
150亿!谷歌发布史上最大视觉模型V-MoE,却最有希望减少碳排放?
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近日,土豪Google AI继之前发布的20亿参数的ViT-G/14模型之后,又发布了参数量为150亿的视觉模型V-MoE,这可以称得上迄今为止最大的视觉模型,其在ImageNet上的Top-1 accuracy达到90.35%,这个也超过之前Google提出的Meta Pseudo-Labelling (MPL)(注意这里ViT-G/14模型的训练成本只有MPL的70%左右),但是略低于ViT-G/14模型。
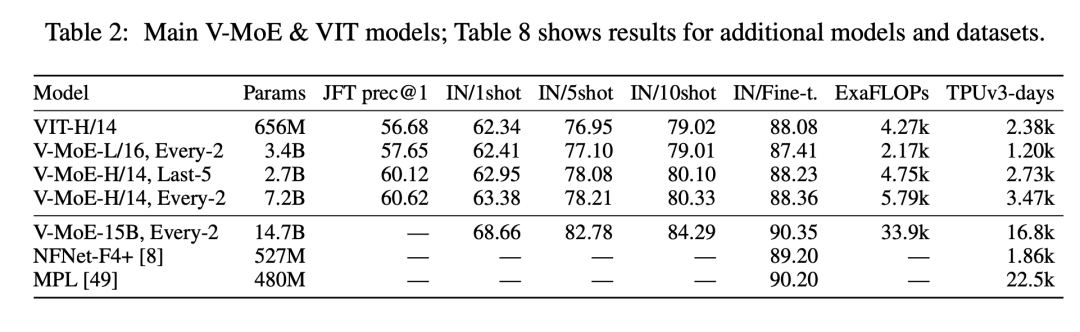
MPL模型是基于半监督和JFT-300M,而ViT-G/14模型是基于ViT和JFT-3B来实现更好的效果。这次Google提出的V-MoE核心设计是Sparse Mixture of Experts,这其实是一个稀疏模型(sparse model),这个也是借鉴了NLP领域已有的成果,即实现视觉领域的稀疏模型V-MoE,其模型结构如下图所示:
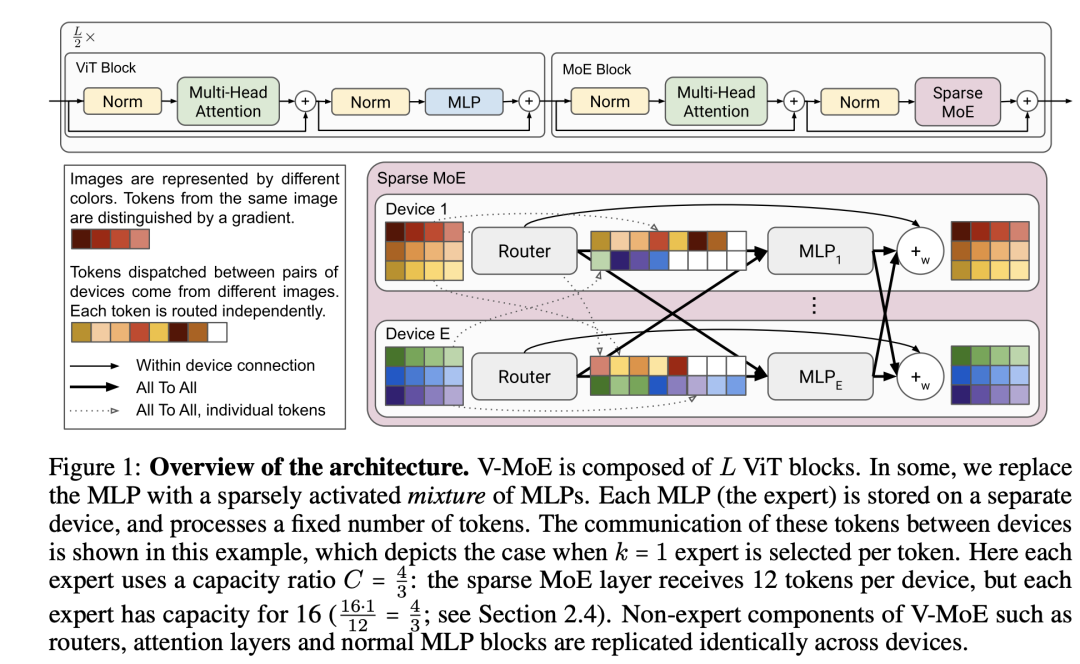
可以看到V-MoE也是在ViT基础上构建的,都包含个同质的ViT模块,这里最大的变动是将transformer模块里面的MLP替换成一些列的MLPs,每个MLP放在一个单独的device上,只负责处理固定数量的tokens(或者说是image patchs),每个MLP可以看成一个expert,替换后的layer这里称为MoE layer。在处理上,每个图像的每个token在每个MoE层只有个expert来负责处理它,图中的,这样其实每个token只不过经过一个MLP的处理。对一个图像来说,虽然V-MoE模型很大,但是只用了V-MoE模型的很小一部分来处理,所以说这是一个稀疏模型。具体地,每个MoE层可以用以下公式表示:
这里的是输入token,特征维度为,而就是第个expert,即一个2层MLP,这里的就是计算各个experts的权重系数(是expert的总数)。所以MoE这样看起来是一种模型集成,但是实际上这里要限制每个token的experts数量为,只需要使只有个权重值非零,其它值全为零即可。这样就是变成了一个选址函数(routing function),具体实现为:
这里的操作指的是只选择前个较大的,其它的权重全置为0,论文中的或者,而对于权重为0的expert其实我们也不需要计算,所以虽然模型参数量很大,但是计算开销并不会太大,当时只增加了Router带来的开销。
对于稀疏模型来说,一个挑战是模型最终有效的可能其中的一小部分expert,或者说大部分tokens只选择了其中几个experts,这会导致稀疏模型近似等价于一个dense模型,稀疏模型的大容量没有利用好,而且计算上也不均衡。那么解决方案就是限制每个expert在训练过程中的处理能力:所能处理的tokens的最大量,这里称为buffer capacity,记为。假定训练过程的图像总数为,每个图像的patchs总数为,那么可以计算容量比(capacity ratio):
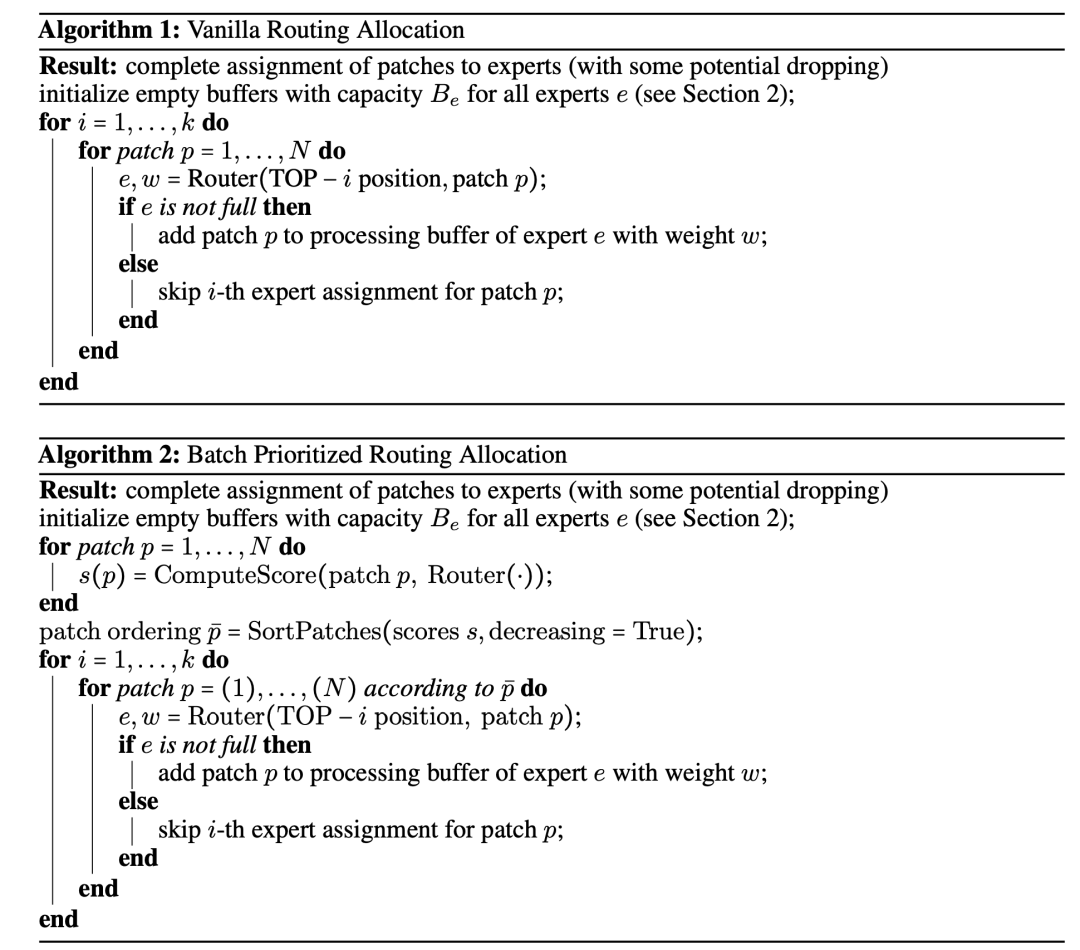
上图中给的实例。当时,这意味着所有experts的容量是用不完的,这个时候会出现前面说的不平衡问题,论文中额外增加了一个辅助loss(load balancing losses)来避免这种问题,在上游训练或者预训练过程中(upstream training),有必要选择大于1的容量以更好地迁移到下游任务中(需要finetune),论文中设定的是。当时,这意味着所有experts的容量是不够的,那么就有一部分token无法被处理,或者说一些token被drop掉了,其实MLP本身就带有残差结构,所以只相当于少了一个MLP的处理,另外时也会减少每个token都不被处理的概率。论文中在下游任务finetune时采用,这个时候有一个问题,就是选择留下哪些tokens来处理,传统的做法是序列地处理每个图像的tokens直到容量用尽,由于图像的tokens顺序是固定的,这对后面的tokens就不太好。论文中提出的方案是Batch Prioritized Routing (BPR),就是先确定各个tokens的重要性,再按这个顺序来处理tokens:
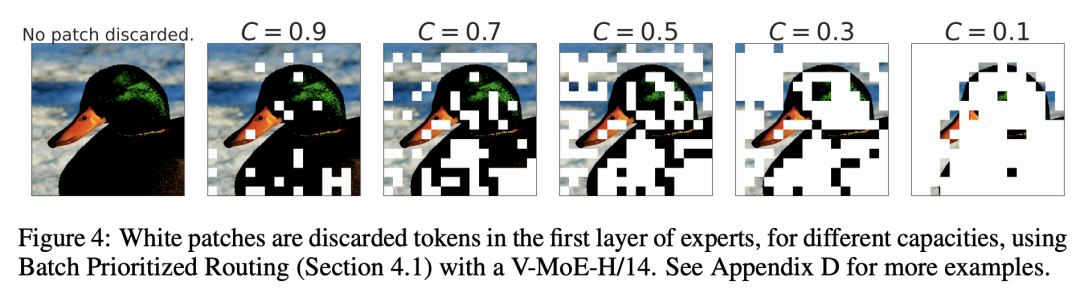
下图是图像的tokens在不同的下在第一个MoE层被drop的情况:
设定较小的那么模型的训练成本就可以降低,比如下图基于BPR的V-MoE-L/32 (k=2)在时在性能上就超过原始的Dense ViT-L/32,而此时的训练所需要的FLOPS,前者只有后者的不到90%。
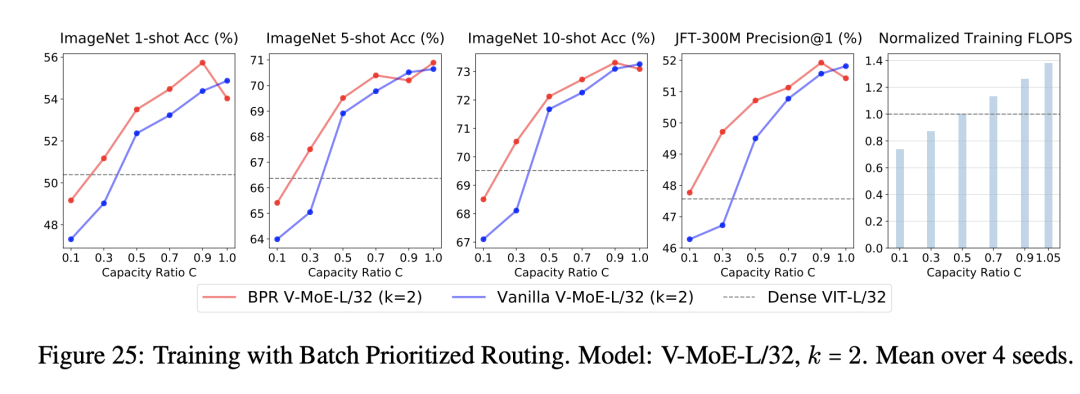
同时inference time也可以减少,如V-MoE-L/16只需要dense VIT-H/14一半的推理时间,但性能前者还稍好于后者:
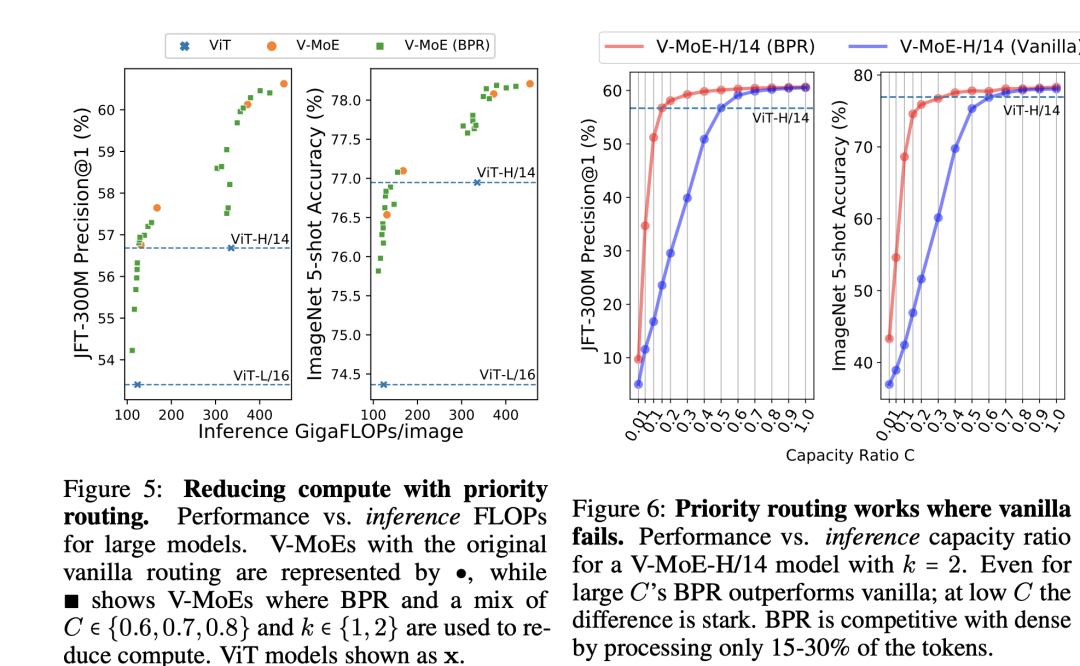
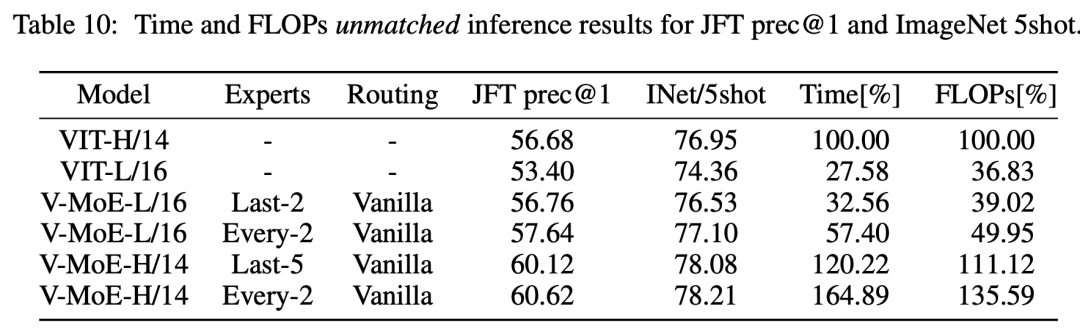
虽然V-MoE参数量更大,但是由于是稀疏的,其实训练和推理的成本反而会更好一点:
This has interesting connotations for recent work in NLP using sparse models; recent analysis shows model sparsity is the most promising way to reduce model CO2 emissions [46] and that 90% of the footprint stems from inference costs.
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
