoint 请在所有类型信息中手动传递。
❞
初始化状态时支持四种不同类型的状态:
Operator State
Broadcast State
Keyed State
Window State
Modifying Savepoints
除了从临时创建一个 savepoint 外,你还可以基于现有的 Savepoints,当为现有作业启动单个新的算子时。
Savepoint
.load(bEnv, oldPath, new HashMapStateBackend())
.withOperator("uid", transformation)
.write(newPath);
Read And Write State Demo
下面就来实现一下我们平时使用最多的 Keyed State 状态的读取和写入。
Read State
package flink.state;
import bean.Jason;
import bean.UserDefinedSource;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class FlinkStreamingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 设置任务的最大并行度 也就是keyGroup的个数
env.setMaxParallelism(128);
//env.getConfig().setAutoWatermarkInterval(1000L);
// 设置开启checkpoint
env.enableCheckpointing(10000L);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage("file:///Users/jasonlee/flink-1.14.0/checkpoint");
// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
DataStreamSource dataStreamSource = env.addSource(new UserDefinedSource());
dataStreamSource.keyBy(k -> k.getName())
.process(new KeyedProcessFunction() {
private ValueState state;
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor stateDescriptor = new ValueStateDescriptor<>("state", Types.INT);
state = getRuntimeContext().getState(stateDescriptor);
}
@Override
public void processElement(Jason value, KeyedProcessFunction.Context ctx, Collector out) throws Exception {
if (state.value() != null) {
System.out.println("状态里面有数据 :" + state.value());
value.setAge(state.value() + value.getAge());
state.update(state.value() + value.getAge());
} else {
state.update(value.getAge());
}
out.collect(value);
}
}).uid("my-uid")
.print("local-print");
env.execute();
}
}
代码非常简单,里面只用了一个 ValueState,来保存用户的 age ,key 是 name。要为带状态的算子设置唯一的 uid("my-uid"),在读取状态的时候需要指定算子的 uid。
先把这个任务跑起来,然后只要任务 checkpoint 做成功就可以把任务停掉了。
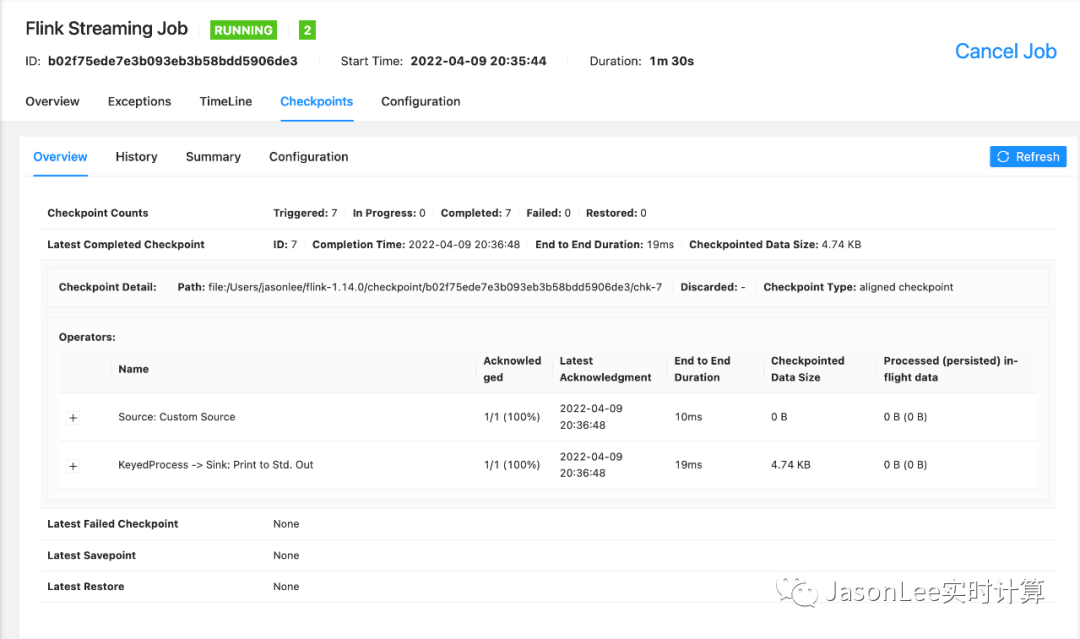
然后来看一下生成的 ck 文件。

可以看到做了 10 次 ck,那这里我们就来读取 chk-10 这个 ck 里面的状态。
读取和写入状态的代码如下:
package flink.state;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.state.api.BootstrapTransformation;
import org.apache.flink.state.api.ExistingSavepoint;
import org.apache.flink.state.api.OperatorTransformation;
import org.apache.flink.state.api.Savepoint;
import org.apache.flink.state.api.functions.KeyedStateBootstrapFunction;
import org.apache.flink.state.api.functions.KeyedStateReaderFunction;
import org.apache.flink.util.Collector;
import java.util.Arrays;
import java.util.Collection;
import java.util.List;
public class FlinkReadAndUpdateState {
private static final String ckPath = "file:///Users/jasonlee/flink-1.14.0/checkpoint/b02f75ede7e3b093eb3b58bdd5906de3/chk-10";
private static final Collection data =
Arrays.asList(new KeyedState("hive", 1), new KeyedState("JasonLee1", 100), new KeyedState("hhase", 3));
public static void main(String[] args) throws Exception {
stateRead(ckPath);
//stateWrite("");
}
/**
* 从 ck 读取状态数据
* @param ckPath
* @throws Exception
*/
public static void stateRead(String ckPath) throws Exception {
ExecutionEnvironment bEnv = ExecutionEnvironment.getExecutionEnvironment();
bEnv.setParallelism(1);
ExistingSavepoint savepoint = Savepoint.load(bEnv, ckPath, new HashMapStateBackend());
DataSet keyedState = savepoint.readKeyedState("my-uid", new ReaderFunction());
List keyedStates = keyedState.collect();
for (KeyedState ks: keyedStates) {
System.out.println(String.format("key: %s, value: %s", ks.key, ks.value));
}
}
/**
* 初始化状态数据
* @param ckPath
*/
public static void stateWrite(String ckPath) throws Exception {
int maxParallelism = 128;
ExecutionEnvironment bEnv = ExecutionEnvironment.getExecutionEnvironment();
DataSet dataKeyedState = bEnv.fromCollection(data);
BootstrapTransformation transformation = OperatorTransformation
.bootstrapWith(dataKeyedState)
.keyBy(k -> k.key)
.transform(new WriterFunction());
Savepoint
.create(new HashMapStateBackend(), maxParallelism)
.withOperator("uid-test", transformation)
.write("file:///Users/jasonlee/flink-1.14.0/checkpoint/init_state");
bEnv.execute();
}
public static class WriterFunction extends KeyedStateBootstrapFunction<String, KeyedState> {
ValueState state;
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor stateDescriptor = new ValueStateDescriptor<>("state", Types.INT);
state = getRuntimeContext().getState(stateDescriptor);
}
@Override
public void processElement(KeyedState value, KeyedStateBootstrapFunction.Context ctx) throws Exception {
state.update(value.value);
}
}
public static class ReaderFunction extends KeyedStateReaderFunction<String, KeyedState> {
ValueState state;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor stateDescriptor = new ValueStateDescriptor<>("state", Types.INT);
state = getRuntimeContext().getState(stateDescriptor);
}
@Override
public void readKey(
String key,
Context ctx,
Collector out) throws Exception {
KeyedState data = new KeyedState();
data.key = key;
data.value = state.value();
out.collect(data);
}
}
public static class KeyedState {
public String key;
public int value;
public KeyedState(String key, int value) {
this.key = key;
this.value = value;
}
public KeyedState() {}
}
}
这里读取和写入状态的代码放到一起了,只需调用 savepoint 的 readKeyedState 方法指定一下上面代码里面设置的 uid,还需要继承 KeyedStateReaderFunction 实现 readKey 方法就可以了。代码比较简单,这里就不在多说。直接来看一下读取的结果。
执行这个代码,打印的状态数据如下:
key: JasonLee35, value: 35
key: JasonLee66, value: 66
key: JasonLee81, value: 81
key: JasonLee74, value: 74
key: JasonLee90, value: 90
key: JasonLee36, value: 36
key: JasonLee85, value: 85
key: JasonLee39, value: 39
key: JasonLee72, value: 72
key: JasonLee65, value: 65
key: JasonLee58, value: 58
key: JasonLee9, value: 9
key: JasonLee69, value: 69
key: JasonLee82, value: 82
key: JasonLee53, value: 53
key: JasonLee6, value: 6
key: JasonLee79, value: 79
key: JasonLee32, value: 32
key: JasonLee64, value: 64
key: JasonLee76, value: 76
key: JasonLee91, value: 91
key: JasonLee18, value: 18
key: JasonLee26, value: 26
key: JasonLee40, value: 40
key: JasonLee25, value: 25
key: JasonLee54, value: 54
key: JasonLee21, value: 21
key: JasonLee55, value: 55
key: JasonLee78, value: 78
key: JasonLee71, value: 71
key: JasonLee42, value: 42
key: JasonLee56, value: 56
key: JasonLee17, value: 17
key: JasonLee88, value: 88
key: JasonLee61, value: 61
key: JasonLee27, value: 27
key: JasonLee41, value: 41
key: JasonLee12, value: 12
key: JasonLee63, value: 63
key: JasonLee5, value: 5
key: JasonLee73, value: 73
key: JasonLee67, value: 67
key: JasonLee29, value: 29
key: JasonLee31, value: 31
key: JasonLee14, value: 14
key: JasonLee92, value: 92
key: JasonLee7, value: 7
key: JasonLee45, value: 45
key: JasonLee48, value: 48
key: JasonLee11, value: 11
key: JasonLee75, value: 75
key: JasonLee84, value: 84
key: JasonLee13, value: 13
key: JasonLee77, value: 77
key: JasonLee59, value: 59
key: JasonLee83, value: 83
key: JasonLee15, value: 15
key: JasonLee37, value: 37
key: JasonLee52, value: 52
key: JasonLee30, value: 30
key: JasonLee62, value: 62
key: JasonLee34, value: 34
key: JasonLee19, value: 19
key: JasonLee87, value: 87
key: JasonLee86, value: 86
key: JasonLee38, value: 38
key: JasonLee57, value: 57
key: JasonLee10, value: 10
key: JasonLee49, value: 49
key: JasonLee46, value: 46
key: JasonLee8, value: 8
key: JasonLee28, value: 28
key: JasonLee2, value: 2
key: JasonLee89, value: 89
key: JasonLee16, value: 16
key: JasonLee24, value: 24
key: JasonLee50, value: 50
key: JasonLee3, value: 3
key: JasonLee51, value: 51
key: JasonLee44, value: 44
key: JasonLee47, value: 47
key: JasonLee33, value: 33
key: JasonLee68, value: 68
key: JasonLee22, value: 22
key: JasonLee80, value: 80
key: JasonLee20, value: 20
key: JasonLee23, value: 23
key: JasonLee1, value: 1
key: JasonLee70, value: 70
key: JasonLee60, value: 60
key: JasonLee4, value: 4
key: JasonLee43, value: 43
可以看到这个就是我们写入的状态数据。
然后再来测试一下初始化状态数据,跟读取状态刚好相反,我们需要先写入一个状态到指定的路径。然后在指定这个状态路径启动任务。
运行上面写入的代码,会在 /Users/jasonlee/flink-1.14.0/checkpoint/init_state 路径下面生成一个 _metadata 文件。来看一下生成的文件。

这里我读取状态和写入状态用的是同一个算子,也就是上面的 KeyedProcessFunction 算子,注意在恢复状态的时候需要把算子的 uid 改成和 .withOperator("uid-test", transformation) 参数保持一致。
然后就可以 通过下面的命令指定 ck 启动任务。
flink run -d -m yarn-cluster \
-Dyarn.application.name=FlinkStreamingNewDemoHome \
-Dyarn.application.queue=flink \
-Dmetrics.reporter.promgateway.groupingKey="jobname=FlinkStreamingNewDemoHome" \
-Dmetrics.reporter.promgateway.jobName=FlinkStreamingNewDemoHome \
-c flink.state.FlinkStreamingDemo \
-Denv.java.opts="-Dflink_job_name=FlinkStreamingNewDemoHome" \
-s hdfs:///flink-rockdb/checkpoints/init_state/_metadata \
/home/jason/bigdata/jar/flink-1.14.x-1.0-SNAPSHOT.jar
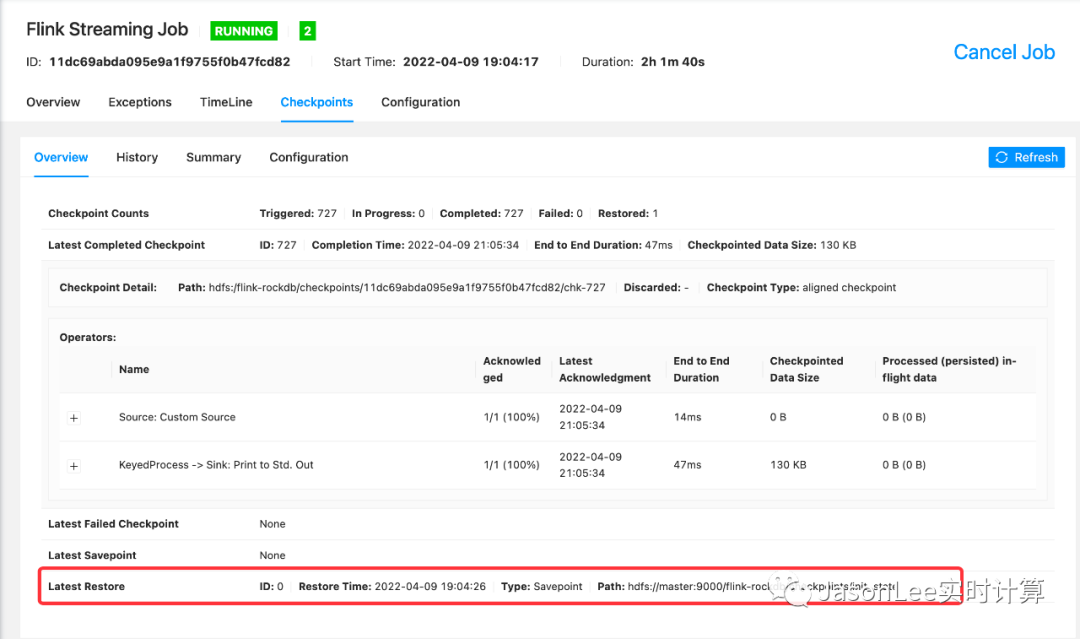
从上图可以看出任务确实是从我们指定的 ck 恢复的,这里其实和指定 checkpoint 或 savepoint 恢复任务是一样的,可以再来看一下 TM 里我们在代码里面打印的日志。

因为我们初始化了 JasonLee1 100 所以从状态里面读取出来的是 100 然后第一条数据的 age 是 1 所以打印的 JasonLee1 101 是没问题的。整个读取和写入状态的流程就结束了,其他类型的状态这里就不在演示,用法基本都是一样的。实际使用的时候根据场景选择不同类型的状态就可以了。
总结
State Processor API 提供了状态的读取写入以及修改的功能,从此状态对于用户来说是可见的,我们可以方便的查看我们自己定义的状态,也可以在任务启动之前初始化历史数据作为状态的冷启动,极大的丰富了使用的场景。
推荐阅读
Flink 任务实时监控最佳实践 Flink on yarn 实时日志收集最佳实践 Flink 1.14.0 全新的 Kafka Connector Flink 1.14.0 消费 kafka 数据自定义反序列化类 Flink SQL JSON Format 源码解析 Flink on yarn 远程调试 Apache Flink 1.14.4 Release Announcement Flink 实现自定义滑动窗口
如果你觉得文章对你有帮助,麻烦点一下赞和在看吧,你的支持是我创作的最大动力.多谢各位大佬支持。