
超越所有开源编程大模型和GPT-3.5!华为发布150亿参数规模的编程大模型PanGu-Coder2
华为盘古大模型一直是国内大模型领域比较早的先行者,不过由于该模型并不针对个人开放,因此很少有人可以体验到该模型的效果。但是,盘古大模型一直在不断发展。2023年7月27日,华为发布最新的论文,展示了新一代盘古大模型的编程能力。该模型名字为PanGu-Coder2,论文的数据显示该模型目前超越所有开源编程大模型的效果,也超过GPT-3.5,接近GPT-4。

编程大模型再度扩张版图~
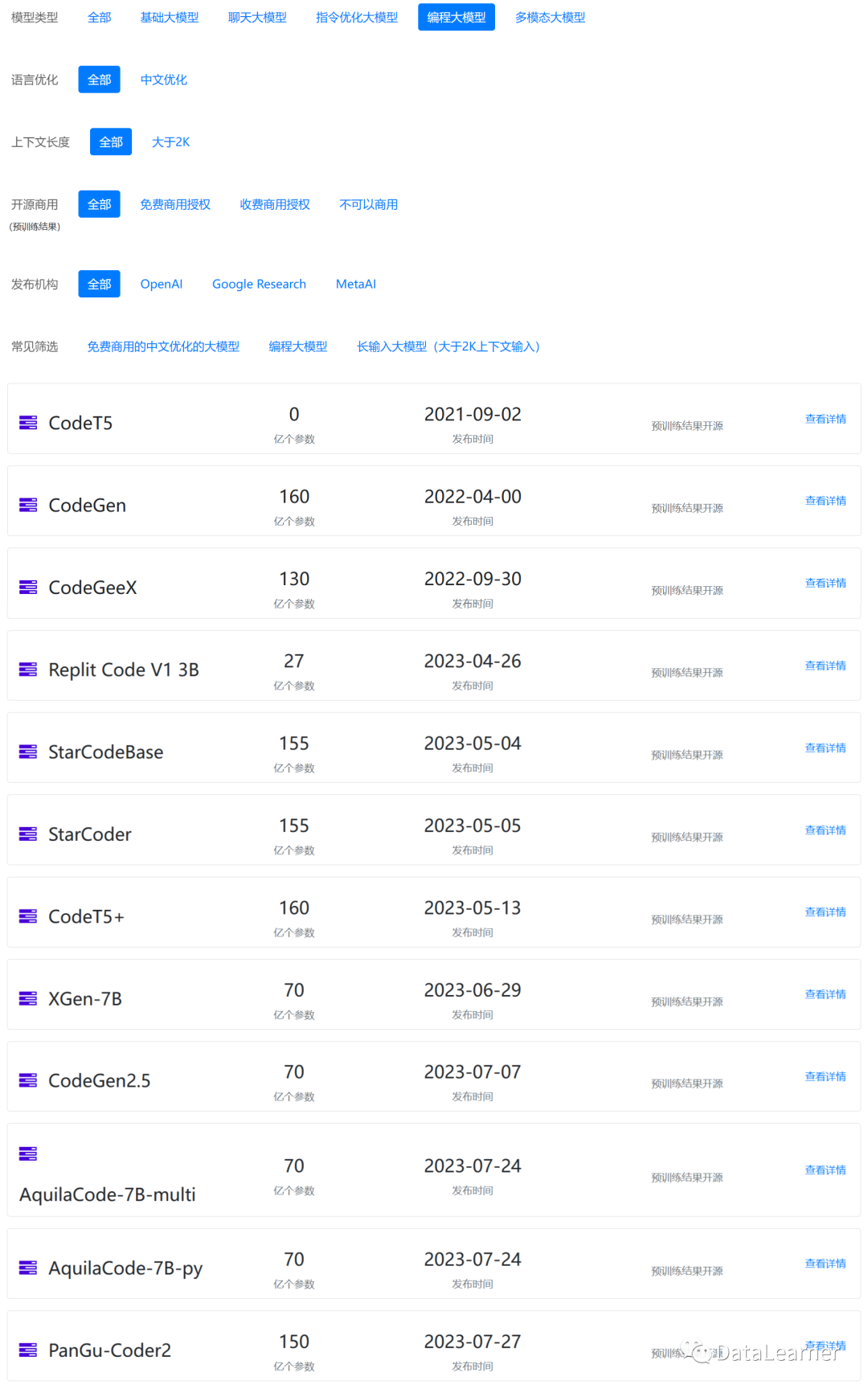
上图来自DataLearner模型信息卡筛选列表:
https://www.datalearner.com/ai-models/pretrained-models?&aiArea=1002&language=-1&contextLength=-1&openSource=-1&publisher=-1
当前编程大模型的问题
强化学习是当前训练编程大模型最常用的方法之一,它可以为模型设定特定的奖励函数以引导大模型可以生成更好的代码。然而现有强化学习方法在代码大型语言模型(LLMs)中有很大的局限性。华为认为现有的基于强化学习的方法通常根据编译器、调试器、执行器和测试用例的反馈信号设计价值/奖励函数,但这导致了三个限制:
直接将测试结果作为奖励提供给基础模型的改进有限。
采用的强化学习算法(如 PPO)实现复杂,且难以在大型语言模型上进行训练。
在训练模型时运行测试是耗时的。
因此,华为提出了 RRTF(RankResponses to align Test&Teacher Feedback)框架,以解决现有基于强化学习的方法的问题,并进一步发掘代码 LLM 的潜力。RRTF 框架是一种新的工作,成功地将自然语言 LLM 对齐技术应用于代码 LLM。与之前的工作(如 CodeRL 和 RLTF)不同,RRTF 框架遵循 RLHF(Reinforcement Learning from Human Feedback)的思想,但使用排名响应作为反馈,而不是奖励模型的绝对值。
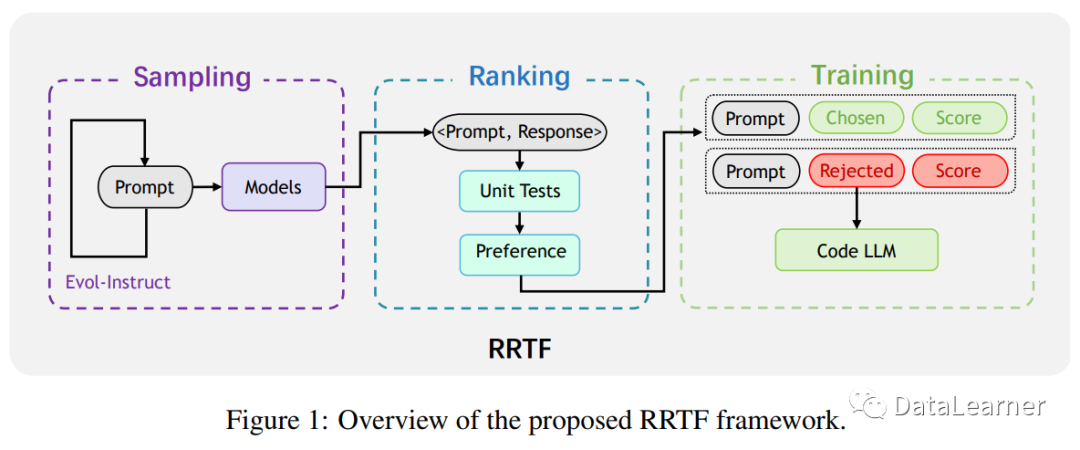
作为概念的证明,华为在 StarCoder 15B 上应用了 RRTF,并训练出PanGu-Coder2。
PanGu-Coder2简介和训练细节
PanGu-Coder2 是一种大型语言模型,专门用于代码生成。它基于RRTF (RankResponses to align Test&Teacher Feedback) 的新框架,该框架结合了多种先进技术,包括指令调整、Evol-Instruct 方法和强化学习。RRTF 的核心思想是通过使用测试信号和人类偏好作为反馈来对响应进行排名,从而引导模型生成更高质量的代码。
在模型架构方面,PanGu-Coder2 是一个基于Decoder的 Transformer,具有 Multi-Query-Attention 和学习的绝对位置嵌入。同时,它使用了 FlashAttention来减少计算和内存使用量,因此模型的最大长度可以扩展到 8192。模型的详细超参数如下:
隐藏层大小:6144
最大长度:8192
注意力头的数量:48
Transformer 隐藏层的数量:40
在训练过程中,PanGu-Coder2 使用了 Evol-Instruct 技术来构建训练语料库,这种技术可以通过深度演化来迭代地从 Alpaca 20K 数据集中获取新的编程问题。通过这些问题,模型可以从不同的模型中采样答案。总的来说,他们收集了一个包含 100K 编程问题及其答案的初始语料库,这些问题和答案被称为指令和解决方案对。此外,他们还对初始语料库进行了数据预处理,并将语料库的大小减少到了 68K。
在训练过程中,PanGu-Coder2 使用了 RRTF 框架,该框架可以根据人类的偏好对来自不同来源的响应进行排名,并通过排名损失函数对模型进行调整。与 RLHF 相比,RRTF 可以有效地将语言模型的输出概率与人类的偏好对齐,只需要在调整期间使用 1-2 个模型,而且在实现、超参数调整和训练方面比 PPO 更简单。
PanGu-Coder2的评估结果以及与清华大学CodeGeeX2等模型对比
说了这么多还是看效果,我们最主要的是看一下HumanEval评价,HumanEval 是 OpenAI 提出的一种评估大型语言模型编程能力的基准测试。这个基准测试包含了 164 个编程问题,这些问题都是由经验丰富的程序员手动编写的,涵盖了各种编程概念,包括数据结构、算法、控制流、字符串处理等。
在 HumanEval 中,模型的任务是生成 Python 代码来解决给定的编程问题。然后,这些生成的代码会被运行并与预期的输出进行比较,以确定代码是否正确。模型的性能是根据其在这些问题上的通过率来评估的,即生成的代码能够成功解决问题的比例。
论文中给出的评估结果如下(HumanEval,这里的k=1表示生成第一份解决方案解决问题的指标)
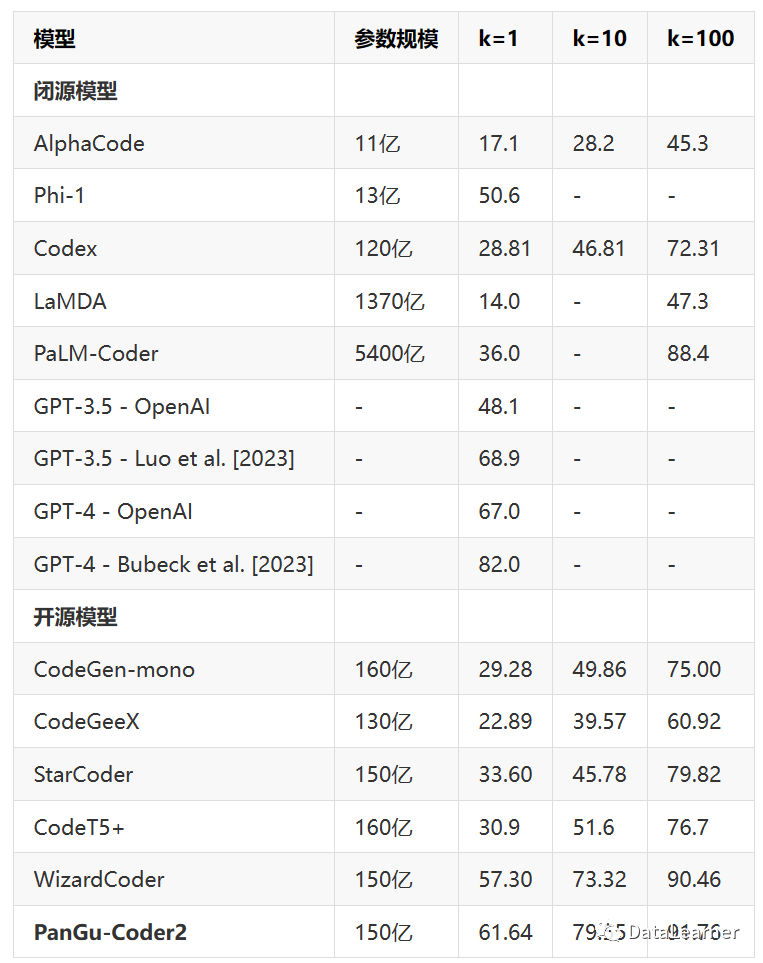
注意,这里像GPT-3.5和GPT-4有两个结果,原因是一个来自OpenAI官方数据,一个是论文的数据。可以看到,目前Pass@ 1的测试最强的是GPT-4 (Bubeck),这是来自于微软的测试结果(论文名: Sparks of Artificial General Intelligence: Early experiments with GPT-4.)。而微软官方测试的GPT-3.5和GPT-4水平则是48.1和67。
PanGu-Coder2得分61.64,开源模型第一,比原模型中,OpenAI官方数据超过GPT-3.5,接近GPT-4。第三方测试中则接近GPT-3.5,低于GPT-4。
再来看一下前几天智谱AI发布的基于ChatGLM2-6B微调的编程大模型CodeGeeX2-6B和北京智源人工智能研究院发布的AquilaCode对比:
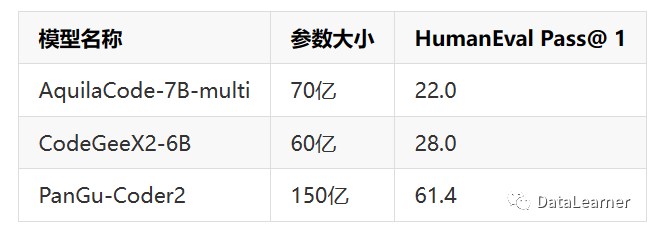
也是远超这2个模型的。
AquilaCode介绍:智源人工智能研究院开源可商用的编程大模型:悟道·天鹰AquilaCode系列,超过清华大学CodeGeeX - https://www.datalearner.com/blog/1051690174323553CodeGeeX2-6B介绍:智谱AI发布第二代CodeGeeX编程大模型:CodeGeeX2-6B,最低6GB显存可运行,基于ChatGLM2-6B微调 - https://www.datalearner.com/blog/1051690265117179
PanGu-Coder2的运行资源要求
论文中也给出了PanGu-Code2推理的资源要求和速度:
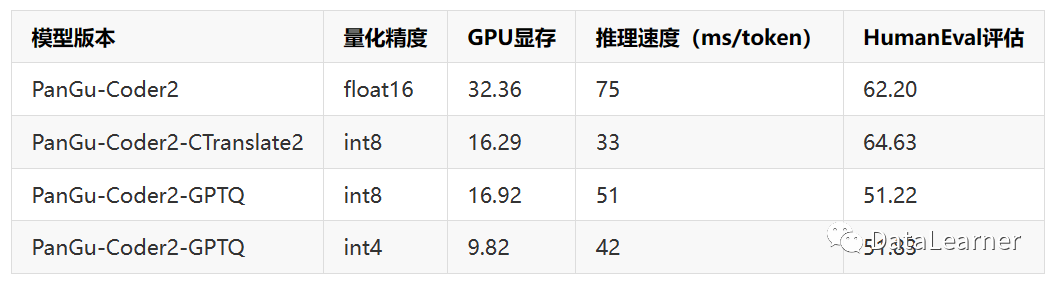
可以看到,完整的PanGu-Coder2模型的显存要求32.36GB,推理速度是每个token要75毫秒,也就是每秒13个tokens左右。而最低的INT4量化版本则只需要10GB显存左右可以运行,速度是每秒23个tokens左右!还是相当吸引人的。
PanGu-Coder2总结
PanGu-Coder2的模型已经在DataLearner模型信息卡更新:https://www.datalearner.com/ai-models/pretrained-models/PanGu-Coder2
不过,这个模型并不是开源的,也没有代码或者预训练结果,非常可惜~
号外!