
Kafka 事务的实现原理

- 前言 -
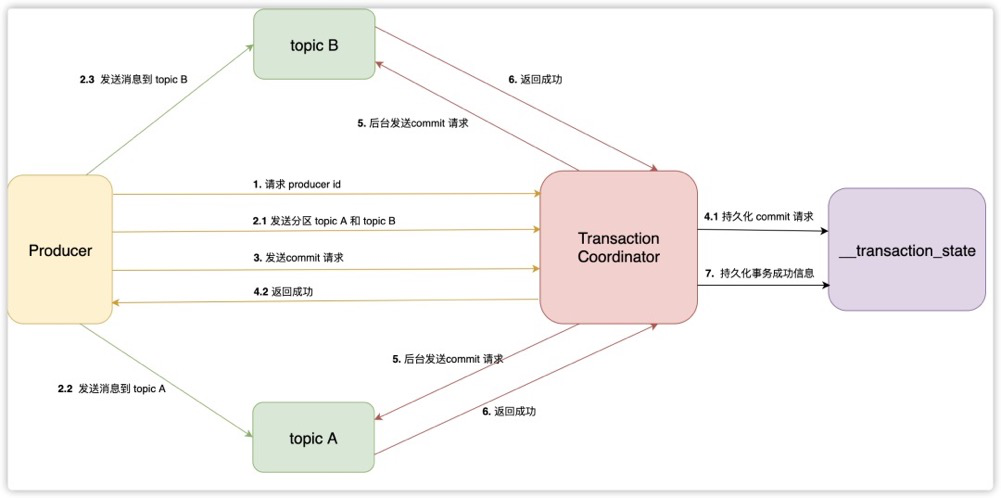
- 事务流程 -
- 寻找 TC 服务地址 -
- 事务初始化 -
- 发送消息 -
- 发送提交请求 -
提交请求持久化
发送事务结果信息给分区
- 客户端原理 -
使用示例:
1 | // 创建 Producer 实例,并且指定 transaction id |
- 运行原理 -
1 | private enum State { |
- 服务端原理 -
1 | class TransactionMetadata( |
- 高可用分析 -
TC 服务
消息持久化
超时处理
源码分析
- 客户端 -
1 | public interface Producer<K, V> extends Closeable { |
1 | public synchronized TransactionalRequestResult initializeTransactions() { |
1 | private class InitProducerIdHandler extends TxnRequestHandler { |
1 | public synchronized void beginTransaction() { |
1 | public class KafkaProducer<K, V> implements Producer<K, V> { |
1 | public class TransactionManager { |
TransactionManager 的 addPartitionsToTransactionHandler 方法,会生成分区上传请求,然后由Sender发送。
1 | public class TransactionManager { |
AddPartitionsToTxnHandler 负责处理响应。
1 | private class AddPartitionsToTxnHandler extends TxnRequestHandler { |
1 | public class TransactionManager { |
AddOffsetsToTxnHandler 类负责处理响应,它的处理逻辑很简单,它收到响应后,会发送 TxnOffsetCommitRequest 请求给 TC 服务。
1 | public synchronized TransactionalRequestResult beginCommit() { |
1 | private synchronized void completeTransaction() { |
- 服务端 -
1 | class TransactionStateManager(...) { |
1 | class TransactionStateManager { |
1 | def handleEndTransaction(transactionalId: String, |
1 | private[transaction] class DelayedTxnMarker(txnMetadata: TransactionMetadata, |
1 | def addTxnMarkersToSend(transactionalId: String, |
作者:zhmin
来源:
zhmin.github.io/2019/05/20/kafka-transaction/

评论