点击上方“机器学习与生成对抗网络”,关注星标
转自:新智元
金秋十月,又到了ICLR截稿的季节!
一篇「Patches are all you need」横空出世。
堪称ICLR 2022的爆款论文,从国外一路火到国内。
509个赞,3269个转发
知乎热搜
这篇标题里不仅有「划掉」还有「表情」的论文,正文只有4页!

https://openreview.net/pdf?id=TVHS5Y4dNvM
此外,作者还特地在文末写了个100多字的小论文表示:「期待更多内容?并没有。我们提出了一个非常简单的架构和观点:patches在卷积架构中很好用。四页的篇幅已经足够了。」

这……莫非又是「xx is all you need」的噱头论文?
这个特立独行的论文在一开篇的时候,作者就发出了灵魂拷问:「ViT的性能是由于更强大的Transformer架构,还是因为使用了patch作为输入表征?」
众所周知,卷积网络架构常年来占据着CV的主流,不过最近ViT(Vision Transformer)架构则在许多任务中的表现出优于经典卷积网络的性能,尤其是在大型数据集上。
然而,Transformer中自注意力层的应用,将导致计算成本将与每张图像的像素数成二次方扩展。因此想要在CV任务中使用Transformer架构,则需要把图像分成多个patch,再将它们线性嵌入 ,最后把Transformer直接应用于patch集合。
在本文中作者提出了一个极其简单的模型:ConvMixer,其结构与ViT和更基本的MLP-Mixer相似,直接以patch作为输入,分离了空间和通道维度的混合,并在整个网络中保持同等大小和分辨率。不同的是,ConvMixer只使用标准的卷积来实现混合步骤。
作者表示,通过结果可以证明ConvMixer在类似的参数量和数据集大小方面优于ViT、MLP-Mixer和部分变种,此外还优于经典的视觉模型,如ResNet。
ConvMixer模型
ConvMixer由一个patch嵌入层和一个简单的完全卷积块的重复应用组成。
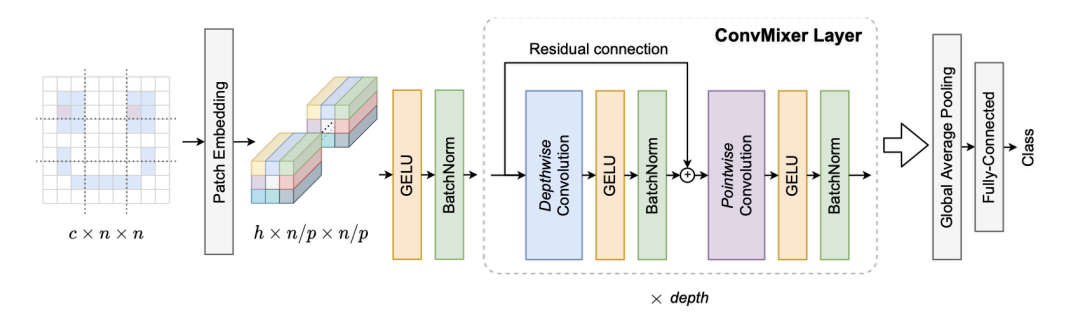
大小为p和维度为h的patch嵌入可以实现输入通道为c、输出通道为h、核大小为p和跨度为p的卷积。
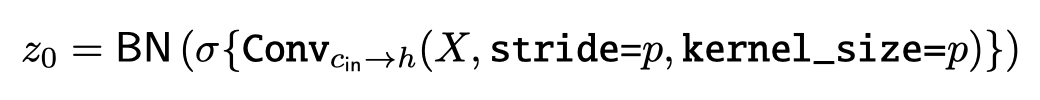
ConvMixer模块包括depthwise卷积(组数等于通道数h的分组卷积)以及pointwise卷积(核大小为1×1)。每个卷积之后都有一个激活函数和激活后的BatchNorm:

在多次应用ConvMixer模块后,执行全局池化可以得到一个大小为h的特征向量,并在之后将其传递给softmax分类器。
ConvMixer的实例化取决于四个参数:
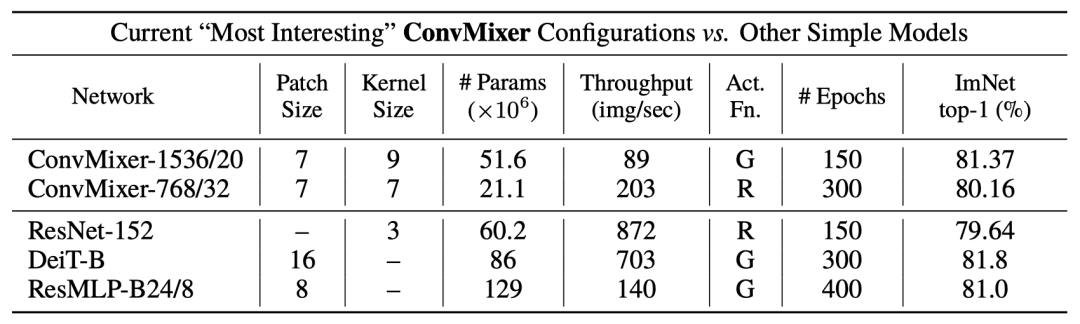
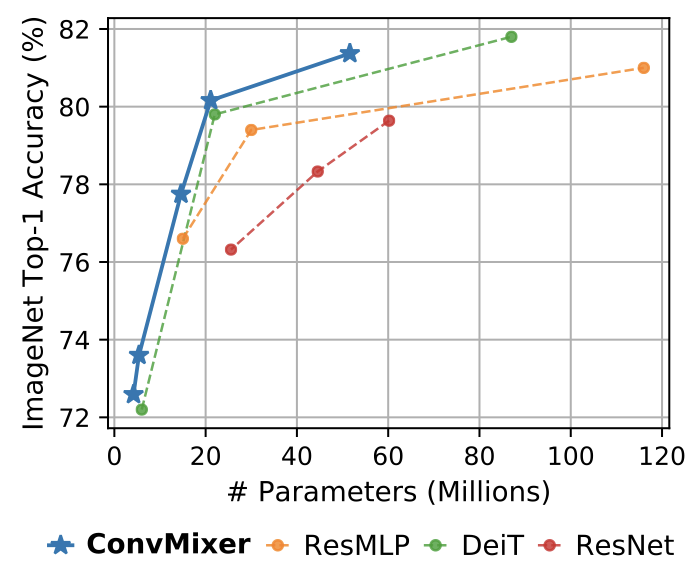
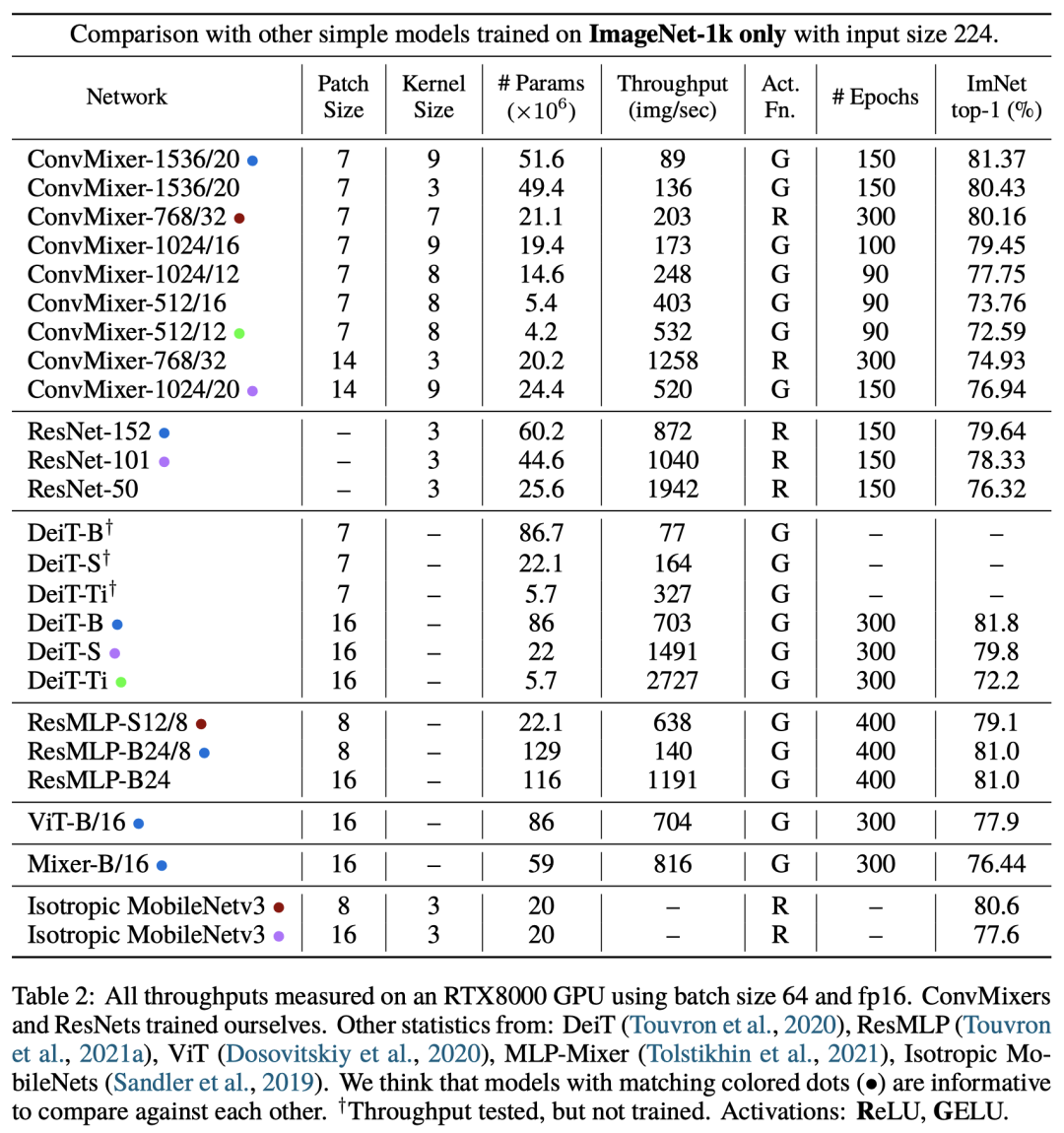
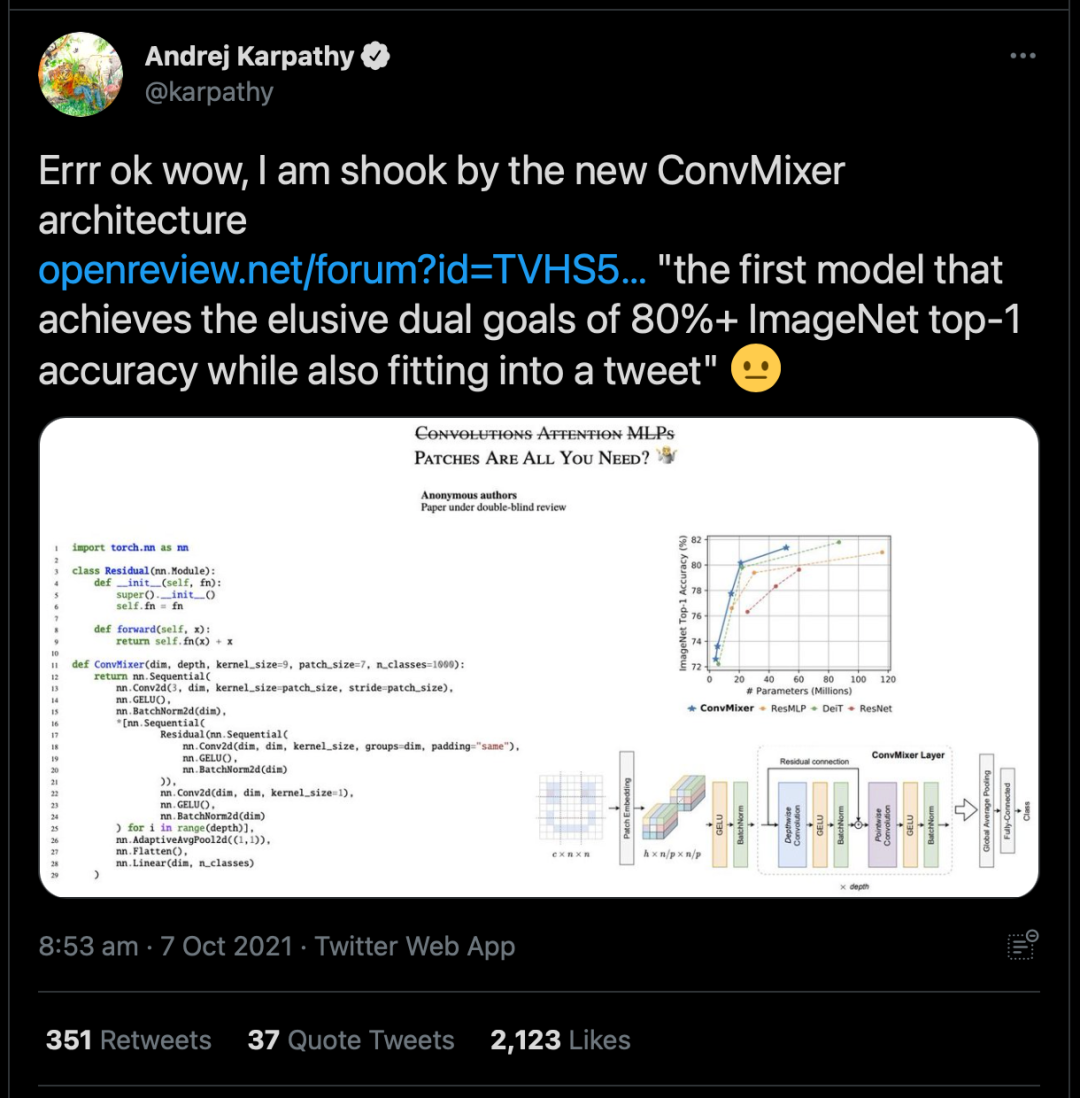
作者将原始输入大小n除以patch大小p作为内部分辨率。此外,ConvMixers支持可变大小的输入。在CIFAR-10上较小规模的实验表明,ConvMixers在只有0.7M参数的情况下达到了96%以上的准确率,证明了卷积归纳偏差的数据有效性。不使用任何预训练或额外数据的情况下,在ImageNet-1k中评估对ConvMixers。将ConvMixer添加到timm框架中,并使用几乎标准的设置进行训练:默认的timm增强、RandAugment、mixup、CutMix、随机删除和梯度标准裁剪。此外,还使用了AdamW优化器和一个简单的triangular学习率时间表。由于算力有限,模型没有在ImageNet上进行超参数调整,而且训练的epochs比竞争对手少。因此,作者表示,论文中提出的准确率可能低估了模型的能力。(是的没看错,原文就是underestimate)结果表明,具有52M参数的ConvMixer-1536/20可以在ImageNet上达到81.4%的最高精确度,具有21M参数的ConvMixer-768/32可以达到80.2%。此外,ConvMixer-768/32使用的参数仅为ResNet-152的三分之一,但其准确度与之类似。在224×224的ImageNet-1k上训练和评估更宽的ConvMixer可以在更少的epochs下就实现收敛,但对内存和计算的要求更加苛刻。当ConvMixer的卷积核更大时,效果也更好。ConvMixer-1536/20在将核大小从k=9减少到k=3时,准确性下降了≈1%。在实验中,拥有更小patch的ConvMixers的性能更好,作者表示这是因为较大的patch需要更深的ConvMixers。ConvMixer-1536/20的性能优于ResNet-152和ResMLP-B24,而且参数要少得多,并且与DeiT-B的性能接近。然而,ConvMixer的推理速度大大低于竞争对手,这可能是由于其较小的patch;超参数的调整和优化可以缩小这一差距。Chinese philosophy is all you need对此,来自华科的网友@小小将认为这篇论文实在是「名不副实」。一位网友疯狂拆穿,认为这篇论文「吹水」得过于明显了。甚至表示:「任何一个ViT、MLP、ResNet模型通过增大输入的patch分辨率,在把计算量提到这么大之后,性能都能比这更好。」@陈小小表示,通篇只比参数量,不比计算量。与同精度的ResNet相比,吞吐量差得离谱。当然了,该论文提到的ConvMixer如此简洁优雅,还是有一队网友轮番夸赞的。@殷卓文表示,这是一篇「漂亮得不讲道理」的论文,堪称完美。结构是常规的结构,不用调参,效果又好,怎能不香呢?此外,也回答了之前一位网友指出的问题:「这篇论文减小patchsize,相当于增大输入token size,与vit等方法是不公平的比较。同时这篇文章的方法实际运行速度慢(throughput)。」特斯拉AI高级总监Andrej Karpathy也赞叹道:「我被新的 ConvMixer 架构震撼了。」对于网上这些争论,@陀飞轮表示,主要是「深度学习的控制变量都不是严格的控制变量」这个问题所造成的。
参考资料:
https://www.zhihu.com/question/492712118
https://openreview.net/pdf?id=TVHS5Y4dNvM
猜您喜欢:
等你着陆!【GAN生成对抗网络】知识星球!
CVPR 2021专题1:GAN的改进
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
CVPR 2021 | 图像转换 今如何?几篇GAN论文
【CVPR 2021】通过GAN提升人脸识别的遗留难题
CVPR 2021生成对抗网络GAN部分论文汇总
经典GAN不得不读:StyleGAN
最新最全20篇!基于 StyleGAN 改进或应用相关论文
超100篇!CVPR 2020最全GAN论文梳理汇总!
附下载 | 《Python进阶》中文版
附下载 | 经典《Think Python》中文版
附下载 | 《Pytorch模型训练实用教程》
附下载 | 最新2020李沐《动手学深度学习》
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
附下载 |《计算机视觉中的数学方法》分享